※ 25년 신규 개방되는 데이터로, 데이터 활용성 검토, 이용자 관점의 개선의견 수렴 등을 통해 수정/보완될 수 있으며 최종데이터, 샘플데이터, 산출물 등은 변경될 수 있습니다.
-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.0 2025-04-16 데이터 개방 Beta Version 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2025-04-16 산출물 전체 공개 소개
● 19-34. 자연 발화 동영상 - 인체 3D 포즈 데이터 - 모션 및 포즈 관련 디지털 콘텐츠 제작과 3D 애니메이션 분야에서 인공지능 활용을 위한 [자연발화 동영상] 및 [발화 음성 데이터] 각 120,000건, [표정, 포즈 모션 데이터] 각 12,000건 또한 [표정, 포즈 3D 스캐닝 데이터] 각 360,000건과 [오디오 스크립트 및 디스크립션] 232,094건 구성
구축목적
● 19-34. 자연 발화 동영상 - 인체 3D 포즈 데이터 - 모션 및 포즈 관련 디지털 콘텐츠 제작과 3D 애니메이션 분야에서 인공지능 활용
-
메타데이터 구조표 데이터 영역 영상이미지 데이터 유형 3D 데이터 형식 .mp4, .wav, .fbx 데이터 출처 자체수집 라벨링 유형 영상 및 음성 설명(캡셔닝 디지털 파일) 라벨링 형식 .json 데이터 활용 서비스 - 3D 애니메이션, 영상 업체 등 콘텐츠 제공 업체에서의 3D 얼굴 및 포즈 데이터를 활용한 콘텐츠 생성 - 디지털 데이터를 활용한 연기 교육 자료로 활용 - 댄스, 안무 작가와 인공지능 모델의 협업을 통한 작품 활동 - 메타버스 내 캐릭터 모션 추가 및 관련 아이템 개발 데이터 구축년도/
데이터 구축량2024년/1)원천데이터 - [영상 데이터] 232,094건 - [음성 데이터] 124,094건 - [모션 캡쳐(페이셜)] 12,000건 - [모션 캡쳐(포즈)] 12,000건 - [3D 모델 데이터(페이셜)] 438.766건 - [3D 모델 데이터(포즈)] 440,017건 2) 라벨링(가공) 데이터 - 텍스트 : 라벨링+메타(JSON) : 232,094건 -
가. 데이터 구축 수량
데이터 구축 수량 상세 구분 수집량(건) 자연발화 동영상(MP4) 232,094 자연 발화 음성(WAV) 124,094 표정 모션 캡쳐 데이터(FBX) 12,000 포즈 모션 캡쳐 데이터(FBX) 12,000 표정 스캐닝 3D 모델(FBX) 438,766 포즈 스캐닝 3D 모델(FBX) 440,017 라벨링 데이터
(라벨링+메타(JSON))232,094(총 19,472,748 토큰) 나. 어노테이션 및 메타데이터 분포
- 원천데이터
어노테이션 및 메타데이터 분포-원천데이터 구분 1차 경로 2차 경로 3차 경로 4차 경로 5차 경로 포맷 목표 수량 원천
데이터모션캡처
(페이셜)A01 - - FBX 300건 A02 - - FBX 300건 ...(중략)... A39 - - FBX 300건 A40 - - FBX 300건 소 계 12,000건 모션캡처
(포즈)A01 - - FBX 300건 A02 - - FBX 300건 ...(중략)... A39 - - FBX 300건 A40 - - FBX 300건 소 계 12,000건 소 계(모션캡쳐) 24,000건 3D모델
데이터
(페이셜)A01 - - FBX 10,179건 A02 - - FBX 10,033건 ...(중략)... A39 - - FBX 10,650건 A40 - - FBX 12,243건 소 계 438,766건 3D모델
데이터
(포즈)A01 - - FBX 10,177건 A02 - - FBX 10,011건 ...(중략)... A39 - - FBX 10,680건 A40 - - FBX 11,975건 소 계 440,017건 소 계(3D 모델 데이터) 878,783건 영상
