-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.0 2019-05-15 데이터 최초 개방 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2022-10-17 세부데이터, 데이터통계 항목 내 링크 수정 소개
대화형 음성 인식 성능 개선을 위한 음향 모델용 한국어 자유 발화 음성 데이터 구축 및 2,000여명의 발성 대화 음성 1,000시간을 구축한 자연어 데이터 제공
-
메타데이터 구조표 데이터 영역 한국어 데이터 유형 오디오 , 텍스트 데이터 형식 데이터 출처 라벨링 유형 라벨링 형식 데이터 활용 서비스 데이터 구축년도/
데이터 구축량2018년/1,000시간 -
구축내용
- 대화형 음성인식 성능 개선을 위한 음향모델(Acoustic Modeling)용 한국어 자유발화 음성데이터 구축
- 조용한 환경에서 2,000여명이 발성한 한국어 대화음성 1,000시간 구축
- 두 사람이 다양한 주제(예: 일상, 쇼핑, 정치, 경제, 날씨, 취미 등)로 자유롭게 대화하는 음성을 녹음하고 발성내용을 ERTI전사규칙(예: 간투사, 머뭇거림 등)에 따라 철자전사
- 전사규칙 공유 https://aihub.or.kr/aihubnews/notice/view.do?pageIndex=1&nttSn=9746&currMenu=132&topMenu=103
- 평가 데이터, 실험 하이퍼 파라메터 등에 관한 참고 자료(레퍼런스 페이퍼) :KsponSpeech (Korean Spontaneous Speech Corpus for Automatic Speech Recognition)

[ 한국어 음성 분야 대화 주제 표 예시 ]
법률 데이터 구축내용 표 (구축년도,데이터종류,포함내용,제공방식) 데이터 종류 구축수량 포함 내용 제공 방식 안부 일상 대화 자기소개 날씨 계절 거주지 정보 황사/미세먼지 이성친구 혹서기/혹한기 학교생활 장마/폭설 회사생활 온도 기념일 눈/비/안개 등 쇼핑 의류 취미 사진 전자기기 여행 생활용품 음식(맛집) 악기 등 책 TV 예능 운동 드라마 전시회 영화 공연 연예인 블로그 시사 음악 정치 경제 정치 스포츠 부동산 게임 주식 자동차 전공 전공(이과/문과) -
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.0 2019.05.15 데이터 최초 개방 필요성
- 최근 대화형 AI 서비스의 글로벌 경쟁이 치열함에 따라 국내 산업체 지원을 위한 AI학습용 대화형 자유발화 음성DB 구축 시급
- 구글, 바이두 등 해외 경쟁업체는 수천~수만시간의 대용량 음성데이터를 AI 기술 개발에 활용하고 있으나 국내에서는 수십~백시간 수준의 소규모 데이터 구축으로 한정되어 AI 기술개발에 제약이 되고 있음
- 본 DB 활용을 통해 국가 간 사활을 걸고 있는 AI 분야 대화형 음성인식 기술경쟁 우위 확보 및 新서비스 창출로 글로벌 시장 점유 확대 및 AI비서, 외국어교육, 동시통역 등 AI 기반 음성인식 사용성의 획기적 개선으로 장애인, 다문화가족을 비롯한 일반 국민의 편익 향상이 기대됨
구축내용
- 대화형 음성인식 성능 개선을 위한 음향모델(Acoustic Modeling)용 한국어 자유발화 음성데이터 구축
- 조용한 환경에서 2,000여명이 발성한 한국어 대화음성 1,000시간 구축
- 두 사람이 다양한 주제(예: 일상, 쇼핑, 정치, 경제, 날씨, 취미 등)로 자유롭게 대화하는 음성을 녹음하고 발성내용을 ERTI전사규칙(예: 간투사, 머뭇거림 등)에 따라 철자전사
- 전사규칙 공유 https://aihub.or.kr/aihubnews/notice/view.do?pageIndex=1&nttSn=9746&currMenu=132&topMenu=103
- 평가 데이터, 실험 하이퍼 파라메터 등에 관한 참고 자료(레퍼런스 페이퍼) :KsponSpeech (Korean Spontaneous Speech Corpus for Automatic Speech Recognition)
[ 한국어 음성 분야 대화 주제 표 예시 ]
법률 데이터 구축내용 표 (구축년도,데이터종류,포함내용,제공방식) 데이터 종류 구축수량 포함 내용 제공 방식 안부 일상 대화 자기소개 날씨 계절 거주지 정보 황사/미세먼지 이성친구 혹서기/혹한기 학교생활 장마/폭설 회사생활 온도 기념일 눈/비/안개 등 쇼핑 의류 취미 사진 전자기기 여행 생활용품 음식(맛집) 악기 등 책 TV 예능 운동 드라마 전시회 영화 공연 연예인 블로그 시사 음악 정치 경제 정치 스포츠 부동산 게임 주식 자동차 전공 전공(이과/문과) 데이터 구조
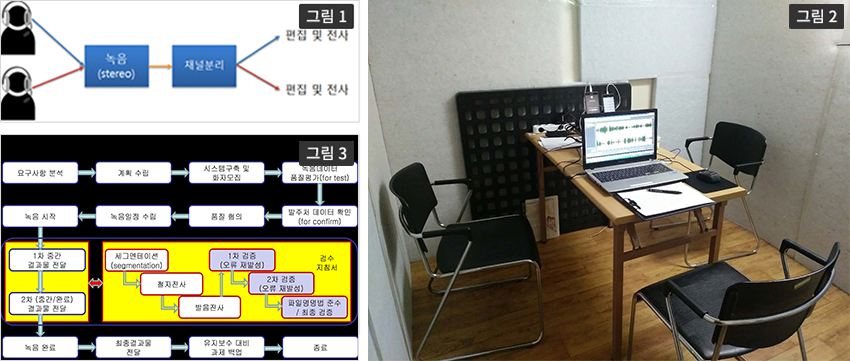
- 발화 단위로 세그멘테이션된 음성파일(포맷: 16kHz/16bits, headerless (little endian) linear PCM)과 전사파일(포맷: EUC-KR)로 구성- [그림 1] 데이터처리, [그림 2] 자유 발화 녹음 장면
- 발화단위는 long pause 단위로, 1개 발화에는 복수 개의 문장으로 구성됨- [그림 3] 음성 검사 프로그램
- 구축DB의 크기는 총 123GB이며, 41개의 폴더에 3GB씩 음성/전사 파일을 할당함
<한국어음성 데이터 분석 이미지 예시>
데이터 활용 예
- 인공지능 기반 대국민 민원서비스(예: 음성 챗봇 기반 민원상담 콜센터, 다국어 자동 자막 방송, 검찰/대법원 속기록 작성) 개선
- AI 비서, 대화로봇, 동시통역, AI 튜터 등 대화형 음성인식 기술 개발
- 금융 및 보험 등 서비스 자동화, 스마트폰 응용서비스, 지능형 홈, IoT 서비스 등 음성기반 인공지능서비스 구현
- 청각장애인을 위한 방송 자동자막화, 신체장애자를 위한 음성명령 등 장애인을 위한 음성인터페이스 개발
- 고령화에 따른 독거노인 대화 서비스, 경찰, 소방관 등 정신노동자 상담 등 감성형 대화 음성지능 서비스
-
데이터셋 구축 담당자
수행기관(주관) : 한국전자통신연구원
데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 김상훈(한국전자통신연구원) 042-860-5141 ksh@etri.re.kr
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기] [공용IRB 심의신청 가이드라인]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 safezone1@aihub.kr 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.