-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.1 2023-11-21 데이터 최종 개방 1.0 2023-07-31 데이터 개방(Beta Version) 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2023-12-27 산출물 전체 공개 소개
실내의 조도차가 존재하는 다양한 주차 공간에서 생기는 여러 객체들의 종류들과 객체 위치들의 데이터를 제공하여 실내 주차공간기반의 다양한 연구를 할 수 있는 데이터 제공
구축목적
영상 내 존재하는 객체를 감지하는 인공지능 알고리즘 개발 - 주차 데이터 수집 전용 차량에 장착된 장치를 통한 측정데이터를 활용한 인공지능 알고리즘 개발 - 실내 주차장의 시설물을 인식하고 동기화된 측정된 데이터를 인공지능 기술로 자동 판별하여 자율 주차 기술 개발 - 센서 데이터 융합을 통합 고차원 데이터를 구축하여 다목적 연구를 수행할 수 있도록 함
-
메타데이터 구조표 데이터 영역 교통물류 데이터 유형 이미지 데이터 형식 JPG/PCD 데이터 출처 직접 수집 라벨링 유형 세그멘테이션, 큐보이드 라벨링 형식 json 데이터 활용 서비스 AI 기반 자동주차 가이드 시스템 개발 데이터 구축년도/
데이터 구축량2022년/객체인식 (2Hz) 원천데이터 162,166장 라벨링데이터 162,166장 위치추정 (10Hz) 원천데이터 89,060장 메타데이터 550개 -
1. 데이터 구축 규모
구분 원천 데이터 라벨링 데이터 주차공간 인식용 데이터 AVM 영상데이터(jpg 포맷) : 80,194장 AVM 영상데이터용 JSON 파일 : 80,194장 및 왼쪽 : 40,097장 왼쪽 : 40,097장 주변사물 인식용 데이터 오른쪽 : 40,097장 오른쪽 : 40,097장 (객체 인식 2Hz) 전방 카메라영상(jpg 포맷) : 40,986장 라이다(pcd 포맷) : 40,986장 전방 카메라 영상 데이터용 총 162,166장 JSON 파일 : 40,986장 라이다 데이터용 JSON 파일 : 40,986장 총 162,166장 위치 확인용 데이터 라이다(pcd 포맷) : 44,530장 (10Hz) 영상(jpg 포맷) : 44,530장 (비식별화) 총 89,060장 메타데이터 객체 인식(2Hz) (txt, shp, shx 포맷) - 시나리오 개수: 60개 1. 시나리오당 calibration 데이터(txt) : 4개 AVM_Left, AVM_Right, Camera, Lidar 총 240개 위치확인(10Hz) - 시나리오 개수: 22개 시나리오 당 메타데이터 구성 calibration 데이터(txt) : 4개 AVM_Left, AVM_Right, Camera, Camera_Lidar map데이터(cpg,dbf,prj,shp,shx) : 20개 4가지 항목, 5개 파일확장자 (기둥, 벽체, 주차공간, 주행경로) csv데이터(csv) : 1개 총 550개 총합 객체인식 (2Hz) : 162,406 162,166장 (162,166장+240개) 위치추정 (10Hz) : 89,610 (89,060장+550개) 총 252,016
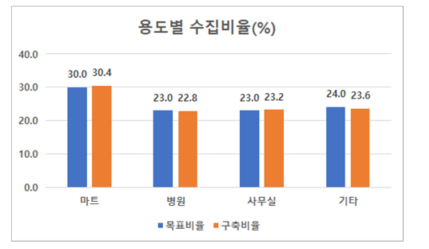
2. 데이터 분포○ 시나리오(장소)별 분포
장소 원천데이터(목표비율) 마트 30.4%(30.0%) 병원 22.9%(23.0%) 사무실 23.2%(23.0%) 기타 23.6%(24.0%)
시간대 원천데이터(목표비율) 혼잡 예상 시간대 32.7%(33.0%) 적정 예상 시간대 33.7%(34.0%) 한가 예상 시간대 33.6%(33.0%) 
○ 클래스 별 분포
Semantic Class 개수 Lidar Class 개수 Undefined Stuff 232,706 Undefined Stuff 1,700 Wall 148,406 Wall 4,482 Driving Area 147,536 Pillar 8,344 Non Driving Area 90,651 Traffic Cone 1,338 Parking Line 118,049 No Parking Sign 314 Parking Area 90,120 Undefined Object 363 No Parking Area 569,806 Vehicle 14,047 Big Notice 53,778 Two-Wheeled Vehicle 147 Pillar 447,889 Stroller 75 Parking Area Number 84,973 Wheelchair 86 Disabled Icon 59,280 Shopping Cart 193 Women Icon 8,515 Human 707 Compact Car Icon 6,988 Speed Bump 18,144 Parking Block 183,632 Billboard 12,607 Toll Bar 3,808 Sign 88,953 No Parking Sign 13,484 Traffic Cone 58,831 Fire Extinguisher 17,015 Undefined Object 12,401 Two-wheeled Vehicle 5,903 Vehicle 496,699 Wheelchair 1,745 Stroller 1,658 Shopping Cart 16,834 Animal 1,569 Human 28,134 -
-
AI 모델 상세 설명서 다운로드