데이터A01~A40 A01SC01 A01SC01_001 A01SC01_001_cam01 mp4 10건 A01SC01_002 A01SC01_002_cam01 mp4 10건 A01SC01_003 A01SC01_003_cam01 mp4 10건 A01SC01_004 A01SC01_004_cam01 mp4 10건 A01SC01_005 A01SC01_005_cam01 mp4 10건 A01SC02 A01SC02_001 A01SC02_001_cam01 mp4 10건 A01SC02_002 A01SC02_002_cam01 mp4 10건 A01SC02_003 A01SC02_003_cam01 mp4 10건 A01SC02_004 A01SC02_004_cam01 mp4 10건 A01SC02_005 A01SC02_005_cam01 mp4 10건 ...(중략)... A01SC59 A01SC59_001 A01SC01_001_cam01 mp4 10건 A01SC59_002 A01SC01_002_cam01 mp4 10건 A01SC59_003 A01SC01_003_cam01 mp4 10건 A01SC59_004 A01SC01_004_cam01 mp4 10건 A01SC59_005 A01SC01_005_cam01 mp4 10건 A01SC60 A01SC60_001 A01SC02_001_cam01 mp4 10건 A01SC60_002 A01SC02_002_cam01 mp4 10건 A01SC60_003 A01SC02_003_cam01 mp4 10건 A01SC60_004 A01SC02_004_cam01 mp4 10건 A01SC60_005 A01SC02_005_cam01 mp4 10건 ...(중략)...40명까진 동일 반복 소 계 120,000건 A42~A422 A42SC01 - mp4 12건 A42SC02 - mp4 12건 A42SC03 - mp4 12건 A42SC04 - mp4 12건 A42SC05 - mp4 12건 ...(중략)... A422SC26 - mp4 12건 A422SC27 - mp4 12건 A422SC28 - mp4 12건 A422SC29 - mp4 12건 A422SC30 - mp4 12건 소 계 112,094건 소 계(영상데이터) 232,094건 음성
데이터A01~A40 A01SC01 A01SC01_001 wav 1건 A01SC01_002 wav 1건 A01SC01_003 wav 1건 A01SC01_004 wav 1건 A01SC01_005 wav 1건 A01SC02 A01SC02_001 wav 1건 A01SC02_002 wav 1건 A01SC02_003 wav 1건 A01SC02_004 wav 1건 A01SC02_005 wav 1건 ...(중략)... A01SC59 A01SC59_001 wav 1건 A01SC59_002 wav 1건 A01SC59_003 wav 1건 A01SC59_004 wav 1건 A01SC59_005 wav 1건 A01SC60 A01SC60_001 wav 1건 A01SC60_002 wav 1건 A01SC60_003 wav 1건 A01SC60_004 wav 1건 A01SC60_005 wav 1건 ...(중략)...40명까진 동일 반복 소 계 12,000건 A42~A422 A42SC01 - wav 12건 A42SC02 - wav 12건 A42SC03 - wav 12건 A42SC04 - wav 12건 A42SC05 - wav 12건 ...(중략)... A422SC26 - wav 12건 A422SC27 - wav 12건 A422SC28 - wav 12건 A422SC29 - wav 12건 A422SC30 - wav 12건 소 계 112,094건 소 계(음성데이터) 124,094건 총 수량 1,259,971건 -라벨링데이터
