다국어 통·번역 낭독체 데이터
- 분야한국어
- 유형 오디오
-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.1 2023-12-22 데이터 최종 개방 1.0 2023-07-25 데이터 개방(Beta Version) 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2024-06-13 데이터설명서, 담당자 정보 수정 2023-12-22 산출물 전체 공개 2023-12-01 구축업체정보 수정 2023-11-24 구축업체정보 수정 소개
한국어-영어, 한국어-다국어 통번역 훈련 및 평가 등에 활용하기 위한 한국어-영어, 일본어, 스페인어 AI 학습용 데이터 구축
구축목적
학술 분야에서 음성인식 및 합성기의 객관적인 성능평가를 위한 한국어 버전 LibriSpeech 표준 데이터셋 구축
-
메타데이터 구조표 데이터 영역 한국어 데이터 유형 오디오 데이터 형식 wav 데이터 출처 도서 라벨링 유형 전사 라벨링 형식 JSON 데이터 활용 서비스 자동 통·번역기, AI 스피커 등 (예시) 데이터 구축년도/
데이터 구축량2022년/4,107시간 -
데이터 통계 데이터 구축 규모
데이터 구축 규모 데이터 종류 규모 음성 및 전사데이터 4,107시간 데이터 분포
○ 주제별 분포데이터 분포○ 주제별 분포 언어 주제 시간 비율 en 1 364 8.87% 2 232 5.64% 3 211 5.13% 4 209 5.09% 소계 1,016 24.74% jp 1 406 9.88% 2 234 5.70% 3 200 4.86% 4 189 4.60% 소계 1,029 25.05% es 1 378 9.20% 2 254 6.18% 3 224 5.45% 4 207 5.03% 소계 1,062 25.86% ko 1 405 9.86% 2 223 5.43% 3 185 4.50% 4 188 4.57% 소계 1,001 24.36% 총 4,107 100.00% 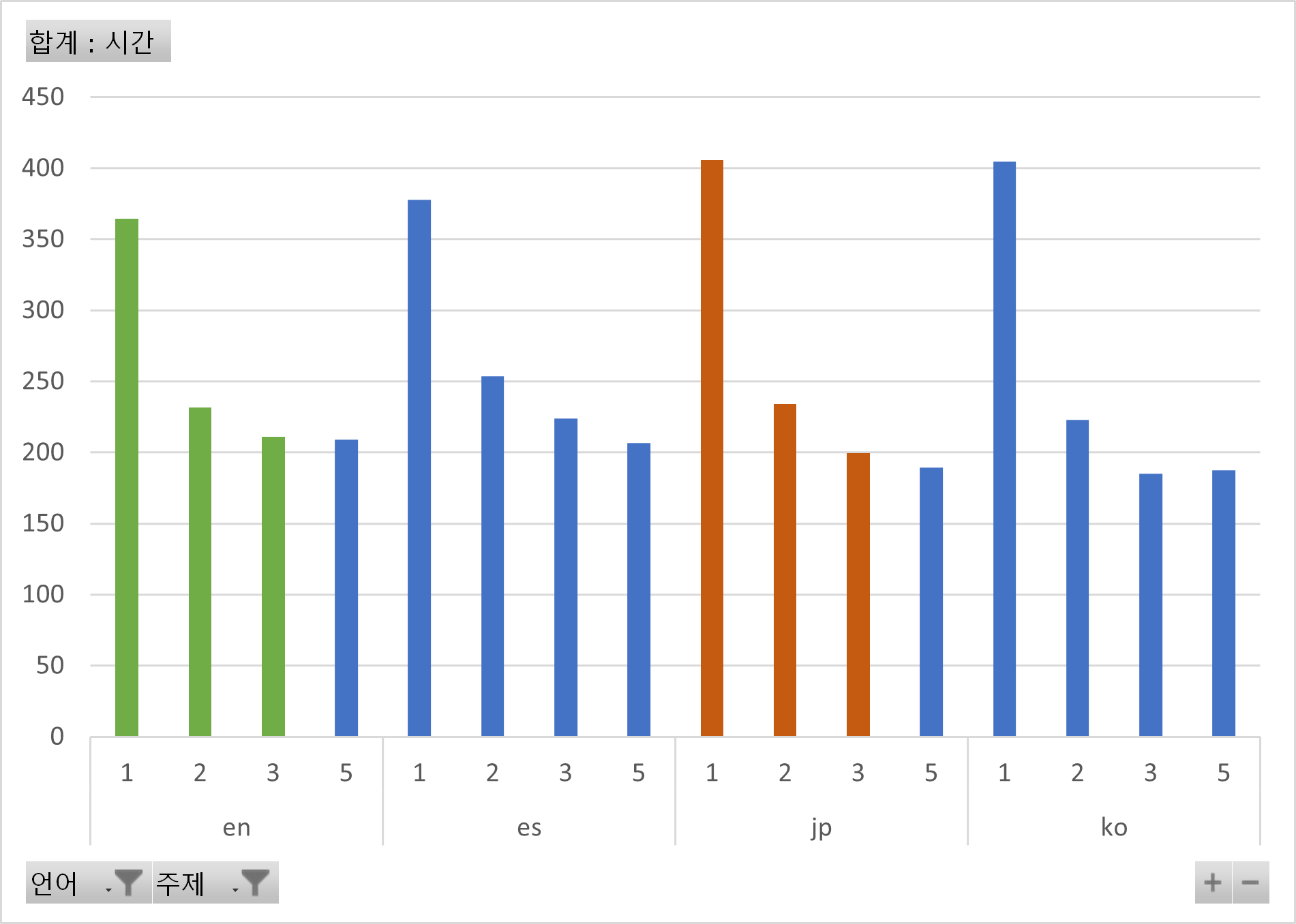
-
-
AI 모델 상세 설명서 다운로드
AI 모델 상세 설명서 다운로드 AI 모델 다운로드모델 학습
○ 기계번역
- Transformer 모델을 활용하여 단일 모델로 한국어-(영어, 스페인어, 일본어) 번역을 수행하는 다국어 기계번역 모델을 학습
