※ 25년 신규 개방되는 데이터로, 데이터 활용성 검토, 이용자 관점의 개선의견 수렴 등을 통해 수정/보완될 수 있으며 최종데이터, 샘플데이터, 산출물 등은 변경될 수 있습니다
-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.0 2025-04-16 데이터 개방 Beta Version 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2025-04-16 산출물 전체 공개 소개
멀티턴 형식의 인터뷰 데이터로 다양한 상황과 목적에 맞는 인터뷰 멀티턴 질의 생성을 위한 인공지능 학습용 데이터셋
구축목적
본 과제를 통해 멀티턴 방식의 인터뷰 질의 생성 기술 발전을 지원하고, 리서치 산업의 인공지능 신기술 융합 및 적용에 기여하기 위함
-
메타데이터 구조표 데이터 영역 한국어 데이터 유형 텍스트 데이터 형식 json 데이터 출처 ㈜ 코리아리서치인터내셔널 라벨링 유형 Entity, Relation(자연어) 라벨링 형식 json 데이터 활용 서비스 - AI Hub 페이지에 공개하여 누구나 쉽게 데이터를 활용할 수 있는 환경을 마련 - 코리아리서치인터내셔널의 자체 플랫폼인 키위서베이와 PCN의 자체 플랫폼인 앤서니를 활용하여 시범서비스를 배포하여 홍보 진행 예정 데이터 구축년도/
데이터 구축량2024년/원천 데이터: 3,040건, 라벨링 데이터: 3,040건 -
1) 데이터 구축 규모
- 원천 데이터: 3,040건,
- 라벨링 데이터: 3,040건
2) 데이터 분포데이터 분포 항목명 결과 진행자 성향 분포 진행자 성향 수량 비율 기타 65 2.14% 설명형 1,873 61.61% 예시형 798 26.25% 요약형 304 10.00% 합계 3,040 100.00% 멀티턴 횟수 분포 멀티턴 횟수 수량 비율 2 59 1.94% 3 197 6.48% 4 226 7.43% 5 253 8.32% ... ... ... 30 1 0.03% 합계 3,040 100.00% 인터뷰 질문 문항 어절 수 어절 수 수량 비율 5 2,750 11.41% 6 2,500 10.37% ... ... ... 132 1 0.00% 합계 24,105 100.00% 인터뷰 주제별 분포 주제 수량 비율 소비자 이해 1,077 35.43% 소비자 만족도 482 15.86% 매체/브랜드 371 12.20% 제품 개발 159 5.23% 기업평가 86 2.83% 사회 및 공공 조사 661 21.74% 학술 204 6.71% 합계 3,040 100.00% -
-
AI 모델 상세 설명서 다운로드
AI 모델 상세 설명서 다운로드 AI 모델 다운로드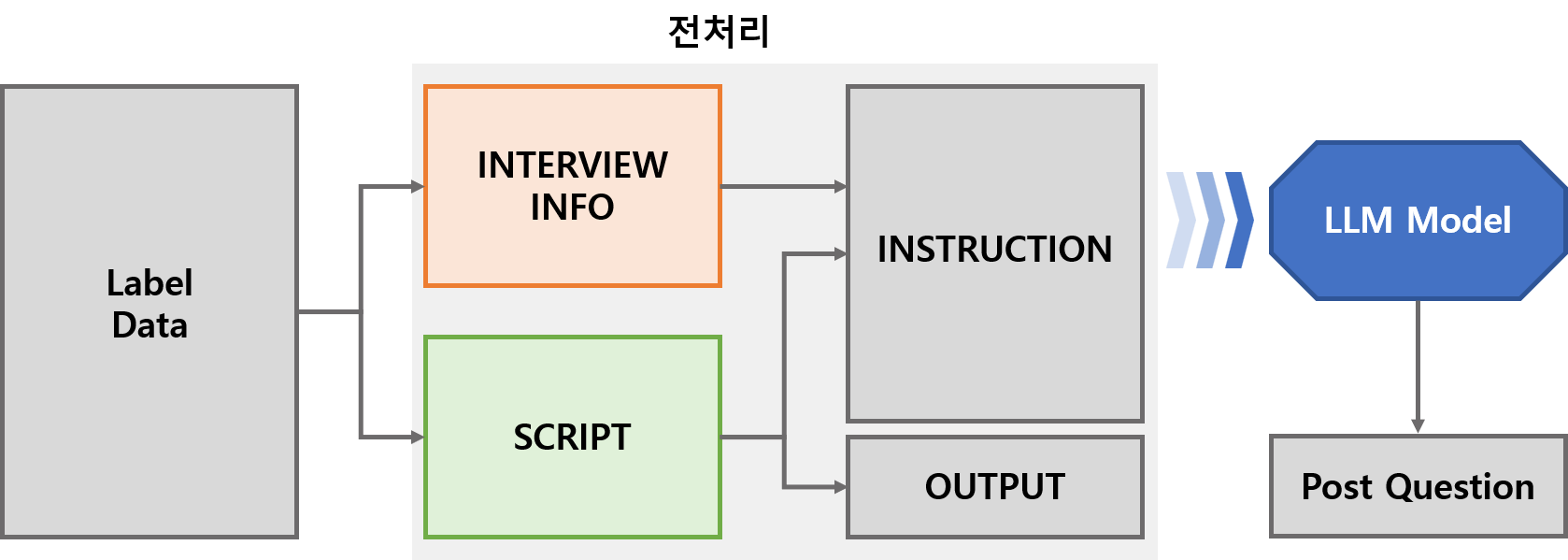
12-22 인터뷰 멀티턴 질의 생성 모델 개략도
데이터 전처리
● 인터뷰 진행 멀티턴 데이터의 학습 모델은 인터뷰 목적과 이전 질문-답변 내용을 기반으로 후속 질문을 생성하는 모델임