AI 모델 상세 설명서 다운로드 AI 모델 다운로드7) 학습모델 설계 / 개발
[Semantic Segmentation 기반 주차공간 탐지 및 분류 모델]
ㅇ 실내주차장에서 주차공간 인식을 위한 객체를 학습하고, 이를 기반으로 주차공간을 탐지하고 분류학습모델 개발 항목 학습모델 Semantic Segmentation 기반 주차공간 인식 학습모델 목적 Semantic Segmentation 주차공간 인식용 학습데이터 유효성 확인 지표 mIoU(Mean Intersection over Union) 측정 산식 
학습 알고리즘 1. DeepLabV3+: 구글에서 2018년 8월 발표한 주행공간 인식에 검증된 대표적인 Semantic Segmentation 알고리즘. Encoder-Decoder 구조로 설계되었으며 Encoder에서는 이미지에서 특징을 추출하고 압축하며, Decoder에서는 Encoder에서 추출한 특징을 확장하며 segmentation map을 출력함. DeepLabV3+ 알고리즘을 통해 주차 공간을 인식하는 연구가 2020년 ‘A Parking Space Detection Algorithm Based on Semantic Segmentation’ 논문에서 발표되었으며 해당 연구의 성능을 지표로 삼고 성능을 비교하는데 사용 가능함 ![[DeepLabV3+ 학습 알고리즘 개념도]](/web-nas/aihub21/files/editor/2023/07/67d78818770341de94218793c09f89f0.png)
2. STDC: 2021년 CVPR에 발표된 STDC 모델 기반 Bilateral segmentation network 알고리즘으로 주차공간을 인식하는 연구가 진행됨. 기존 Semantic Segmentation 기법들은 inference 속도를 위해 low level detail을 포기하거나, high accuracy를 위해 inference 속도를 포기하였는데 해당 알고리즘은 low level detail과 inference 속도를 모두 충족시키는 real-time Semantic Segmentation 알고리즘임. NVIDIA GeForce GTX1080 Ti에서 input 크기 2048 X 1024를 이용해 156 FPS의 속도로 inference를 달성했으며, Cityscape test에서 mIoU를 72.6%를 달성함. PAS(Parking Assist System)을 수행하는 차량 제어기에 AI 딥러닝 학습 모델을 탑재하기 위해서는 경량화된 AI 학습 모델이 필요하며 주차 공간 인식 실시간성 성능은 아주 중요한 요소인데, STDC는 경량화된 알고리즘이며 객체 인식 성능도 준수하므로 주차 공간 인식 Semantic Segmentation 알고리즘으로 적합하다고 판단하여 선정함. ![[STDC 학습 알고리즘 개념도]](/web-nas/aihub21/files/editor/2023/07/ba00e25020bc4adeb0a86c87f6610c19.png)
DeepLabV3: batch 12, epoch 300, SGD, CrossEntropyLoss 학습 조건 STDC: batch 64, epoch 300, SGD, CrossEntropyLoss • 학습 데이터셋: JPG 파일 형식 • 평가 데이터셋: JPG AI모델 사용 이미지 수량(비율) 전체 구축 데이터 대비 - Training Data: 64,000개(80%) 모델에 적용되는 비율 - Validation Data: 8,000개(10%) - Test Data: 8,000개(10%) 대상 클래스 제한사항 • Parking Area • No Parking Area • Disabled Icon • Women Icon • Compact Car Icon [객체 인식, 위치 인식]
ㅇ 학습 환경 구축![[객체인식 & 위치 추정 환경 구성]](/web-nas/aihub21/files/editor/2023/07/21bd1b4e9743411abd7fb1c17fcdf939.png)
ㅇ 모델 학습 및 테스트
![[폴더 구성]](/web-nas/aihub21/files/editor/2023/07/3ea0810edcf64a269116918199c3a840.png)
ㅇ 모델 테스트
- 객체 인식 모델
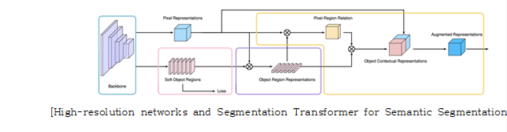
: Semantic segmentation 관련 SOTA 논문 및 방법 중 하나
: Object contextual 정보를 사용하여 Semantic segmentation의 성능을 높임.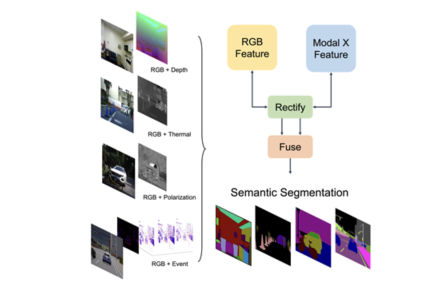
: Semantic segmentation 관련 SOTA 논문 및 방법 중 하나
: RGB 뿐만 아니라, 추가 데이터 (ex: Depth) 를 사용하여 semantic segmentation 의 성능을 높임
- HDL Graph SLAM
![[HDL Graph SLAM 구조]](/web-nas/aihub21/files/editor/2023/07/ec684564676d4a2aa69fd60fbe499dcc.png)
: LiDAR 정보를 이용한 SLAM 방법 중 하나
: 3D LiDAR 정보 및 IMU 를 사용하여 graph SLAM을 비교적 간편하고 안정적이게 수행 가능하도록 함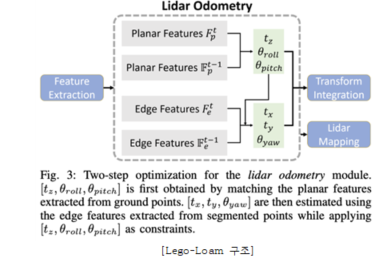
