-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.1 2023-12-15 데이터 최종 개방 1.0 2023-07-31 데이터 개방(Beta Version) 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2024-04-03 산출물 전체 공개 2024-02-27 상세페이지 내용 수정 소개
- 생물계절 및 환경조건에 따른 감귤 착과량을 예측하여 감귤 생산량 예측 시 필요한 기초 자료 제공과 신뢰도 높은 디지털 정보 제공 - 나무의 크기에 따른 개화 상태 및 새순의 생육 상태에 따른 착과량을 AI기술을 통해 예측 - 제주 전역 동(표선), 서(대정), 남(서귀포), 북(제주) 총 40개 농가를 지정하여 원시데이터 수집 - 감귤나무 크기 (너비 >=3M, 너비<3M) 분포로 편향성 방지 - 원시데이터 250,000장을 가이드라인에 따라 선별하여 가공 가능한 201,184장 원천데이터 확보 - 객체 별 필요 환경데이터 및 메타 데이터 수집
구축목적
- 생물계절 및 환경 조건에 따른 감귤 착과량을 예측하여 감귤 생산량 예측 시 필요한 기초 자료 제공과 신뢰도 높은 디지털 정보 제공 - 나무의 크기에 따른 개화 상태 및 새순의 생육 상태에 따른 착과량을 AI기술을 통해 예측 - 노지 감귤의 생리낙과 종료시기 추정과 착과 예측모형 개발
-
메타데이터 구조표 데이터 영역 농축수산 데이터 유형 이미지 데이터 형식 jpg 데이터 출처 직접 촬영 라벨링 유형 폴리곤(이미지), 메타데이터 라벨링 형식 json 데이터 활용 서비스 - 기상조건에 따른 생리 낙과 및 착과 특성 분석 - 병해충 방제지도: 검은점무늬병, 총채벌레, 응애 등 - 토양 멀칭재배농가 토양건조상태 확인 후 토양수분관리 - 비규격품 및 불량감귤 제거를 위한 수상선과 추진 - 완숙과 구분 수확에 의한 고품질 감귤 출하 지도 데이터 구축년도/
데이터 구축량2022년/201,184장 -
가. 데이터 구축 규모
구분1 구분2 구분3 객체 목표수량(frames) 원목DB 지역구분 나무 크기 (꽃or새순)상태 서(대정) 1.너비>3 1.많음 감귤나무 원시데이터:250,000건 남(서귀포시) 2.보통 원천데이터:201,184건 2.너비<3 환경데이터:201,184건 북(제주시) 3.빈약 라벨링데이터:201,184건 합계 최종 201,184세트 나. 데이터 분포
수집 지역 분포지역 구축량 구성비 제주시 63,429 31.53% 서귀포시 113,901 56.62% 서귀포(대정) 23,853 11.86% 합계 201,184 100% 감귤 나무 크기 분포
크기 구축량 구성비 300CM 미만 111,699 55.52% 300CM 이상 89,485 44.48% 합계 201,184 100% -
-
AI 모델 상세 설명서 다운로드
AI 모델 상세 설명서 다운로드 AI 모델 다운로드가. 학습모델 후보
구분 내 용 DNN 알고리즘 - DNN 선정사유 - ANN신경망 기법의 문제를 해결하면서 모델 내 Hidden Layer를 늘려 학습의 결과를 향상시키는 방법 해당 방법의 경우 많은 양의 데이터와 반복학습, 사전학습, 역전파 기법을 통해 널리 사용됨 해당 과제에 최적화된 모델링 구축(너무 deep한 layer구성의 경우 Overfitting의 가능성이 있기 때문에 적절한 layer구성을 통해 성능을 평가 LSTM 알고리즘 - LSTM 선정사유 - 전통적인 RNN의 단점을 보완하여 은닉층의 메모리 셀에 입력, 망각, 출력게이트를 추가(cell state)하여 불필요한 기억을 지우고, 기억해야 할 것을 정함 - cell state는 일종의 컨베이어 벨트 역할을 수행. 