- Transformer 모델은 인코더와 디코더로 구성된 Seq-to-Seq 모델로, 기계번역에서 활용될 때는 입력된 특정 언어에 대한 시퀀스 데이터에 대해 다른 언어로 번역된 시퀀스를 출력함
- 다국어 기계번역을 위한 단일 모델 개발 시, 사용하는 데이터에 포함된 모든 언어에 대하여 공통된 vocabulary를 생성함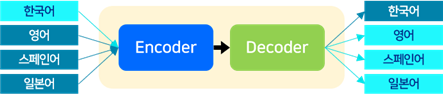
[다국어 번역 모델 구조도]
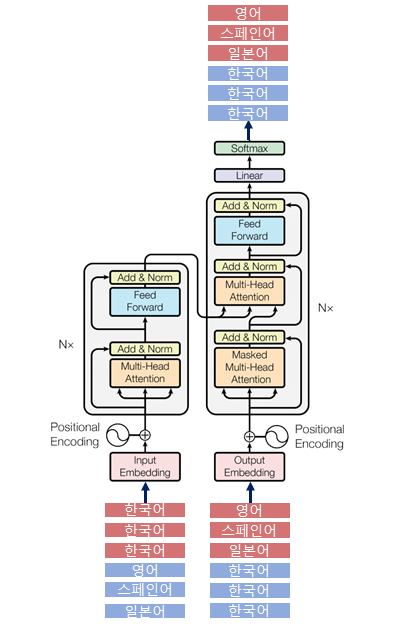
[Transformer 모델 구조도]
- 학습 진행에 따른 BLEU 점수 변화는 아래와 같음 (early stopping 100으로 지정)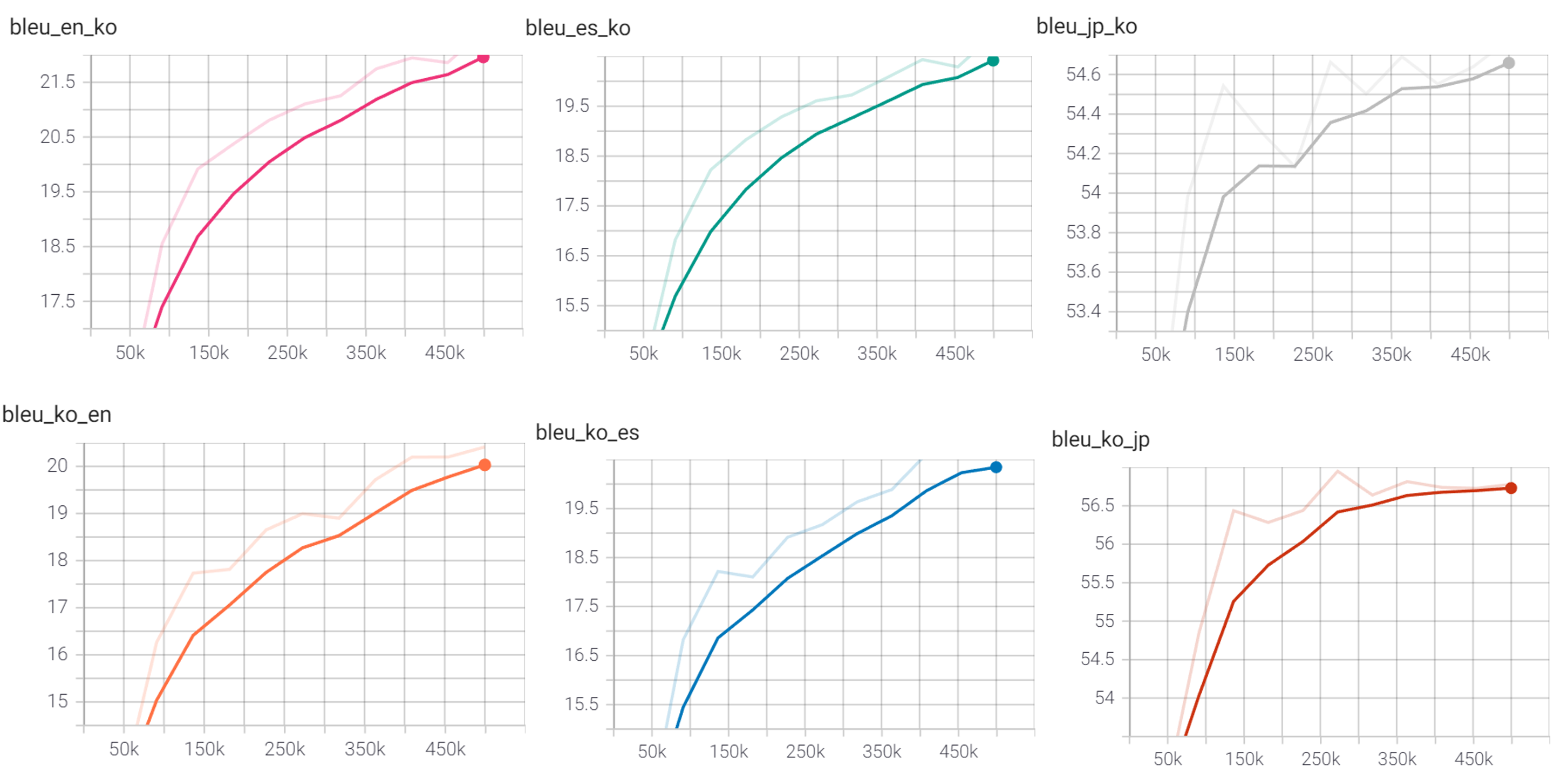
○ 일본어 음성인식
- Wav2Vec2-xls-r 기반의 모델을 활용하여 일본어 음성 인식 학습
- Wav2vec2은 Transformer 기반의 모델로 자동음성인식에서 높은 성능을 보이고 있어 이를 활용한 연구가 활발히 진행되고 있음. Wav2Vec2.0은 자기지도 학습 (self-supervised learning) 방식으로 별도의 텍스트 없이 음향모델을 훈련하는 사전학습 (pre-training) 과정을 거침.