어노테이션 및 메타데이터 분포-라벨링데이터 구분 1차 경로 2차 경로 3차 경로 4차 경로 포맷 목표 수량 라벨링데이터 A01~A40 A01SC01 A01SC01_001 A01SC01_001_cam01 json 10건 A01SC01_002 A01SC01_002_cam01 json 10건 A01SC01_003 A01SC01_003_cam01 json 10건 A01SC01_004 A01SC01_004_cam01 json 10건 A01SC01_005 A01SC01_005_cam01 json 10건 A01SC02 A01SC02_001 A01SC02_001_cam01 json 10건 A01SC02_002 A01SC02_002_cam01 json 10건 A01SC02_003 A01SC02_003_cam01 json 10건 A01SC02_004 A01SC02_004_cam01 json 10건 A01SC02_005 A01SC02_005_cam01 json 10건 ...(중략)... A01SC59 A01SC59_001 A01SC01_001_cam01 json 10건 A01SC59_002 A01SC01_002_cam01 json 10건 A01SC59_003 A01SC01_003_cam01 json 10건 A01SC59_004 A01SC01_004_cam01 json 10건 A01SC59_005 A01SC01_005_cam01 json 10건 A01SC60 A01SC60_001 A01SC02_001_cam01 json 10건 A01SC60_002 A01SC02_002_cam01 json 10건 A01SC60_003 A01SC02_003_cam01 json 10건 A01SC60_004 A01SC02_004_cam01 json 10건 A01SC60_005 A01SC02_005_cam01 json 10건 ...(중략)...40명까진 동일 반복 소 계 120,000건 A42~A422 A42SC01 - json 12건 A42SC02 - json 12건 A42SC03 - json 12건 A42SC04 - json 12건 A42SC05 - json 12건 ...(중략)... A422SC26 - json 12건 A422SC27 - json 12건 A422SC28 - json 12건 A422SC29 - json 12건 A422SC30 - json 12건 소 계 112,094건 소 계(영상데이터) 232,094건 -
-
AI 모델 상세 설명서 다운로드
AI 모델 상세 설명서 다운로드 AI 모델 다운로드Motion Generation – EMAGE Overview Motion Generation – EMAGE Overview 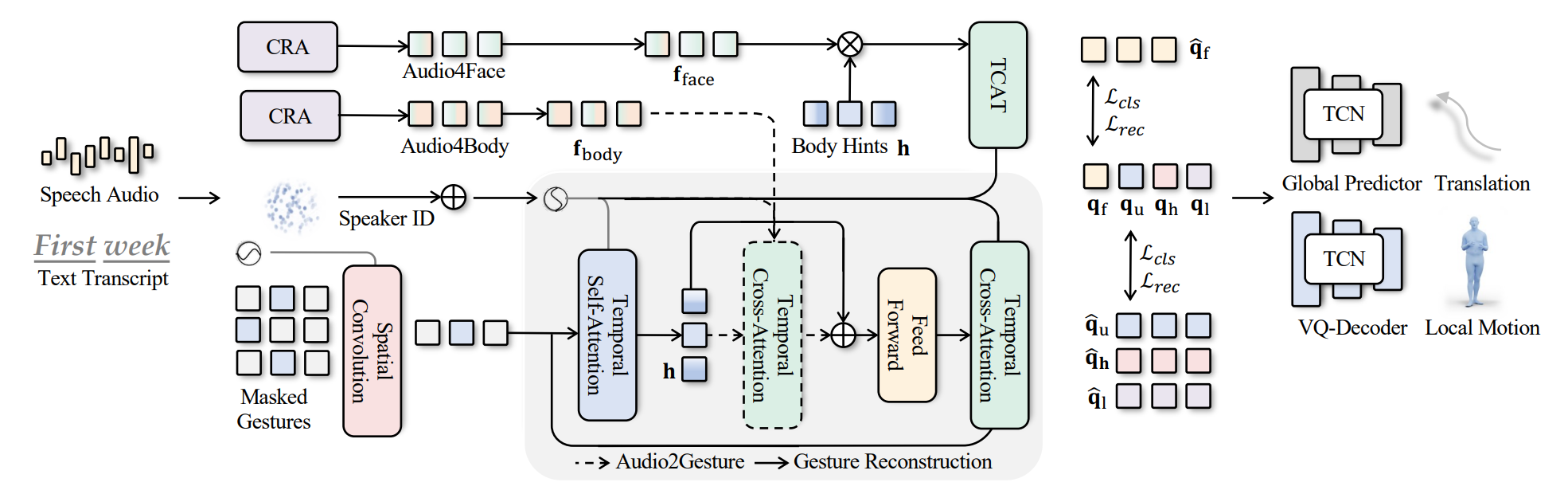
EMAGE의 아키텍쳐 EMAGE의 모델 아키텍처는 Masked Audio Gesture Transformer와 Compositional VQ-VAE 기반으로 구성되어 음성과 동기화된 전체적인 제스처를 생성하는 구조. 주요 입력은 관절 데이터와 음성 데이터로, 관절 데이터는 Rot6D 형식의 55개 관절 회전, FLAME 기반 얼굴 표현 매개변수, 발 접촉 레이블, 글로벌 변환 정보를 포함하며, 음성 데이터는 리듬(onset, amplitude)과 텍스트 임베딩을 분리하여 사용함.
Content Rhythm Attention(CRA) 모듈은 음성 데이터를 리듬과 내용으로 나누어 각각 Temporal Convolutional Network(TCN)와 사전 학습된 단어 임베딩을 통해 처리한 뒤, Self-Attention 메커니즘을 사용해 두 요소를 가중치 기반으로 결합하여 최적의 음성 피처를 생성함.