: LiDAR 정보를 이용한 SLAM 방법 중 하나
: 3D LiDAR 만을 사용하여 feature based SLAM을 비교적 간편하고 안정적이게 수행 가능하도록 함 -
데이터 성능 점수
측정값 (%)기준값 (%)데이터 성능 지표
데이터 성능 지표 번호 측정항목 AI TASK 학습모델 지표명 기준값 점수 측정값 점수 1 위치 확인 성능 Object Detection HDL SLAM, Cartographer ATE 0.5 단위없음 0.28 단위없음 2 이미지 기반 객체 인식 성능 (시멘틱 세그멘테이션) Object Detection HRNET-OCR mIoU 73 % 73.35 % 3 주차 공간영역 탐지 성능 (시멘틱 세그멘테이션) Object Detection DeepLab V3, STDC mIoU 65 % 71.98 % 4 이미지+라이다 기반 객체 인식 성능 (시멘틱 세그멘테이션) Object Detection CMX mIoU 73 % 73.53 %
※ 데이터 성능 지표가 여러 개일 경우 각 항목을 클릭하면 해당 지표의 값이 그래프에 표기됩니다.
※ AI모델 평가 지표에 따라 측정값의 범위, 판단 기준이 달라질 수 있습니다. (ex. 오류율의 경우, 낮을수록 좋은 성능을 내는 것으로 평가됩니다)
-
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드○데이터 구성 및 포맷
과제 데이터 포맷 비고 실내자율 주차공간 인식용 데이터 이미지파일(JPG) 주차데이터 주변사물 인식용 데이터 포인트 클라우드(PCD) 위치확인용 데이터 json 메타 데이터 csv, txt, jpg, yaml ○ 라벨링 데이터 구성
1) semantic segmentationNo 항목명 타입 필수 설명 범위 비고 1 data_key string y 원본 데이터 이름 2 objects array y 객체의 정보 2-1 class_name string y class의 이름 2-2 annotation array y 어노테이션 라벨링 타입 2-3 properties object 어노테이션이 생성된 프레임번호 2-3-1 property_name string 속성값의 이름 2-3-2 option_name string 속성 옵션의 이름 2-3-3 annotation array 어노테이션의 정보 3 meta object y 추가 정보 3-1 location string y 장소 3-2 date_time string y 일시 3-3-1 width number y 가로 사이즈 3-3-2 height number y 세로 사이즈 3-3 size string y 이미지 사이즈 3-4 congestion string y 혼잡도 3) 위치추정 데이터
아래의 데이터는 위치 추정(확인)에 사용되는 데이터 라벨임No 항목명 타입 필수 설명 범위 비고 1 TIME string y 수집시간 2 EASTING string y 자율 주행체 X 좌표 3 NORTHING string y 자율 주행체 Y 좌표 4 HEIGHT string y 자율 주행체 Z 좌표 5 ROLL string y roll 값 6 PITCH string y pitch 값 7 HEADING string y Yaw 값 8 GT_X string Ground truth X 좌표 9 GT_Y string Ground truth Y 좌표 10 GT_Z string Ground truth Z 좌표 11 GT_ROLL string Ground truth roll 값 12 GT_PITCH string Ground truth pitch 값 13 GT_HEADING string Ground truth Yaw 값 14 CAMERA string y image 데이터 저장 경로 15 AVM_LEFT string y 왼쪽 AVM 데이터 저장 경로 16 AVM_RIGHT string y 오른쪽 AVM 데이터 저장 경로 17 LIDAR string y lidar 데이터 저장 경로 18 REFINE_AVM string AVM 정제 여부 19 REFINE_camera string 카메라 정제여부 20 GT string Gorund Truth 데이터 여부 y로 변경 가능 • 원천 데이터
전면 카메라 • 라벨 데이터


AVM 카메라


[LiDAR 이미지]
• 원천 데이터 • 라벨 데이터


-
데이터셋 구축 담당자
수행기관(주관) : 강원대학교
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 박홍성 033-250-6346 hspark@kangwon.ac.kr 데이터 구축 총괄 수행기관(참여)
수행기관(참여) 기관명 담당업무 ㈜ 지오앤 데이터 수집 / 정제 ㈜슈퍼브에이아이 데이터 가공 강원대학교 데이터 검수 한성대학교 데이터 검수 데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 박홍성 033-250-6346 hspark@kangwon.ac.kr
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 safezone1@aihub.kr 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.