-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.2 2023-11-15 데이터 최종 개방 1.1 2023-07-24 원천데이터 및 라벨링데이터 수정 1.0 2023-04-30 데이터 개방 (Beta Version) 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2024-04-01 산출물 전체 공개 소개
본 데이터는 가정집의 전력데이터와 유형조사데이터로 이루어져 있으며, 이 둘을 활용해 유형(구성원 수, 벌이형태, 주거형태, 주거면적, 지역)별 전력데이터를 학습 및 분석하여 전력 IT 산업에서 두루 사용할 수 있음.
구축목적
본 데이터는 전력IT발전, 전력효율 증가, 탄소저감을 위한 연구 목적으로 구축되었으며, 전력요금제 변화, 최적 요금제 선정, 전력 패턴 변화에 따른 안전 감지 등에 활용 가능.
-
메타데이터 구조표 데이터 영역 재난안전환경 데이터 유형 텍스트 데이터 형식 csv 데이터 출처 한국전력, 아파트 관리사무소, 기상청 라벨링 유형 - 라벨링 형식 csv 데이터 활용 서비스 전력데이터 사용패턴 시각화 데이터 구축년도/
데이터 구축량2022년/전력데이터 4,200개, 조사데이터 4,200개, 날씨데이터 5개 -
데이터명 분류 총 구축 파일 총 구축 항목 전력소비패턴 데이터 라벨링데이터 3,800개 532,000개 (가정메타데이터) 라벨링데이터 400개 8,000개 (기업메타데이터) 원천데이터 5개 963,644개 (날씨데이터) 원천데이터 4,200개 186,588,000개 (전력데이터) 합계 8,405개 188,091,644개 품질특성 항목명 결과값 다양성 통계 수집 대상별 분포 구분 수량(건) 비율 가구(가정) 3800 90.48% 기업(상가) 400 9.52% 합계 4,200 100% 근무자 수 분포 구분 수량(건) 비율 1~30인 339 84.75% 31~50인 35 8.75% 50인 초과 26 6.50% 합계 400 100% 산업 종류별 분포 구분 수량(건) 비율 농/임/어업 26 6.50% 숙박/음식점 93 23.25% 제조업 94 23.50% 도/소매업 187 46.75% 합계 400 100% 다양성 요건 구성원 수별 분포 구분 수량(건) 비율 1인 792 20.84% 2~3인 1,968 51.79% 4인 이상 1,040 27.37% 합계 3,800 100% 맞벌이 여부별 분포 구분 수량(건) 비율 외벌이 1,351 35.55% 맞벌이 1,357 35.71% 노령/상주/무직 1,092 28.74% 합계 3,800 100% 주거 형태별 분포 구분 수량(건) 비율 단독주택 1,306 34.37% 아파트 1,996 52.53% 빌라 498 13.11% 합계 3,800 100% 주거 면적별 분포 구분 수량(건) 비율 80m² 이하 1,701 44.76% 116m² 이하 1,885 49.61% 116m² 초과 214 5.63% 합계 3,800 100% 지역별 분포 구분 수량(건) 비율 순천 1,420 37.37% 여수 1,024 26.95% 목포 604 15.89% 광양 441 11.61% 나주 311 8.18% 합계 3,800 100% -
-
AI 모델 상세 설명서 다운로드
AI 모델 상세 설명서 다운로드 AI 모델 다운로드1. AI 모델
Temporal Fusion Transformer
부재 : 해석 가능한 시계열 예측
● 최첨단 시계열 모델의 고려해야 할 사항:
1. 모델은 단일 또는 다차원 시퀀스에 적용되어야 한다.
2. 모델은 여러 시계열을 설명할 수 있어야 한다.
- 여러 시계열은 Quantile, mean 등을 의미한다.
- 여러개의 target을 의미하는 것은 아니다.
3. 모델은 시간적 데이터 외에도 미래 알려지지 않은 과거 정보도 사용할 수 있어야 한다.
- 대기오염 수준을 예측한다면 현재 알려진 온습도를 사용할 수 있어야 한다.