- 사전학습된 wav2vec2 음향모델에, 구체적인 과제와 관련된 전사 텍스트 및 추가 신경망으로 파인튜닝(fine-tuning)을 진행하여 모델을 학습. 이 중 xls-r은 다국어 음성으로 사전학습된 모델로, 영어 음성으로만 사전학습된 기존 wav2vec2.0 보다 일본어 음성 인식에 적합.
- wav2vec2.0 의 학습 알고리즘은 (1)의 사진과 같으며, 여기에 (2)와 같이 전결합층 (fully connected layer)을 하나 추가하여 Connectionist Temporal Classification (CTC) loss 로 일본어 음성 인식 과제를 진행- (1) 사전학습 알고리즘:
출처: UNSUPERVISED CROSS-LINGUAL REPRESENTATION LEARNING FOR SPEECH RECOGNITION (Conneau et al., 2020)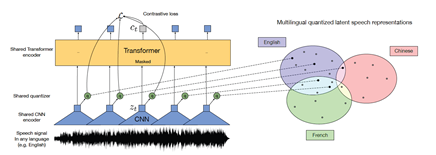
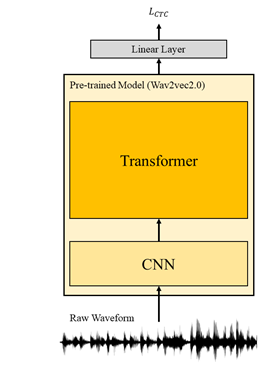
(2) 일본어 음성인식에 대한 파인튜닝
○ 스페인어 음성인식
- 일본어와 마찬가지로 Wav2Vec2-xls-r 기반의 모델을 활용하여 스페인어 음성 인식 학습
- Transformer 기반의 Wav2Vec 모델은 현시점 HUBERT 2.0과 함께 비지도학습 음성인식기들 중 SOTA 퍼포먼스를 자랑함. 여러 언어의 음성에 대하여 (약 436k 시간) 대조 텍스트 없이 비지도 학습이 된 다국어 사전학습 모델을 베이스라인으로, 스페인어 텍스트와 음성을 동시에 학습시키는 지도학습 방법의 downstream task를 수행함- 채택된 모델은 다양한 xls –r 모델중 300million 파라미터를 가진 xls-r-300m모델로, 수행한 파인튜닝 과정은 아래의 그림으로 요약할 수 있음.
출처: https://arxiv.org/pdf/2111.09296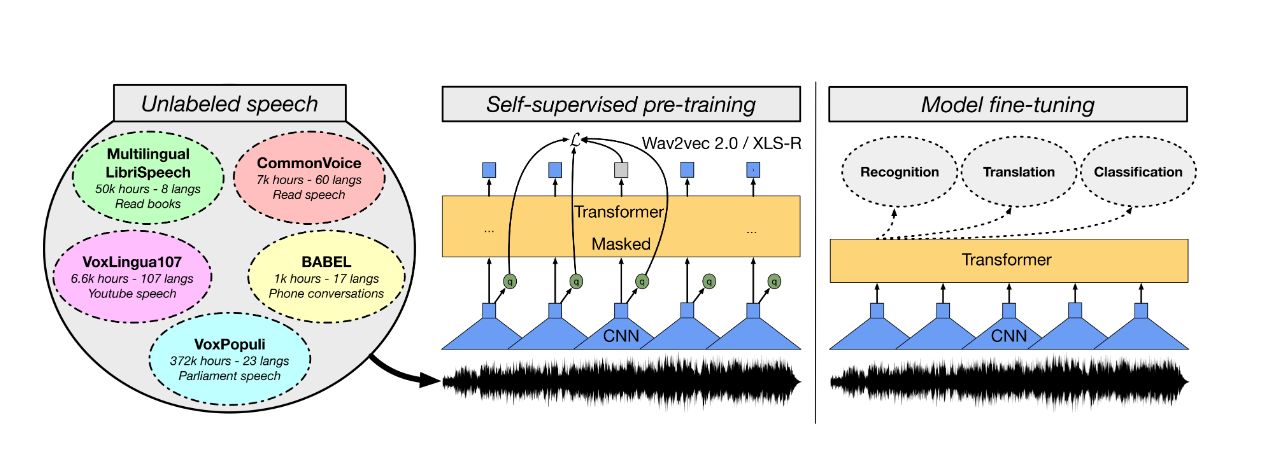
- 사전 학습된 모델의 feature extractor 부분을 제외한 뒷 레이어들을 훈련시킴. feature extractor의 경우 이미 음소와 특징추출의 연계성에 대한 학습이 사전학습 모델 내부에 전제돼있기 때문임.