Masked Audio Gesture Transformer는 세 가지 주요 컴포넌트로 구성됨. 첫 번째는 Spatial Convolutional Encoder로, 관절 데이터를 공간적으로 압축하여 고차원 피처를 생성함. 두 번째는 Temporal Self-Attention으로, 시간 축에서 관절 피처의 연속성과 맥락 정보를 학습함. 마지막으로 Temporal Cross-Attention Decoder가 음성과 제스처 피처를 결합하여 잠재 공간을 재구성함. 이 구조는 마스킹된 입력을 복원(MG2G)하거나, 음성을 조건으로 새로운 제스처를 생성(A2G)하는 데 사용됨.
Compositional VQ-VAE 디코더는 얼굴, 상체, 손, 하체 데이터를 각각 분리하여 처리함. 이를 통해 각 부위의 특성을 세밀하게 반영하며, 하체 데이터를 기반으로 글로벌 변환과 이동 방향을 예측함. 분리된 VQ-VAE 구조는 신체 부위별 음성과의 연관성을 독립적으로 학습하여 높은 수준의 다양성과 정확성을 보장함.
EMAGE는 마스킹 비율을 점진적으로 증가시키며 학습함으로써 제스처 복원 성능을 강화하고, 크로스 어텐션 메커니즘을 통해 음성과 제스처 데이터를 효과적으로 융합함. 이러한 모듈화된 설계는 얼굴, 손, 신체 등의 움직임을 조화롭게 생성할 수 있도록 하며, 다양한 응용 도메인에서도 확장 가능성을 보여줌.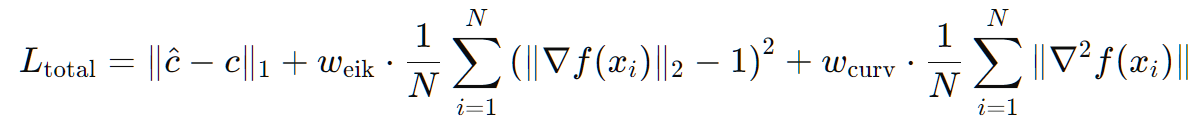
Loss Function EMAGE의 손실 함수 설계는 모델 학습을 최적화하고, 음성과 동기화된 자연스러운 제스처를 생성하도록 설계됨.
Masked Gesture Reconstruction Loss(MG2G Loss)는 마스킹된 제스처 데이터를 복원하는 역할을 하며, 잠재 공간에서 마스킹된 데이터와 원본 데이터 간의 L1 차이를 최소화하여 제스처의 공간적·시간적 구조를 학습함. Audio-Conditioned Gesture Loss(A2G Loss)는 음성을 조건으로 생성된 제스처의 일관성을 유지하도록 하며, 음성과 결합된 제스처 잠재 공간에서 복원 손실을 계산함. 이와 함께 VQ-VAE 코드북 분류 정확도를 높이기 위한 클래스 분류 손실도 추가적으로 활용함.
VQ-VAE 관련 손실은 얼굴, 상체, 손, 하체 등 신체의 각 부위를 독립적으로 학습하여 부위별 특성을 명확히 반영함. 복원 손실, 속도 손실, 가속도 손실을 포함하여 동작의 정확성과 부드러움을 동시에 보장하며, 커밋 손실을 통해 잠재 공간에서 코드 사용 균형을 유지함.
Global Motion Loss는 하체 데이터를 기반으로 글로벌 변환(위치 변화와 이동 방향)을 예측하는 데 사용됨. 사전 학습된 글로벌 모션 예측기를 통해 예측된 변환과 실제 글로벌 변환 간의 L1 차이를 최소화하며, 자연스러운 전신 움직임과 발 접촉 상태의 일관성을 학습함.
종합 손실은 MG2G Loss, A2G Loss, VQ-VAE Loss, Global Motion Loss를 가중 합산하여 최적의 학습 성능을 달성함. 각 손실 항목의 가중치는 특정 손실이 학습 과정에서 과도하게 지배하지 않도록 조정되며, 실험적으로 설정됨. 이러한 손실 설계를 통해 EMAGE는 음성과 조화를 이루는 자연스럽고 고품질의 제스처를 생성할 수 있도록 함.
H. Liu et al., "EMAGE: Towards Unified Holistic Co-Speech Gesture Generation via Expressive Masked Audio Gesture Modeling," arXiv preprint arXiv:2401.00374v5, 2024.
H. Liu et al., "BEAT: A Large-Scale Semantic and Emotional Multi-Modal Dataset for Conversational Gestures Synthesis," arXiv preprint arXiv:2203.05297, 2022.