- 아마존의 deepAR, ARIMA 등은 이러한 제약을 가지고 있다.
4. 시간이 아닌 여러 도시의 일기 예보 등의 외부정적 변수도 고려한다.
- 고려할 도시가 정적 변수이다.
5. 적응력이 높은 모델이어야 한다.
- 노이즈가 많은 복잡도 높은 경우 뿐 아니라,
- 단순한 계절성을 갖는 경우도 처리할 수 있어야 한다.
6. 다단계 예측 기능도 필수이다.
- 재귀적 예측을 제공하여 좀 더 먼 미래를 예측할 수 있다.
- 하지만 먼 미래는 항상 변동성이 높다.
7. 목표 변수에 대한 점 추정 뿐 아니라, 변동성도 출력할 수 있어야 한다.
8. 사용하기 쉽고 프로덕션 환경에서 쉽게 배포할 수 있어야 한다.
9. 설명 가능성이 이제 프로덕션 환경에서 최우선이다.
● TFT 입력
TFT는 뛰어난 성능과 해석 가능성에 최적화된 어텐션 기반 심층 신경망이다.
TFT의 특징을 보면:
1. TFT의 3가지 유형의 변수들이 있다.
- 미래에 알려진 입력이 있는 시간 데이터
- 현재까지만 알려진 시간 데이터
- 시불변 외생 범주형, 정적 변수
2. 이종 시계열: 여러 분포의 시계열에 대한 학습을 지원
- 특정 이벤트 특성에 초점을 맞추는 로컬 처리
- 모든 시계열의 집합적 특성을 포착하는 글로벌 처리
3. 다중 수평 예측: 분위수 손실 함수을 이용하여 예측 구간을 출력
4. 해석 가능성: self attention을 가지는 transformer 기반
- 중요도에 대한 추가 통찰을 제공하는 Multi-head 구조
- MRRNN도 성능이 우수하지만, 해석 가능성은 없다.
주어진 타임스텝( t )
룩백 윈도우(k)
최대 룩어헤드 윈도우( T=τmax )
time period i∈[t−k,⋯,t+τmax] 에 대해 모델 입력은: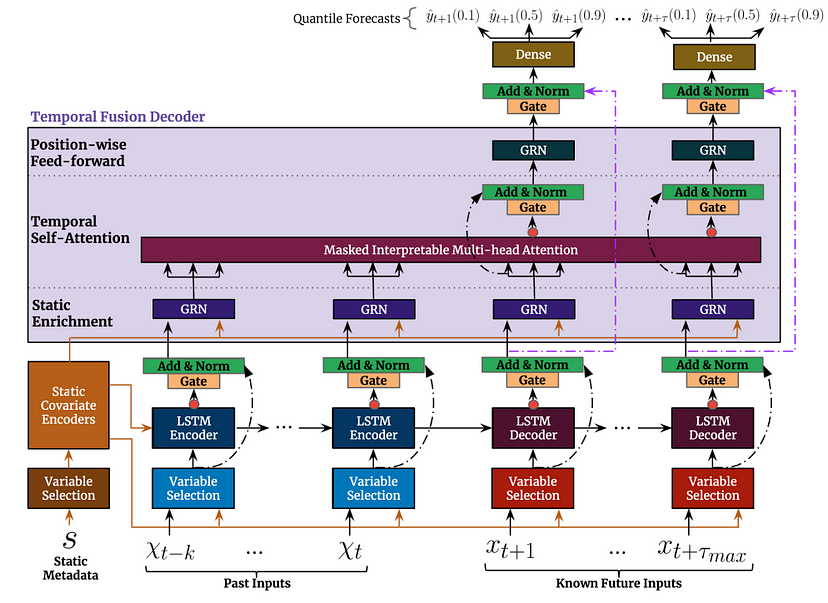
1. 관측된 과거 입력: xi,i∈[t−k,⋯,t]
2. 알려진 미래 입력: xi,i∈[t+1,⋯,t+τmax]
3. 정적 공변량: s
4. 알려진 과거 타겟: 관측된 과거 입력에 포함됨
5. 예측할 미래 타겟: yi,i∈[t+1,⋯,t+τmax]● TFT 구성요소
1. GRN
TFT가 제안한 Gated Residual Network(GRN)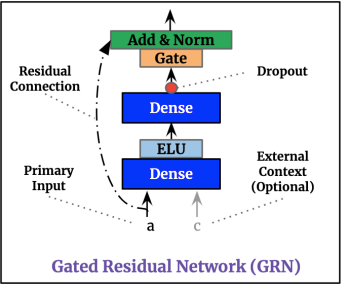
2개의 Dense와 2개의 활성화함수(ELU, GLU)를 가지고 있다.