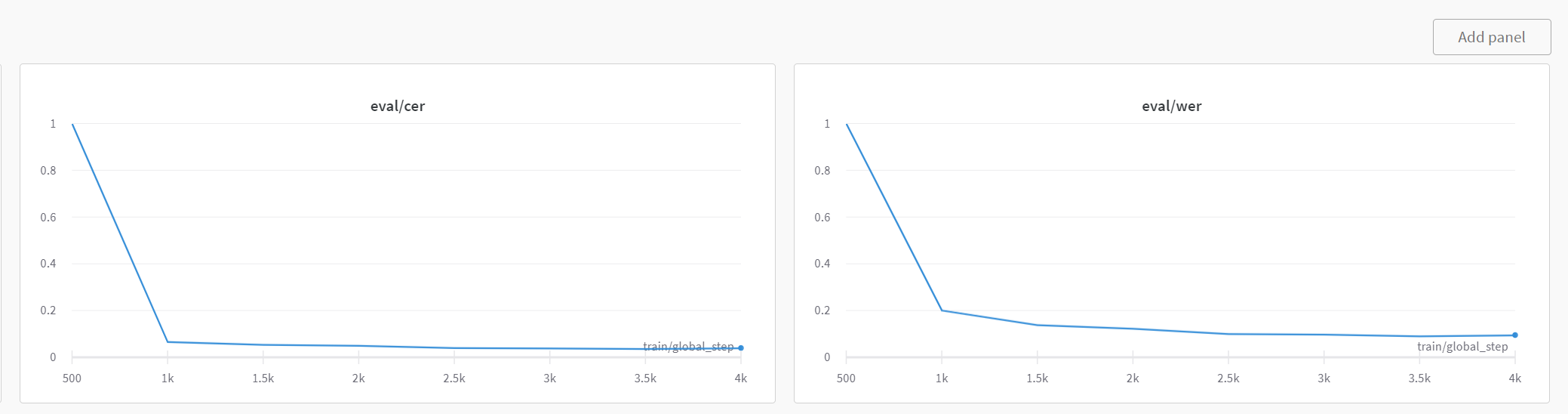
학습 진행에 따른 WER 및 CER 변화의 예시
○ 음성합성
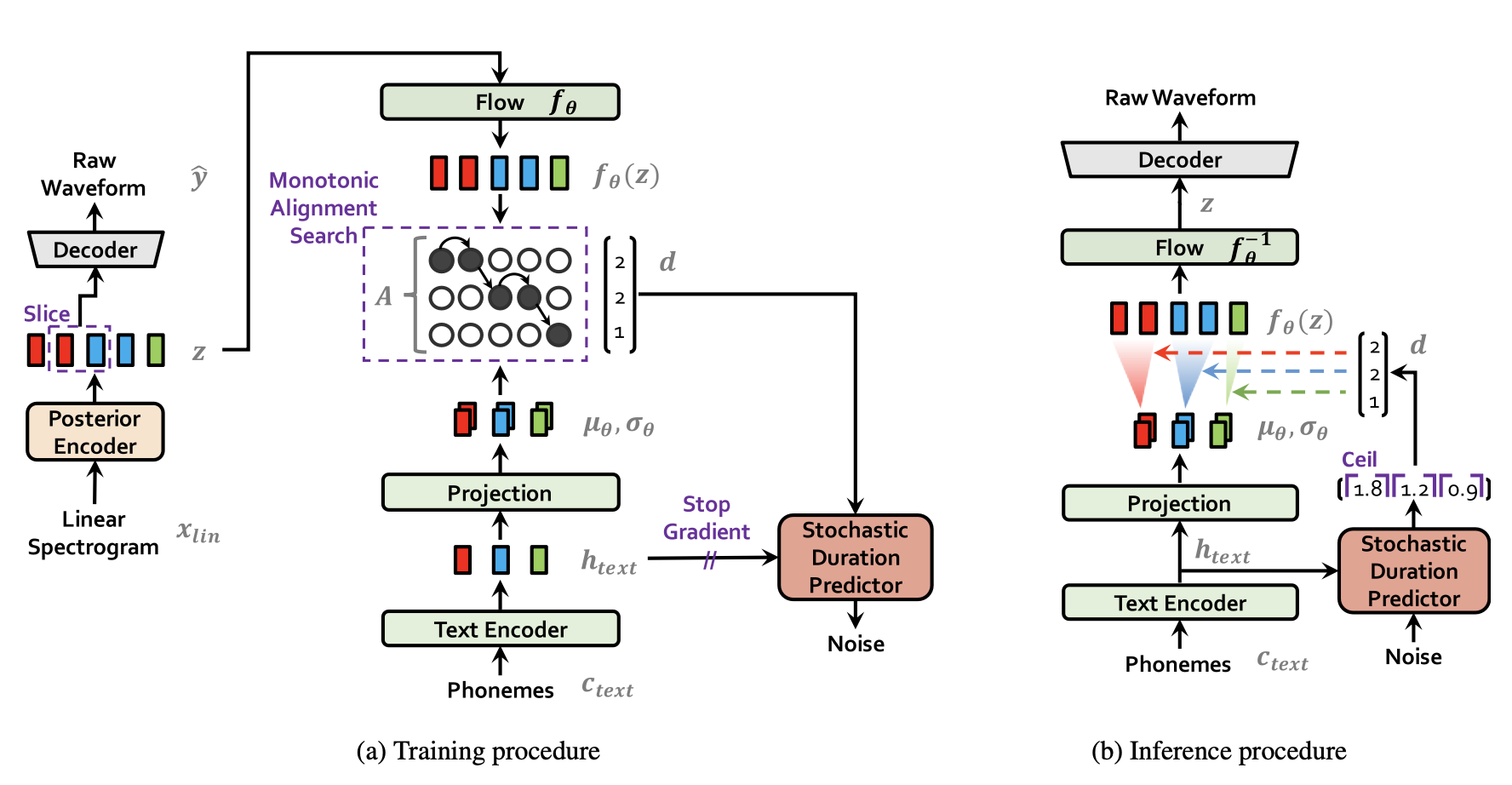
[VITS (Variational Inference with adversarial learning for end-to-end Text-to-Speech)]
- GANS, VAE, Normalizing Flow 등의 기술이 집적된 State of the Art end-to-end (encoder & decoder) TTS model
- 기존의 State of the Art TTS model (Glow-TTS, Tacotron 2)와 비교했을 때 함성음의 음질이 뛰어날 뿐 아니라 합성 음성의 다양성 또한 모델링 할 수 있으며, 2stage가 아니라 encoder와 decoder가 결합되어 있는 end-to-end TTS model로서 합성 속도에도 유의미한 이점이 있음.
-
데이터 성능 점수
측정값 (%)기준값 (%)데이터 성능 지표
데이터 성능 지표 번호 측정항목 AI TASK 학습모델 지표명 기준값 점수 측정값 점수 1 한국어-영어 기계번역 모델 Machine Translation Transformer BLEU 0.15 점 0.203099999999999 점 2 한국어-스페인어 기계번역 모델 Machine Translation Transformer BLEU 0.15 점 0.2075 점 3 한국어-일본어 기계번역 모델 Machine Translation Transformer BLEU 0.17 점 0.571 점 4 한국어 음성 합성 VITS 모델 Speech Synthesis VITS MOS 3.7 점 4.12 점 5 영어 음성합성 VITS 모델 Speech Synthesis VITS MOS 4.1 점 4.1 점 6 Wav2vec 2.0 기반 일본어 음성인식 모델 Speech Recognition model finetuned from Wav2vec2.0-xls-r-300m, with ctc loss WER 12 % 4.47 % 7 Wav2vec 2.0 기반 스페인어 음성인식 모델 Speech Recognition model finetuned from Wav2vec2.0-xls-r-300m using huggingface library WER 15 % 5.4 %
※ 데이터 성능 지표가 여러 개일 경우 각 항목을 클릭하면 해당 지표의 값이 그래프에 표기됩니다.
