-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.1 2024-01-17 데이터 최종 개방 1.0 2023-04-30 데이터 개방(Beta Version) 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2024-03-15 최종산출물 수정 AI모델 2024-02-27 산출물 전체 공개 소개
센서 데이터를 기반으로 CFD 해석을 진행하여 결과 이미지와 가공된 데이터 셋을 통해 빌딩풍 위험 분석 데이터를 구축함.
구축목적
본 과제의 목적은 지역의 빌딩풍 위험을 분석할 수 있는 학습용 데이터를 구축하는데 목적을 둠.
-
메타데이터 구조표 데이터 영역 재난안전환경 데이터 유형 이미지 데이터 형식 csv, png 데이터 출처 데이터 수집 라벨링 유형 태그(이미지) 라벨링 형식 png, json 데이터 활용 서비스 AI 학습 데이터 구축년도/
데이터 구축량2022년/CFD 이미지, 라벨링 데이터 (706,400개) -
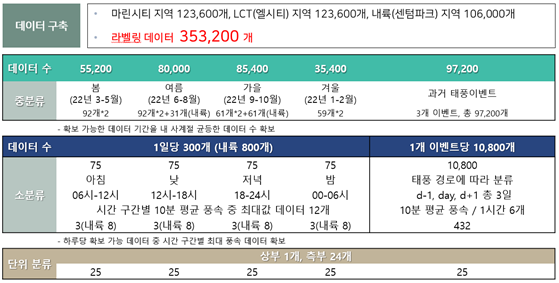
<그림3, 데이터 구축 구성>
□ CFD 데이터 353,200개, 라벨링 데이터 353,200개 총 706,400개 구축 (8.82GB) -
-
AI 모델 상세 설명서 다운로드
AI 모델 상세 설명서 다운로드 AI 모델 다운로드□ 모델 개발 요약표
데이터명 AI모델 모델 성능 지표 응용서비스(예시) 빌딩풍 재해위험도 분석 데이터 ConvLSTM RMSE 풍향 및 풍속을 예측하여 침수, 화재 등 재난 탐지 서비스에 활용 □ 학습 알고리즘 : ConvLSTM
● 입력-상태 및 상태-상태 전환 모두에서 컨볼루션구조를 갖는 FC-LSTM의 확장 버전
● 다중 ConvLSTM 레이어를 쌓고 인코딩 예측 구조를 형성함으로써 현재 강수 문제 뿐만 아니라 보다 일반적인 시공간 시퀀스 예측 문제에 대한 네트워크 모델을 구축 가능
● 시공간 시퀀스 예측 문제를 위해 인코딩 네트워크와 예측 네트워크 두개의 네트워크를 사용