이로 인해 vanishing gradient problem문제 해결 MLP 알고리즘 - MLP (Multi Layer Perceptron) 선정사유 - XOR 게이트는 기존의 AND, NAND, OR 게이트를 조합하면 만들 수 있음 - 단층 퍼셉트론과는 다르게 입력층, 출력층 외에 은닉층이라는 hidden layer가 추가되어 있는 형태 - overfitting과 Vanishing Gradient 문제를 해결하기 위해 Regularization, More Training data, Reduce the number of features, activation 함수를 조절 Stacking 알고리즘 - Stacking 선정사유 - 여러 모델(4가지 이상)을 활용해 각각의 예측 결과를 도출하여 해당 결과들로 최종 예측 결과를 만들어 내는 방식 - 각 모델별 예측값을 독립변수로, 실제 라벨데이터(GT)를 종속변수로 사용 - Stacking 방법으로 학습진행 시 Overfitting의 가능성이 높기 때문에 Cross Validation을 통해 Overfitting 발생가능성을 줄이고 보다 일반화된 모델을 생성 가능 Regression 방식 라이브러리 PyCaret 선정사유 - PyCaret이라는 오픈 라이브러리를 통해 다양한 Regression모델들을 동시다발적으로 학습 및 평가를 진행하여 원하는 Metrics값을 기준으로 상위 모델들을 분류 및 선별을 통해 ensembling, blending, stacking등 의 방식으로 조합하여 최적의 예측모델을 생성하는 것을 목표로 함 단순히 AutoML만을 사용하는 것이 아닌 tensorflow의 kears처럼 세부적인 커스텀과 모델 구축이 가능하다는 장점이 있으며, Data_preprocessing을 어떻게 하느냐에 따라서도 모델의 성능 차이가 크게 나타남. Ensemble_model : bagging과 bosting을 파라미터에서 설정 가능 blend_model : Voting방식으로 구현하며, 성능이 잘 나온 모델들을 선택하는 파라미터를 적용 Stack_model : stacking 방식을 적용한 Ensemble의 한 종류로서 blend와 마찬가지로 성능이 잘 나온 모델들을 선택하는 파라미터를 적용 Loss방식 또한 PyCaret내부에 있는 방식뿐 아니라 추가적인 Loss계산이 필요할 때 사용자가 직접 커스텀하여 생성 및 실행할 수 있음 Regression의 경우 총 25개의 regression_model들이 내장되어 있고 세부 Regressor 모델들은 총 25개의 모델들로 구성되어 있음 ‘lr’ - Linear Regression ‘lasso’ - Lasso Regression ‘ridge’ - Ridge Regression ‘en’ - Elastic Net ‘lar’ - Least Angle Regression ‘llar’ - Lasso Least Angle Regression ‘omp’ - Orthogonal Matching Pursuit ‘br’ - Bayesian Ridge ‘ard’ - Automatic Relevance Determination ‘par’ - Passive Aggressive Regressor ‘ransac’ - Random Sample Consensus ‘tr’ - TheilSen Regressor ‘huber’ - Huber Regressor ‘kr’ - Kernel Ridge ‘svm’ - Support Vector Regression ‘knn’ - K Neighbors Regressor ‘dt’ - Decision Tree Regressor ‘rf’ - Random Forest Regressor ‘et’ - Extra Trees Regressor ‘ada’ - AdaBoost Regressor ‘gbr’ - Gradient Boosting Regressor ‘mlp’ - MLP Regressor ‘xgboost’ - Extreme Gradient Boosting ‘lightgbm’ - Light Gradient Boosting Machine ‘catboost’ - CatBoost Regressor 나. 후보군별 품질지표