● 질문에 대한 답변 생성이라는 일반적인 task가 아닌 멀티턴 기반 이전 답변에 대한 다음 질문 생성이라는 task에 특화되도록 인터뷰 기본 정보, 이전 질문-답변 쌍의 멀티턴 대화, 마지막 답변에 대한 후속 질문 등으로 데이터 전처리 진행
● 학습/검증/평가를 위해 8:1:1로 나눈 데이터셋으로 학습 및 평가를 진행함데이터 전처리 데이터셋 구분 개수(개) 비율(%) 학습 데이터셋 2,419 79.6 검증 데이터셋 312 10.2 평가 데이터셋 309 10.1 데이터 구성 요소
● ‘인터뷰 기본 정보(interview_info)’는 인터뷰의 목적(purpose), 주제(topic), 제목(title), 유형(type), 진행자 스타일(interviewer_style), 키워드(keyword)로 구성함
● ‘이전 대화(script)’는 turn 단위의 이전 대화 내용(before_conversation)과 마지막 질문(question), 마지막 답변(answer)이 포함됨
● 답변(answers)에는 응답자의 식별자(answer_id), 응답 내용(answer_context), 질문과의 맥락적 일치 여부(answer_match)가 포함됨
● 입력 데이터를 기반으로 이어지는 ‘후속 질문(post_question)’을 출력 데이터로 전처리하여 학습/검증/평가에 사용함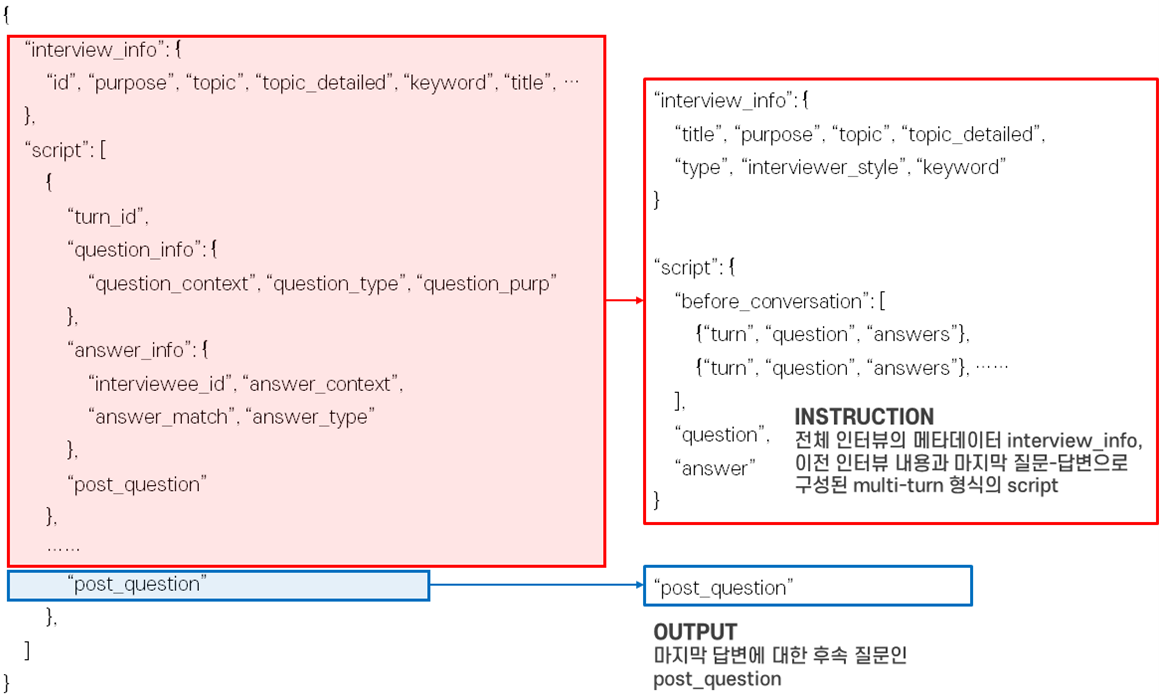
Input/Output 예시
활용 모델
● 본 사업에서 필요로 하는 LLM의 조건은 ‘한국어 데이터를 이해’해서 ‘한국어 문장 생성’이 가능한 ‘Text-to-Text Generation 능력’으로 볼 수 있음
● 위 조건을 종합적으로 고려해 komt-mistral-7b-v1, SOLAR-10.7B-Instruct, Long-ke-T5와 OpenSource 모델 중 성능이 좋은 LLaMa3를 학습 모델 후보군으로 선정하여 비교함
● 동일한 입력값으로 후보 모델 간 생성 결과를 비교한 결과 komt-mistral-7b-v1 모델이 본 사업 조건에 적합하다고 판단되어 Base model로 선정함활용모델 모델 후보군 모델 출력 결과 komt-Mistral-7B-v1 
SOLAR-10.7B 
LLaMa3 




Long-ke-T5 
모델 성능 지표
모델 성능 지표 성능 지표 내용 G-Eval ● Evaluation Text Generation with GPT-4(이하 G-Eval)은 자연어 처리(NLP)모델의 성능을 평가하기 위해 개발된 종합지표임
● 모델이 생성한 텍스트의 여러 측면을 분석하여 모델의 전반적인 성능을 측정함
● 단순한 정량적 성능 평가를 넘어, 모델 임무에 맞는 적절한 세부 평가 항목을 직접 설정하여 모델이 생성한 텍스트가 실제 수요에 얼마나 부합하는지를 중점적으로 평가함