- GLU는 다음 예측을 위해 가장 중요한 변수를 선택하는 용도
- ELU와 GLU 모두 모델의 단순성과 복잡성을 네트웍이 이해하도록 도와줌
- 입력 피처와 정족 공변량과의 교호작용이 가능하도록 한다.
마지막으로 Add&Norm으로 residual connection과 Layer Normalization을 수행한다.
- residual connection은 필요하다면 입력의 복잡한 변환을 무시하도록 한다.
- Layer Normalization은 Add에 따른 입력 분포의 변동을 일정하게 유지해준다.2. VSN
Variable Selection Network(VSN)는 이름이 의미하듯 변수 선택 메커니즘을 제공한다.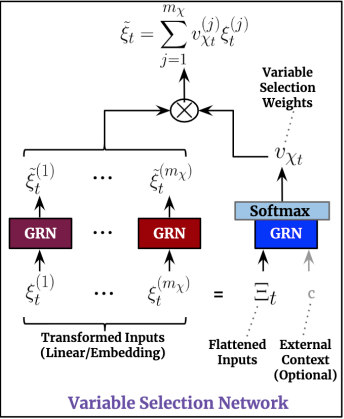
TFT는 3가지 입력이 있고, 각 입력들 중에 통찰력이 있는 입력과 그렇지 않은 것을 분별할 필요가 있습니다.
- 이를 위해 3가지의 서로 다른 VSN 인스턴스를 갖는다.
- 다만 정적 변수에 대한 VSN은 외부 컨텍스트 벡터가 없다.
- 변수 변환시 범주형은 Embedding을 연속형은 dmodel 차원의 선형변환을 한다.
- GRN 위에 Softmax를 얻혀서 Vraiable Selection Weights를 생성한다.3. SCE
Static Covariant Encoders(SCE)는 정적 공변량 S에 대한 변수선택 ξS 에 개별적인 GRN 인코더 4개를 이용하여 서로 다른 context vectors( cs,ce,cc,ch )를 만든다.
ch=GRNch(ξS)
- cs : 변수 선택을 위한 입력 context로 사용된다.
- cc,ch : LSTM 인코더의 (hidden)state와 (memory)cell의 초기값으로 사용된다.
- ce : Temporal Fusion Decoder의 정적 입력 context로 사용된다.4. LSTM 인코더 디코더
정적 공변량에 기반해 초기화된 메모리 셀과 히든 상태로 부터 시간에 따른 순차적인 context 변환을 출력한다.
인코더의 최종 context는 다시 디코더의 LSTM 초기값으로 입력된다.5. 멀티헤드 어텐션
Transformer의 멀티헤드 세프 어텐션과 같지만 하나가 다른 점이 있다.
TFT의 주요 목적중 하나가 해석 가능성인데:
- 이전과 동일하게 서로 Value에 대한 가중합으로 attention value를 구하면:
A(Q,K)HmMultiHead(Q,K,V)=Softmax(Q⋅VTdmodel−−−−−√)=Attention(Q⋅WmQ,K⋅WmK,V⋅WmV)=H⋅WH=[H1,⋯,HM]⋅WH
- 즉, 각 헤드의 Value 마다 서로 다른 가중치를 가지면, 해석이 어렵다.