품질 지표 내 용 MAE 지표설명 - 평균 절대 오차 MAE (Mean Absolute Error) - 모든 절대오차의 평균값 - 일반적 회귀 지표 (낮을수록 좋은 수치) 계산식 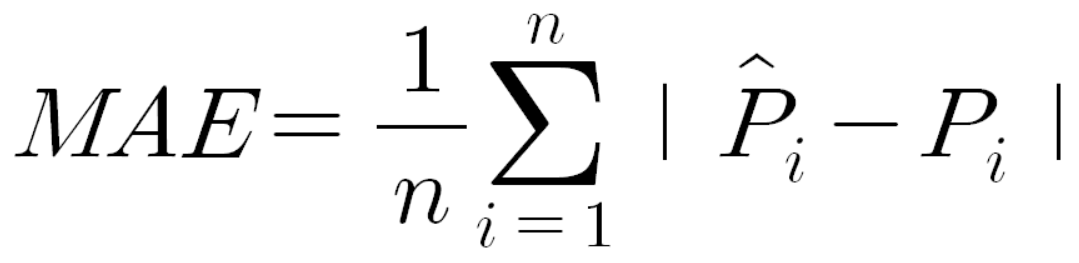
수식 - 그림1
RMSE 지표설명 - 표준편차와 비슷한 의미로 작을수록 모델의 성능이 더 좋다고 평가 - 평균 제곱근 오차는 오차가 커질수록 값이 더 증가하여 오차의 존재를 부각시키며, Regression에 선호되는 지표 계산식 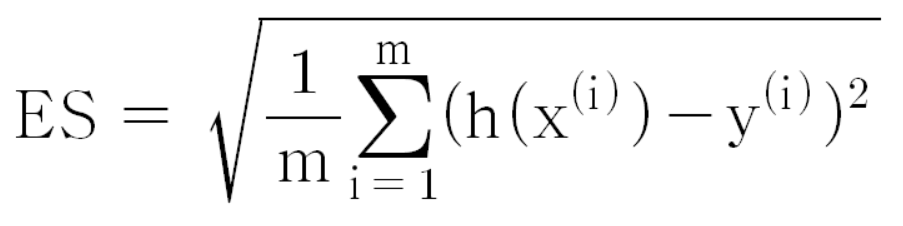
수식 - 그림2
다. 유효성 검증 환경
유효성 검증 항목 항목명 제주 감귤 착과량 예측 검증 방법 ipynb파일 제출 목적 Regression 지표 nMAE, MAPE 측정 산식 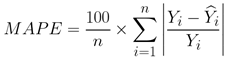
그림 3
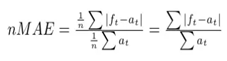
그림 4유효성 검증 환경 CPU Intel(R) Xeon(R) Gold 6240 CPU @ 2.60GHz Memory 204G GPU Nvidia Geforce RTX 3090Ti Storage 2TB OS Linux 유효성 검증 모델 학습 및 검증 조건 개발 언어 Python 3.8.13 프레임워크 pandas – 1.4.4, matplotlib – 3.6.3, pycaret – 2.3.10, tqdm – 4.64.1, seaborn – 0.11.2, sklearn – 0.23.2, jupyter – 1.0.0, numpy – 1.20.3 학습 알고리즘 1. pycaret는 classification, Regression 등의 task에서 여러 모델을 같은 환경에서 간단한 코드로 실행하여 비교할 수 있는 AutoML 라이브러리 2. Regression 과업에 맞는 다양한 Regression 모델들을 비교 분석하여 최적의 Regression 모델을 구축 3. 시간과 비용적인 측면에서 효율적으로 활용할 수 있으며, 성능이 좋은 모델들을 앙상블하여 단순 1개의 모델보다 높은 성능의 모델을 사용 가능 학습 조건 train_size = 0.7, session_id = 42, normalize = True, silent = True, transformation=True, use_gpu=True, fold_shuffle=True 파일 형식 • 학습 데이터셋: json • 평가 데이터셋: json 전체 구축 데이터 대비 모델에 적용되는 비율 AI 모델 적용 비율 - 전체 데이터셋(100%) 중, 40%는 AI모델의 학습데이터로 활용하고 60%는 최종 평가 데이터로 활용 -
데이터 성능 점수
측정값 (%)기준값 (%)데이터 성능 지표
데이터 성능 지표 번호 측정항목 AI TASK 학습모델 지표명 기준값 점수 측정값 점수 1 감귤 착과량 예측 성능 Estimation Pycaret MAPE 5 % 4.89 % 2 감귤 착과량 예측 성능 Estimation Pycaret NMAE 5 % 3.5 %
※ 데이터 성능 지표가 여러 개일 경우 각 항목을 클릭하면 해당 지표의 값이 그래프에 표기됩니다.