● 예측 타겟은 입력과 같은 차원을 가지므로 예측 네트워크의 모든 상태를 연결하고 1×1 컨볼루션 레이어에 공급하여 최종 예측을 생성\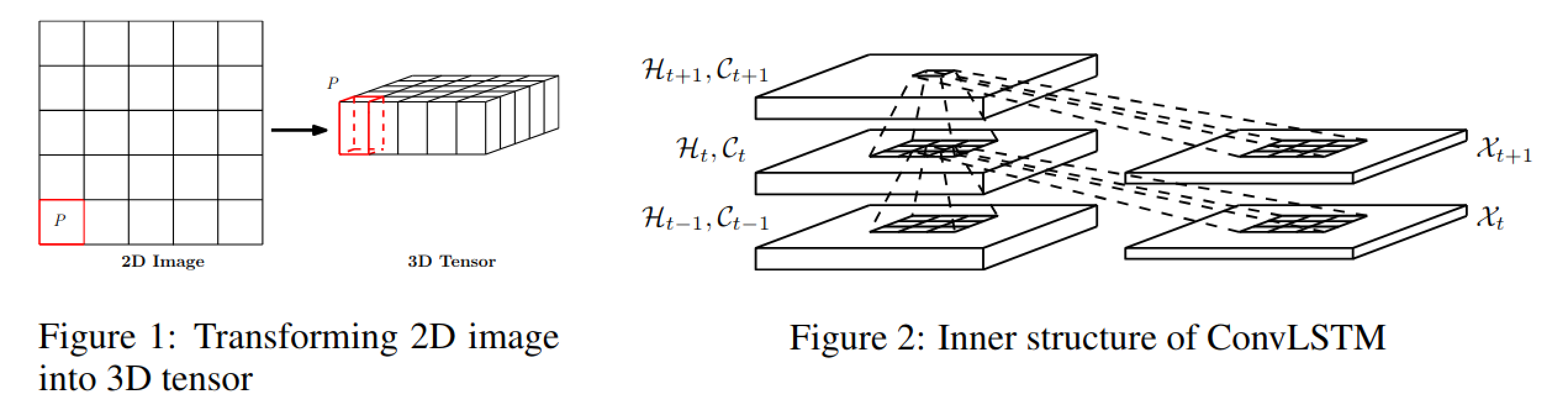
<그림4, ConvLSTM 내부구조>
□ 학습 모델 개발 및 학습 결과
● 모델 명칭 : Convolutional LSTM for wind
● 모델 버전 : 1.0
● 모델 task : PyTorch 기반 Jupyter notebook + C++
● 모델 특징 : 빌딩풍 시계열 데이터로부터 특정 시점의 바람의 풍향과 풍속을 예측하고 높이와 지역적 정보를 활용하여 일정 시간 이후의 예측된 이미지를 표출함
● 학습 과정 : 흑백 모델인 ConvLSTM을 사용하기 위해, 이미지 데이터들을 흑백 이미지로 변환하는 작업을 거침
● 결과 표출 방법 : 전체 데이터에서 랜덤하게 10~20%를 선택하여 목록을 생성하고, 일정 시간 이후의 예측값을 이미지로 표출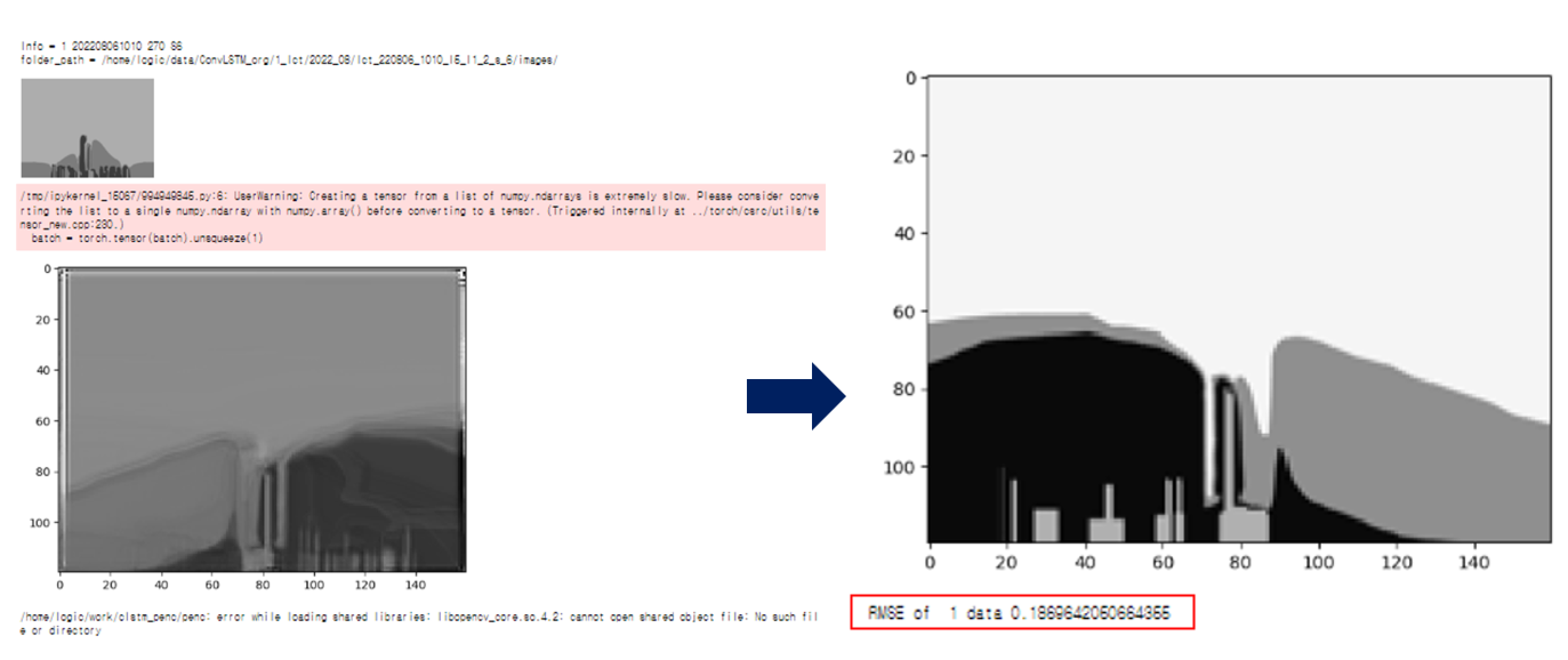
<그림5, 결과값 확인>
□ 서비스 활용 시나리오
- 빌딩풍에 대한 시민 알림 서비스 및 피해 대응을 위한 대책수립 기초 자료로 활용
- 대상 지역의 위험 요소를 분석하거나 관련 기상 재해에 관련한 연구 및 사업에 기초 사례로 활용
- 대상에 대한 현장관리, 안전관리, 구조물의 유지관리 등 손상 탐지, 방재 성능 평가 등에 활용
- 모듈화하여 다양한 경우에 반복적 사용이 가능하도록 개발
- 구글딥마인드의 나우캐스팅을 통한 날씨 예측 부분 등의 사례와 유사한 빌딩풍의 예측 자료로 활용 -
데이터 성능 점수
측정값 (%)기준값 (%)데이터 성능 지표
데이터 성능 지표 번호 측정항목 AI TASK 학습모델 지표명 기준값 점수 측정값 점수 1 빌딩풍 예측 정확성 Prediction ConvLSTM RMSE 1.42 단위없음 0.19 단위없음
※ 데이터 성능 지표가 여러 개일 경우 각 항목을 클릭하면 해당 지표의 값이 그래프에 표기됩니다.