- 해석 가능한 멀티 헤드 어텐션은 단일한 Value에 대해 다양한 시간 축에서의 가중치의 앙상블의 형태로 처리한다.
InterpretMultiHead(Q,K,V)H~InterpretMultiHead(Q,K,V)H~=H~⋅WH=[1M∑m=1MA(Q⋅WmQ,K⋅WmK)]∗V⋅WV=H~⋅WH=1M∑m=1MAttention(Q⋅WmQ,K⋅WmK,V⋅WV)6. Temporal Fusion Decoder
여러 층으로 구성되어 최종 출력을 위한 피처를 생성한다.1) seq2seq
지역성 강화를 위해 LSTM 기반의 인코더-디코더 구조로 seq2seq 모델을 구성한다.
시계열 데이터에서는 주위 값들 사이의 연관성을 통해 중요도가 결정된다.
이를 위해 local context를 뽑아내는 것은 어텐션 기반 모델의 성능을 향상시킨다.
- 컨볼루션에서 단일 필터로 모든 셀을 통과시켜 지역적 패턴을 추출하는 것과 유사
- 우리는 알려진 과거 데이터와 알려진 미래 데이터 간에 타겟값의 유무에 따른 차이가 존재한다.
- 이를 해결할 수 있는 것이 입력 볼륨을 만들어 LSTM에 넣어주는 것이다.
- 단일한 입력볼륨은 VSN이 제공해준다.
- 인코더와 디코더 간에 단일한 LSTM을 넣어주어 시간적 local context를 뽑는다.2) static enrichment layer
정적 공변량의 영향력이 상당한 경우가 있기 때문에:
- static enrichment 층에서 static 메타데이터에 의한 시간 영향도를 강화한다.
- 이를 위해 각 time step t에서 각 sequence i에 대해 GRN을 수행한다.
θ(t,i)=GRNθ(ψ~(t,i),ce)
3) temporal self-attention
위에서 설명한 멀티헤드 어텐션
B(t)=InterpretMultiHead(Θ(t),Θ(t),Θ(t))
4) position-wise Feed-Foward Neural Network
Transformer의 FFNN과 동일하다.7. Quantile outputs
아래와 같은 분위수 회귀를 수행합니다.
y^(q,t,τ)=B(t,τ)⋅Wq+bq
분위수 회귀에 대한 loss 함수는 다음과 같이 정의된다.
Quantile Loss(y,y^,q)=[q−I(y−y^>0)](y^−y)- 낮은 분위수(10백분율)나 높은 분위수(90백분율)에서 더 높은 손실을 준다.
- 낮은 분위수(q ~ 0)에서 실제 분위수보다 더 작은값을 예측하면 손실이 더 커지고
- 높은 분위수(q ~ 1)에서 실제 분위수보다 더 큰값을 예측하면 손실이 더 커진다.
Temporal Fusion Transformer 구현 은 q ∈ [0.1, 0.5, 0.9]에 걸쳐 합산된 분위수 손실을 최소화하여 훈련된다:
- 그 외에도 MSE, MAPE, SMAPE 등을 손실함수로 사용할 수도 있다.5.2 학습 모델 개발
● 파이썬 구현
3.1 tensorflow 코드
저자는 재현성을 위한 tensorflow 1.x 기반의 소스를 github에 올려두었다.
https://github.com/google-research/google-research/tree/master/tft재현성을 확인하긴 위해 3가지 데이터를 제공한다.
- 전기 부하 도표 데이터 (UCI)
https://archive.ics.uci.edu/ml/datasets/ElectricityLoadDiagrams20112014#
- PEM-SF 트래픽 데이터 (UCI)
https://archive.ics.uci.edu/ml/datasets/PEMS-SF
- Favorita 식료품 판매 (Kaggle)
https://www.kaggle.com/datasets/azzabiala/corporacin-favorita-grocery-sales-forecasting각 데이터 세트에 사용되는 구성/초매개변수에 대한 자세한 내용은 원본 문서 또는 github에서 확인할 수 있다.