● 성능 평가 지표로 최근 활용되고 있는 LLM 기반 평가지표 조사 및 자체 테스트를 한 결과, 정확도, 비용, 한국어 지원 등 종합적인 측면에서 높은 성능과 생성 속도가 효율적인 GPT-4o 모델 기반 G-Eval을 선정함
● G-Eval 평가지표의 세부 평가 항목으로 문법 정확성, 문맥적 적합성을 평가하기 위한 Contextual Accuracy, 일관성을 평가하기 위한 Question Similarity를 설정함
● Contextual Accuracy 항목은 AI 모델로 생성된 문장의 문법 정확성, 문맥적 적합성을 평가하여 AI 모델의 문장 생성 능력을 평가함
● Question Similarity 항목은 생성된 문장과 참조 문장의 유사도를 평가하여 AI 모델의 적합한 데이터 생성 능력을 평가함
● 테스트 데이터셋 기반 파인튜닝 모델과 상용 LLM 모델을 활용하여 5회 교차검증 진행함
● 본 사업에서는 G-Eval 3.5 이상을 목표로 함




BLEU ● BLEU는 AI 모델의 출력값과 실제값 간의 유사성을 n-gram의 정밀도 기반으로 측정한 방법론
● 생성된 문장과 참조 문장 간 키워드 유사도를 평가하는 전통 지표
● 본 사업에서는 BLEU 0.1 이상을 목표로 함ROUGE ● ROUGE은 실제값과 AI 모델 출력값 간의 유사성을 n-gram의 재현율 기반으로 측정한 방법론
● 생성된 문장과 참조 문장 간 키워드 유사도를 평가하는 전통 지표
● 본 사업에서는 ROUGE 0.1 이상을 목표로 함 -
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드<데이터 어노테이션 포맷 및 형식>
데이터 어노테이션 포맷 및 형식 항목 속성명 타입 필수 여부 항목 설명 범위 1 interview_info object Y 인터뷰 정보 1 id string Y 인터뷰 ID 2 purpose string Y 인터뷰 목적 3 topic object Y 주제 정보 1 topic string Y 세부 주제 소비자 이해, 소비자 만족도, 매체/브랜드, 제품 개발, 기업평가, 사회 및 공공, 학술 2 topic_detailed string Y 세부 인터뷰 주제 라이프 스타일, U&A(이용행태), 구매행태, 고객 만족도, 광고효과, 브랜드 인지/진단, 사용성UX, 컨셉/제품테스트, 기업평판, 직원 만족도, 사회현안, 정책평가, 행정서비스 평가, 정책수요, 심리 사회과학, 의학 4 keyword array Y 인터뷰 키워드 5 title string Y 인터뷰 제목 6 source string Y 인터뷰 출처 Kri, 학술 7 interviewer_sty string Y 진행자 성향 설명형, 요약형, 예시형, 기타 8 turns string Y 멀티턴 횟수 9 type string Y 인터뷰 종류 IDI, FGD 10 interviewee_num string Y 인터뷰 대상자 수 11 interviewee object Y 인터뷰 대상자 1 interviewee_id string Y 인터뷰 대상자 아이디 2 