※ AI모델 평가 지표에 따라 측정값의 범위, 판단 기준이 달라질 수 있습니다. (ex. 오류율의 경우, 낮을수록 좋은 성능을 내는 것으로 평가됩니다)
-
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드데이터 포맷 대표도면
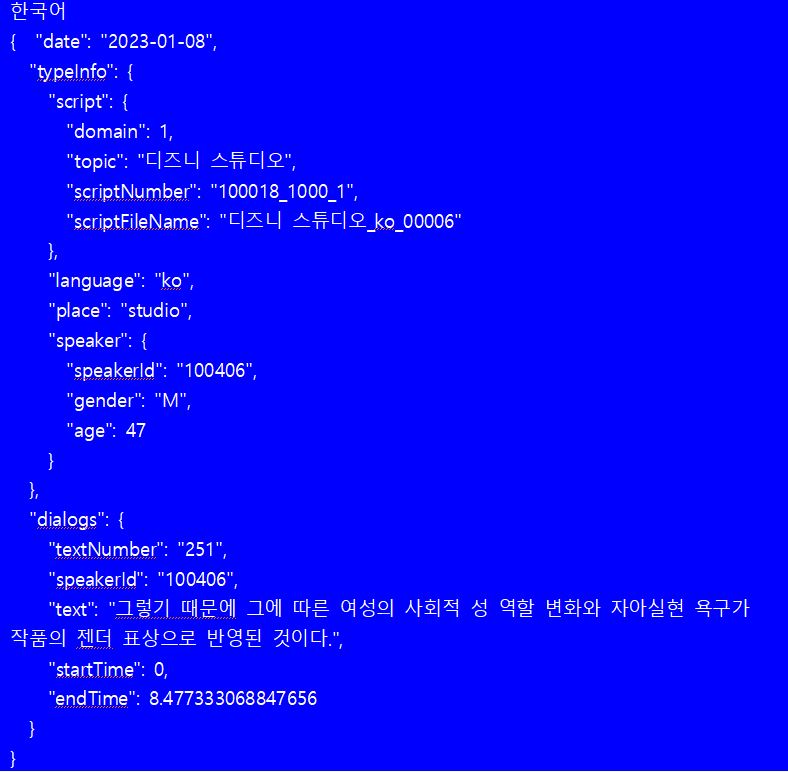
JSON 형식데이터 포맷 JSON 형식 한국어 영어 일본어 스페인어 { "date": "2023-01-08", { "date": "2022-11-05", { "date": "2022-10-24", { "date": "2022-10-27", "typeInfo": { "typeInfo": { "typeInfo": { "typeInfo": { "script": { "script": { "script": { "script": { "domain": 1, "domain": 1, "domain": 1, "domain": 1, "topic": "디즈니 스튜디오", "topic": "디즈니 스튜디오", "topic": "디즈니 스튜디오", "topic": "디즈니 스튜디오", "scriptNumber": "100018_1000_1", "scriptNumber": "100019_1000_1", "scriptNumber": "100020_1000_1", "scriptNumber": "100021_1000_1", "scriptFileName": "디즈니 스튜디오_ko_00006" "scriptFileName": "디즈니 스튜디오_ko_00006" "scriptFileName": "디즈니 스튜디오_ko_00006" "scriptFileName": "디즈니 스튜디오_ko_00006" }, }, }, }, "language": "ko", "language": "en", "language": "jp", "language": "es", "place": "studio", "place": "studio", "place": "studio", "place": "studio", "speaker": { "speaker": { "speaker": { "speaker": { "speakerId": "100406", "speakerId": "100448", "speakerId": "100217", "speakerId": "100150", "gender": "M", "gender": "F", "gender": "F", "gender": "F", "age": 47 "age": 29 "age": 50 "age": 29 } } } } }, }, }, }, "dialogs": { "dialogs": { "dialogs": { "dialogs": { "textNumber": "251", "textNumber": "251", "textNumber": "251", "textNumber": "251", "speakerId": "100406", "speakerId": "100448", "speakerId": "100217", "speakerId": "100150", "text": "그렇기 때문에 그에 따른 여성의 사회적 성 역할 변화와 자아실현 욕구가 작품의 젠더 표상으로 반영된 것이다.", "text": "Therefore, the changes in women's social gender roles and their desire for self-realization are reflected in the gender representation of the work.", "text": "そのため、それに伴う女性の社会的な性役割の変化と自己実現の欲求が作品のジェンダー表象として反映されたのだ。", "text": "Por lo tanto, los cambios en los roles sociales de género