원 소스를 tensorflow 2.x로 구현한 코드도 있다.
https://github.com/greatwhiz/tft_tf2위 소스를 이용한 실습은 관련 블로그*의 내용을 참고한다.
*https://towardsdatascience.com/temporal-fusion-transformer-googles-model-for-interpretable-time-series-forecasting-5aa17beb6213.2 pytorch
pytorch lightning에서 구현되어 있다. 관련 자습서*를 참고하시고, 아래와 같은 방법으로 conda 프롬프트로 환경설정합니다.
*https://pytorch-forecasting.readthedocs.io/en/latest/tutorials/stallion.html
conda create -n py39 python=3.9 ipykernel
conda activate py39
conda install jupyter scipy pandas matplotlib seaborn plotly scikit-learn
conda install -n base nb_conda_kernels
ipython kernel install --user --name=py39
conda install pytorch==1.11.0 torchvision==0.12.0 torchaudio==0.11.0 cudatoolkit=11.3 -c pytorch
pip install tensorflow-gpu==2.10
pip install pytorch_lightning==1.6.4
pip install pytorch_forecasting
설치가 완료된 이후에는 아래 그림과 같이 설치 여부를 확인합니다.다양한 집단에서의 전력소모 예측
참고:
https://towardsdatascience.com/temporal-fusion-transformer-googles-model-for-interpretable-time-series-forecasting-5aa17beb621아이디어:
num별 1일 단위의 누적 target을 예측하도록 한다.
- 각 time step별로 동일한 가중치를 부여하는 경우
비즈니스 상으로 1일 단위의 총 전력소모가 중요하다 판단하면:
- 누적 target을 예측하되
- 24시간 단위로 가중치를 range(1, 25)로 부여한다.
- 가중치 부여방법에 대해서는 study 필요.
타겟을 정수화 하여,loss를 Poisson 또는 Tweedie로
- target의 평균과 표준편차가 유사한 값을 가지므로 Poisson도 괜챦다.
참고: Poisson vs Tweedie
예측값을 반올림하여 MAE, SMAPE, MAPE를 계산한다.
다변량 회귀가 아닌 다변량 분류모델로 수행
누적 target을 예측할 때 가장 좋은 결과를 얻었다.2. 활용 방안
데이터 명 전라남도 지역 전력소비패턴 데이터 학습 모델 전력소모예측 모델 모델 Temporal Fusion Transformer 성능 지표 전력소모 예측 성능 MAPE 5% 이하 개발 내용 가정의 전력소비패턴을 학습하여 날씨예보에 따른 전력소비량을 예측 응용서비스 유형별 전력소비패턴 시각화 서비스 유형별 전력요금 효율 분석 및 추천 서비스 ㅇ 전력관련 인공지능 산업 발전 활용
- 지역내 분산된 전력 소비 데이터를 다양한 모델별로 확보함으로써 에너지
데이터를 기반으로한 인공지능 전력 관리 산업 발전 기여
- 에너지 데이터 확보를 통한 ICT 기반 전력관리 종합 지원 플랫폼 활용
- 사용자 중심의 효율적인 전력 활용 모델 제시
- VPP, DR, +DR, P2P 등 다양한 전력거래 활용 수익 모델 창출
- 인공지능 기반 전력 관리 서비스 개선ㅇ 미래 전력망 대응 모델 개발
- 미래 에너지 부분은 프로슈머 형태로 진화가 가능성이 크므로 이를 대비한
전력 관리 모델 활용 가능
- 미래 전력망의 기본이되는 신재생에너지기반의 마이크로 그리드는 반드시
발전/소비 예측으로 계통의 불확실성을 줄여야 하며 이를 위해서 인공지능