gender string N 성별 남, 여, 무관 3 age array N 나이 10대, 20대, 30대, 40대, 50대, 60대 이상 4 location string N 조사 대상자 지역 2 script array Y 인터뷰 내용 1 turn_id string Y 턴 순서 2 question_info object Y 질문 정보 1 question_context string Y 질문 내용 진행자의 질문 내용 2 question_type string Y 질문 분류 주요 질문, 후속 질문, 기타 3 question_purp string Y 질문 목적 3 answer_info object Y 답변 정보 1 interviewee_id string Y 인터뷰 대상자 아이디 2 answer_context string Y 답변 내용 응답자의 응답 내용 3 answer_match string Y 맥락일치 여부 일치, 불일치 4 answer_type string Y 후속질문 필요 여부 있음, 없음 4 post_question string N 후속 질문 내용 <가공데이터 라벨링 및 어노테이션 적용 예시>
가공데이터 라벨링 및 어노테이션 적용 예시 항목 속성명 항목 설명 예시 1 interview_info 인터뷰 정보 1 id 인터뷰 ID dur_con_001 2 purpose 인터뷰 목적 브랜드 전자 드럼 세탁기 기능
/특징 유용성 및 구매 영향도 평가
3 topic 주제 정보 1 topic 세부 주제 소비자 만족도 2 topic_detailed 세부 인터뷰 주제 U&A (이용행태) 4 keyword 인터뷰 키워드 ["브랜드 전자", "드럼 세탁기",
"기능/특징", "구매 영향도", "유용성"]
5 title 인터뷰 제목 브랜드 전자 드럼 세탁기 기능
/특징 유용성 및 구매 영향도 평가 설문조사
6 source 인터뷰 출처 kri 7 interviewer_sty 진행자 성향 설명형 8 turns 멀티턴 횟수 2 9 type 인터뷰 종류 IDI 10 interviewee_num 인터뷰 대상자 수 1 11 interviewee 인터뷰 대상자 1 interviewee_id 인터뷰 대상자 아이디 A 2 gender 성별 남 3 age 나이 30대 4 location 조사 대상자 지역 2 script 인터뷰 내용 1 turn_id 턴 순서 1 2 question_info 질문 정보 1 question_context 질문 내용 해당 제품을 구매하셨다고 하셨는데요,
해당 제품의 해당 기능은 필요있다고 생각하시나요
2 question_type 질문 분류 주요 질문 3 question_purp 질문 목적 기능 필요성에 대해 물어보기 위해서 3 answer_info 답변 정보 main 1 interviewee_id 인터뷰 대상자 아이디 A 2 answer_context 답변 내용 해당 기능은 별 필요 없다고 생각하는데요,
그냥 사용을 안 하게 됩니다.