※ AI모델 평가 지표에 따라 측정값의 범위, 판단 기준이 달라질 수 있습니다. (ex. 오류율의 경우, 낮을수록 좋은 성능을 내는 것으로 평가됩니다)
-
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드구분 설명 항목 타입 1 데이터셋정보 info object 1-1 지역(농가) direction string 1-2 과수번호 sep string 1-3 일반이미지 NI_image object 1-3-1 파일명 filename string 1-3-2 촬영일날짜 day string 1-4 정사이미지 OI_image object 1-4-1 파일명 filename string 1-4-2 촬영일날짜 day string 1-5 품종 race string 1-6 연생 myear number 1-7 개화비율 f_ratio number 1-8 새순비율 new_leaf_ratio number 1-9 착과량 man_count number 1-10 나무 높이 man_height number 1-11 나무 너비(평균) man_width_avg number 1-12 엽록소 함량(평균) chl_avg number 1-13 농가좌표위도 lat string 1-14 농가좌표경도 lon string 1-15 농가고도 alti number 1-16 농가 면적 area number 1-17 풍속 windy_avg number 1-18 풍향 windir_avg number 1-19 온도 deg_avg number 1-20 습도 hum_avg number 1-21 압력 pa_avg number 1-22 강수량 rain_avg number 1-23 적설량 snow_avg number 1-24 태양복사 solar_avg number 1-25 지구복사 radiat_avg number 1-26 토양온도 temp1_avg number 1-27 토양온도 temp2_avg number 1-28 토양온도 temp3_avg number 1-29 토양온도 temp4_avg number 1-30 토양수분 soil1_avg number 1-31 토양수분 soil2_avg number 1-32 토양수분 soil3_avg number 1-33 토양수분 soil4_avg number 1-34 RGB 이미지 EXIF NI_image_EXIF object 1-34-1 타입 type string 1-34-2 촬영장비 device string 1-34-3 해상도 resolution string 1-34-4 비트값 bit number 1-34-5 ISO감도 ISO string 1-35 정사이미지 EXIF OI_image_EXIF object 1-35-1 타입 type string 1-35-2 촬영장비 device string 1-35-3 해상도 resolution string 1-35-4 비트값 bit number 1-35-5 ISO감도 ISO string 1-35-6 촬영고도 s-Alti number 2 폴리곤 Annotations polygon_annotations array 2-1 {} object 2-1-1 객체아이디 polygon.id string 2-1-2 객체분류 polygon.class string 2-1-3 카테고리 polygon.category string 2-1-4 폴리곤내 점의 집합 polygon.points array [] array 3 Bbox Anntatios bbox_annotations array 3-1 [] array 3-1-1 {} object 객체아이디 bbox.id string 객체분류 bbox.class string 카테고리 bbox.category string 점의 집합 bbox.points array -
데이터셋 구축 담당자
수행기관(주관) : 제주대학교 산학협력단
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 오산수민 064-754-3983 ohsumin@gmail.com 사업총괄, 데이터 설계, 데이터 수집 및 정제, 데이터 검사 수행기관(참여)
수행기관(참여) 기관명 담당업무 제주대학교 산학협력단 사업총괄, 데이터 설계, 데이터 수집 및 정제, 데이터 검사 주식회사 제우스 데이터 수집 및 정제 농업회사법인 제주청년농부 주식회사 데이터 수집 주식회사 데이터메티카 데이터 가공 ㈜미디어그룹 사람과숲 데이터 가공 데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 오산수민 064-754-3983 ohsumin@gmail.com
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 safezone1@aihub.kr 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.