기반의 전력소비 발전 매칭으로 낭비되는 신재생에너지 자원을 줄일 수 있음
- 국가적인 차원에서 보면 신재생에너지의 간헐성을 위한 ‘국민DR’ 및 +DR
등의 활용을 통한 효율적인 전력 체계 확보를 위한 기초 데이터를 활용 가능
- 인공지능 기반의 미래 전력망 설계 기초 데이터 활용② 향후 계획
ㅇ전력/에너지 효율 관리 시스템 관련 신산업 활용
- 다양한 전력거래 모델 적용을 통한 BM 발굴 및 전력거래 산업창출
- 스타트업등 전력 신산업 참영를 위한 학습 데이터 제공
- 에너지 핵심 기업 양성 등 중소 에너지·IT 기업 제공
- 전력 분야 데이터 확충으로 다양한 소규모 전력 관련 사업 창출 기여
ㅇVPP, 국민 DR, RE100 등 에너지 산업 분야 활용
- 스마트 에너지 관리 플랫폼 구축 활용 지원으로 인공지능 기반 국가 전력망
효율 관리 사용
- 전력 수요관리를 강화하고자 하는 정부의 정책 수단에 부합 사업 활용
- 에너지 저감 기반 지역 주민 소득 증대 활용으로, 현재 사회적 문제로 크게
대두 되고 있는 에너지 및 전기 관련 비용 저감 기회 제공
ㅇ (고도화 사업) 광역권 전력 데이터 에너지 관리 모델 개발
- 기존 전남권에서 벗어난, 광역권 전력 데이터를 관리하여, 지역단위
사업에서 벗어난 전국 단위 에너지 관리 사업 개발
- 에너지 소비량 데이터, 주거형태, 지역, 업종, 난방 등 전력에서 확대한
다양한 에너지 소비 데이터의 분석을 통한 에너지 저감 산업 발굴을 위한
기초 데이터 제공
ㅇ 인공지능 서비스 융합 산업 생태계로 확산
- 미래 인공지능 기술에 대한 전력부분 접목과 나아가 에너지 기술까지 활용
확대
- 다양한 분야에서의 데이터 생산, 유통, 활용의 융합을 통해 데이터 가치
활성화 방안 제시 -
데이터 성능 점수
측정값 (%)기준값 (%)데이터 성능 지표
데이터 성능 지표 번호 측정항목 AI TASK 학습모델 지표명 기준값 점수 측정값 점수 1 전력 소모 예측 성능 Prediction Temport Fusion Transformer MAPE 5 % 4.99 %
※ 데이터 성능 지표가 여러 개일 경우 각 항목을 클릭하면 해당 지표의 값이 그래프에 표기됩니다.
※ AI모델 평가 지표에 따라 측정값의 범위, 판단 기준이 달라질 수 있습니다. (ex. 오류율의 경우, 낮을수록 좋은 성능을 내는 것으로 평가됩니다)
-
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드분류 속성명 속성설명 Type 필수여부 데이터 내용 labeling Data Info type_info memberID 고객번호 string 필수 0 memberNo 구성원 수 number 필수 1: 1인가구 2: 2~3인 가구 3: 4인 이상 jobType 근무형태 number 필수 1: 외벌이 2: 맞벌이 3: 노령(상주) houseType 집 유형 number 필수 1: 단독주택 2: 아파트 3: 빌라 houseArea 집 면적 number 필수 1: 80m²(24평) 이하 2: 116m²(35평) 이하 3: 116m²(35평) 초과 location 위치 number 필수 1: 순천시 2: 목포시 3: 여수시 4: 광양시 5: 나주시 covidEffect 재택 유무 boolean 필수 1: 재택근무 2: 온라인 학습 3: 아니오 covidPeriod 재택 기간 number 필수 day indusKind 산업 종류 number 필수 1: 농,임,어업 2: 숙박,음식점업 3: 제조업 4: 도,소매업 workNo 직원 수 number 필수 1: 1~30인 2: 30~50인 3: 50인 이상 workHour 근무 시간 number 필수 1: 주간 2: 야간 3: 주,야간 pwr_data memberID 고객번호 number 필수 0 mrdDt 측정날짜 datetime 필수 2022-03-22T14:00:00.000Z pwrQrt 전력량 number 필수 0 wht_info location 지역코드 number 필수 1: 순천시 2: 목포시 3: 여수시 4: 광양시 5: 나주시 forecastDtm 예보시간 