※ AI모델 평가 지표에 따라 측정값의 범위, 판단 기준이 달라질 수 있습니다. (ex. 오류율의 경우, 낮을수록 좋은 성능을 내는 것으로 평가됩니다)
-
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드□ 데이터 설계
● 데이터 클래스별 데이터셋 생성 설계
● 측정값과 기상청 데이터 정보 매칭
● AI 학습용 데이터셋 생성을 위해 CFD 가공데이터 및 데이터 정의 (json) 파일로 구성된 데이터셋
□ 원시데이터 수집● 지역별 데이터 수집을 위해 기상청에서 제공하는 ‘자동 기상 관측 장비 표준 규격’에 따라 고정형 기상 관측계 모니터링 시스템 구축 (LCT 5지점, 마린시티 5지점, 센텀시티 2지점, 2022년 01월 01일~ 2022년 10월 31일)
- 현장 상황을 고려하여 가로등. 전신주에 4~8m 높이로 설치
● - 고정형 기상 관측계를 통해 0.25초 간격으로 풍향, 풍속, 기온, 기압, 습도 데이터 관측
● 각 지점의 데이터는 자동 기상 관측장비 표준 규격에 따른 고정형 기상 관측계를 통해 수집되며 일정 기간을 주기로 배터리와 데이터 저장공간 (SD 카드)를 교체함.
● 1초당 4번의 데이터 취득 (0.25초 간격)을 통해 하루 (86,400초)동안 345,600 열의 데이터 획득
□ 원시데이터 정제● 지역풍향, 풍속, 기온, 기압, 습도에 대하여 1초당 4번 측정되고, 수집된 원시데이터는 10분 간격으로 10분 평균값 및 10분 최대값 산출
● 수집된 원시데이터를 필요에 따라 선별하고 중복파일 제거, 센서 데이터 취합 등과 같이 정제 작업을 수행
● 정제 작업이 완료된 데이터를 정제 기준에 따라 적합 여부를 판별하고 부적합 데이터 폐기
● 각 데이터 수집 위치에서 누락된 데이터가 발생하지 않았는지 또는 센서 오류로 인해 측정값에 문제가 없는지 확인
● 1초당 4개의 데이터를 10분 평균으로 변환 시 하루에 144행의 데이터 취득
● 구축계획서를 통해 자체적으로 정의한 센서 데이터 카테고리 별 목표 수량 균일성 준수 여부 확인
□ 원천데이터 가공
● 가공 프로세스는 크게 Geometry, Meshing, Setup&Solve, Post-processing 총 4단계로 나뉘며 가공 도구는 CFD 해석 소프트웨어인 ‘Ansys Fluent’ 소프트 웨어를 사용함.
● CFD 시뮬레이션을 통해 빌딩풍 연구대상지인 엘시티, 마린시티, 센텀시티의 전범위 풍속 분포를 이미지 파일로 도출함.
● Geometry 단계에서 풍향을 8방위(N, NE, E, SE, S, SW, W, NW)로 나누어 해석을 진행함
● Post-processing 과정에서 0°부터 359°까지 15° 간격으로 이미지 파일을 도출하여 다양한 풍향 CASE에서의 가공데이터를 확보함.
● 하부는 15°각도에 걸쳐 총 24개, Top에서는 1개로 총 25개의 데이터가 구축
● 기상청 보퍼트 풍력 계급표 기준 수치가 포함된 라벨값과 다양한 각도의 속성값으로 가공
● 가공된 이미지 파일은 보퍼트 풍력 계급에 따라 색상이 나눠짐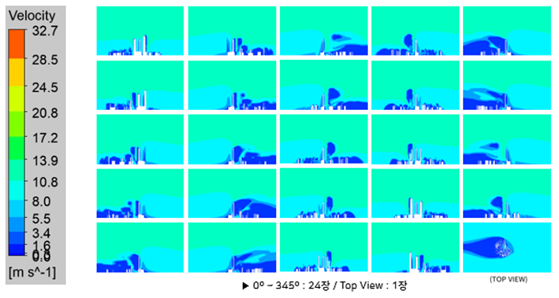
<그림1, CFD를 통한 25방향 이미지 데이터 구축>

<그림2, Json 형식>
-
데이터셋 구축 담당자
수행기관(주관) : 부산대학교 산학협력단
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 권순철 051-510-7629 sckwon@pusan.ac.kr 총괄, 수집, 가공 수행기관(참여)
수행기관(참여) 기관명 담당업무 비자림 데이터 가공 꿈꾸는세상 정제 및 가공 ㈜이시스비젼 품질관리, AI모델 개발
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기] [공용IRB 심의신청 가이드라인]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 safezone1@aihub.kr 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.