3 answer_match 맥락일치 여부 일치 4 answer_type 후속질문 필요 여부 없음 4 post_question 후속 질문 내용 그러면 다음 질문으로 넘어가겠습니다. @product를 사용하시면서 가장 만족감이 들으셨던 부분은 어떤 부분일까요? 1 turn_id 턴 순서 2 2 question_info 질문 정보 B 1 question_context 질문 내용 그러면 다음 질문으로 넘어가겠습니다. @product를 사용하시면서 가장 만족감이 들으셨던 부분은 어떤 부분일까요? 2 question_type 질문 분류 주요 질문 3 question_purp 질문 목적 제품 만족도를 물어보기 위해" 3 answer_info 답변 정보 1 interviewee_id 인터뷰 대상자 아이디 A 2 answer_context 답변 내용 잔고장이 없다는 부분이 가장 만족감 들은 부분이에요. 다른 사항은 크게 만족감은 없고요. 무난 무난합니다. 3 answer_match 맥락일치 여부 일치 4 answer_type 후속질문 필요 여부 있음 4 post_question 후속 질문 내용 무난 무난하다는 게 정확히 어떤 의미실까요? 가공데이터 json 파일 예시 이미지 가공데이터 json 파일 예시 이미지 

-
데이터셋 구축 담당자
수행기관(주관) : ㈜코리아리서치인터내셔널
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 채주희 02-3415-5131 joohee@kric.com 총괄책임자 수행기관(참여)
수행기관(참여) 기관명 담당업무 ㈜피씨엔 AI 모델링 ㈜비투엔 데이터 검수 데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 채주희 02-3415-5131 joohee@kric.com 윤치영 02-6009-2759 cyyoon@kric.com AI모델 관련 문의처
AI모델 관련 문의처 담당자명 전화번호 이메일 이우성 02-565-7740 wooslee@pcninc.co.kr 이혜원 02-565-7740 hwlee@pcninc.co.kr 저작도구 관련 문의처
저작도구 관련 문의처 담당자명 전화번호 이메일 이우성 02-565-7740 wooslee@pcninc.co.kr 이혜원 02-565-7740 hwlee@pcninc.co.kr
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기] [공용IRB 심의신청 가이드라인]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 safezone1@aihub.kr 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.
오프라인 데이터 이용 안내
본 데이터는 K-ICT 빅데이터센터에서도 이용하실 수 있습니다.
다양한 데이터(미개방 데이터 포함)를 분석할 수 있는 오프라인 분석공간을 제공하고 있습니다.
데이터 안심구역 이용절차 및 신청은 K-ICT빅데이터센터 홈페이지를 참고하시기 바랍니다.

국방데이터 개방 안내
본 데이터는 국방데이터로 군사 보안에 따라 AI허브에서 데이터를 제공하지 않으며,
군 담당자를 통한 별도의 사용 신청이 필요합니다.