datetime 필수 2022-03-23 15:00 rainy 강우량 number 필수 0 temp 온도 number 필수 0 humidity 습도 number 필수 0 windSpeed 바람 number 필수 1 appliance_info knd 제품종류 string 필수 ABC modelNm 모델명 string 필수 ABC modelNo 모델번호 string 필수 ABC00000 weekdayUseYN 평일사용시간 number 필수 1 holidayUseYN 휴일사용시간 number 필수 1 Learning Data info FileName 데이터 파일명 string 필수 00000000_powerInfo FileExtensiom 확장자 string 필수 csv path 파일 경로 string 필수 /path member ( 고객정보 ) memberId 고객번호 number 필수 0 memberNo 가족 구성원 수 number 필수 1: 1인가구 2: 2~3인 가구 3: 4인 이상 jobType 직업유형 number 필수 1: 외벌이 2: 맞벌이 3: 노령(상주) houseType 집 유형 number 필수 1: 단독주택 2: 아파트 3: 빌라 houseArea 집 면적 number 필수 1: 80m²(24평) 이하 2: 116m²(35평) 이하 3: 116m²(35평) 초과 location 위치 number 필수 1: 순천시 2: 목포시 3: 여수시 4: 광양시 5: 나주시 covidEffect 재택 유무 boolean 필수 1: 재택근무 2: 온라인 학습 3: 아니오 covidPeriod 재택 기간 number 필수 day indusKind 산업 종류 number 필수 1: 농,임,어업 2: 숙박,음식점업 3: 제조업 4: 도,소매업 workNo 직원 수 number 필수 1: 1~30인 2: 30~50인 3: 50인 이상 workHour 근무 시간 number 필수 1: 주간 2: 야간 3: 주,야간 weather(날씨정보) foreCastDt 예보일자 dateTime 필수 20 forecastDtm 예보시간 datetime 필수 YYYY-MM-DD hh:00 rainy 강우량 number 필수 1 humidity 습도 number 필수 1 windSpeed 바람 number 필수 1 Temperature 온도 number 필수 1 power(전력데이터 정보) mrDt 측정시기 datetime 필수 YYYY-MM-DD hh:00 pwrQty 전력량 number 필수 1 appliances(가전제품 정보) knd 제품종류 string 필수 “acc”, “computer”, ..., “airFlyer” weekdayUseYN 평일사용시간 number 필수 [1,1,...,0] holidayUseYN 휴일사용시간 number 필수 [1,1,...,1] 실제 데이터 예시
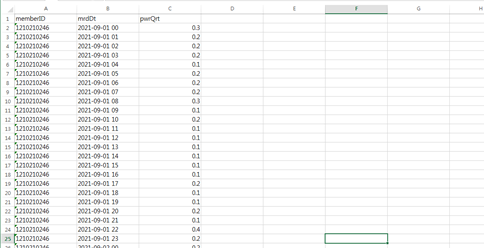
<전력데이터>
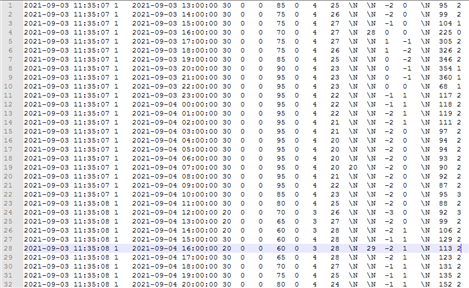
<날씨데이터>

<메타데이터>
-
데이터셋 구축 담당자
수행기관(주관) : ㈜아이티맨
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 홍승표 070-7599-0495 hongspace@itman.co.kr 아파트 데이터 수집 및 AI모델 제작 수행기관(참여)
수행기관(참여) 기관명 담당업무 전남대학교 산학협력단 데이터 검수, 정제 ㈜크라우드웍스 가정집 데이터 수집 한국전기산업진흥회 에너지밸리기업개발원 기업 데이터 수집 데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 홍승표 070-7599-0495 hongspace@itman.co.kr
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 safezone1@aihub.kr 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.