de las mujeres y su deseo de autorrealización se reflejan en la representación de género del trabajo.", "startTime": 0, "startTime": 0, "startTime": 0, "startTime": 0, "endTime": 8.477333068847656 "endTime": 9.11733341217041 "endTime": 9.010666847229004 "endTime": 10.845333099365234 } } } } } } } }
데이터 구성데이터 구성 데이터 유형 구분 설명 원천데이터 파일 포맷 WAV 샘플링 레이트 48Khz sampling rate 파일 명명규칙 주제-언어-일련번호-성별-나이-일련번호 라벨링데이터 전사 텍스트 문장단위 음성 전사 텍스트 기타 메타정보 녹음자 정보, 스크립트 정보 등 어노테이션 포맷
어노테이션 포맷 No 항목 타입 필수여부 한글명 영문명 1 데이터 날짜 date string Y 2 데이터 타입 정보 typeInfo object Y 2-1 대본 script object Y 2-1-1 대본 도메인 domain number Y 2-1-2 대본 주제 topic string Y 2-1-3 대본 번호 scriptNumber string Y 2-1-4 대본 파일 이름 scriptFileName string Y 2-2 언어 language string Y 2-3 장소 place string Y 2-4 발화자 speaker object Y 2-4-1 발화자 아이디 speakerId string Y 2-4-2 발화자 성별 gender string Y 2-4-3 발화자 나이 age number Y 3 대화 dialogs object Y 3-1 문장번호 textNumber string Y 3-2 발화자 아이디 speakerId string Y 3-3 문장 text string Y 3-4 시작 시간 startTime string Y 3-5 끝나는 시간 endTime string Y 실제 예시
-
데이터셋 구축 담당자
수행기관(주관) : 한국외국어대학교
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 고윤성 02-2173-2493 root_zero@hufs.ac.kr 데이터 설계, 음성 수집, 원천데이터 정제, 검수(한국어, 스페인어) 수행기관(참여)
수행기관(참여) 기관명 담당업무 커뮤니케이션북스(주) 원시데이터 수집 ㈜나라지식정보 음성 수집, 원천데이터 정제, 검수(영어, 일본어) 서울대학교 AI 학습 모델링 부산대학교 AI 학습 모델링 ㈜오피니언라이브 저작도구 개발 및 운영, 품질관리 데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 고윤성 02-2173-2493 root_zero@hufs.ac.kr
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기] [공용IRB 심의신청 가이드라인]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 safezone1@aihub.kr 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.
오프라인 데이터 이용 안내
본 데이터는 K-ICT 빅데이터센터에서도 이용하실 수 있습니다.
다양한 데이터(미개방 데이터 포함)를 분석할 수 있는 오프라인 분석공간을 제공하고 있습니다.
데이터 안심구역 이용절차 및 신청은 K-ICT빅데이터센터 홈페이지를 참고하시기 바랍니다.

국방데이터 개방 안내
본 데이터는 국방데이터로 군사 보안에 따라 AI허브에서 데이터를 제공하지 않으며,
군 담당자를 통한 별도의 사용 신청이 필요합니다.