G. Pavlakos et al., "Expressive Body Capture: 3D Hands, Face, and Body from a Single Image," in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019. -
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드가. 데이터 구성
- 원천데이터
1) 자연 발화 동영상 (MP4)
2) 자연 발화 음성 (WAV, MP4)
3) 표정 모션 캡쳐 데이터 (FBX)
4) 포즈 모션 캡쳐 데이터 (FBX)
5) 표정 스캐닝 3D 모델 (FBX)
6) 포즈 스캐닝 3D 모델 (FBX)- 라벨링 데이터
텍스트 : 통합 데이터(라벨링+메타(JSON))나. 어노테이션 포맷
어노테이션 포맷 구분 속성명 타입 필수 여부 설명 범위 비고 1 dataset object Y 1-1 dataset.emotion string Y 감정 1-2 dataset.emotion_detail string Y 세부 감정 1-3 dataset.3d_path string Y 2 actor object Y 2-1 actor.id number Y 배우 id 2-2 actor.age_group number Y 배우 나이 분류 0: 10대 1: 20대 2: 30대 3: 40대 이상 2-3 actor.hometown string Y 배우 출신 지역 2-4 actor.gender string Y 배우 성별 m: 남자 f: 여자 3 annotations object Y 3-1 annotations.script string Y 비디오 스크립트(한글) 3-2 annotations.caption string Y 비디오 캡션(한글) 3-3 annotations.pose_caption string N 모션캡쳐 포즈 캡션(영어) 3-4 annotations.facial_caption string N 모션캡쳐 표정 캡션(영어) 4 video object Y 4-1 video.filename string Y 발화 영상 파일 이름 4-2 video.frames number Y 발화 영상 초 당 프레임 수 0~ 4-3 video.duration number Y 발화 영상 길이 0~ s 단위 5 motion object N 5-1 motion.filename array N 포즈 모캡 파일 이름 5-2 motion.frames number N 포즈 모캡 초 당 프레임 수 0~ 5-3 motion.duration number N 포즈 모캡 길이 0~ s 단위 6 facial object N 6-1 facial.filename array N 표정 모캡 파일 이름 6-2 facial.frames number N 표정 모캡 초 당 프레임 수 0~ 6-3 facial.duration number N 표정 모캡 길이 0~ s 단위 다. 데이터 포맷(JSON 예시)
{
"dataset": {
"emotion": "anger",
"emotion_detail": "삐뚤어지다",
"3d_path": "/A01"
},
"actor": {
"id": 1,
"age_group": 2,
"hometown": "서울경기",
"gender": "m"
},
"annotations": {
"script": "엄마 진짜 왜 나만 핸드폰 안 사줘 친구들 다 좋은 핸드폰 가지고 있는데 나만 없으니까 너무 창피하단 말이야 엄마 말대로 공부 열심히 해서 성적도 올렸잖아 근데 왜 나만 이런 대우를 받아야 돼 나도 똑같이 노력했는데 맨날 저런 거 하나 못 가져 엄마가 자꾸 이러면 나도 그냥 막 나갈 거야",
"pose_caption": "Stands with weight on one leg and glares. Pounds the chest with one hand. Spreads both arms and stretches the neck forward.",
"facial_caption": "Frown while slightly pouting your lower lip.",
"video_caption": "30대의 남자가 자신의 핸드폰 구매 요구에 대해, 친구들과 비교하며 억울함과 좌절감을 표현한다."
},
"video": {
"filename": "A01SC02_002_cam02.mp4",
"frames": 60.0,
"duration": 34.383208333333336
},
"motion": {
"filename": "A01SC02_002_P.fbx",
"frames": 60.0,
"duration": 34.383208333333336
},
"facial": {
"filename": "A01SC02_002_F.fbx",
"frames": 60.0,
"duration": 34.383208333333336
} -
데이터셋 구축 담당자
수행기관(주관) : 한국딥러닝(주)
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 천효창 파트장 070-8805-2612 hcc@koreadeep.com 데이터 품질관리 총괄 수행기관(참여)
수행기관(참여) 기관명 담당업무 플필 - 배우섭외 및 스케줄링 (플필)
- 개인정보 및 권리확보 (플필)
- 스크립트 전달 및 안내 (플필)모션테크놀로지스 - 데이터 클렌징 (이상치, 결측치 제거)
- 스캐닝 3d 데이터 제작 및 개인정보 비식별화, 중복제거
- 모션 및 발화영상 촬영 (모션테크놀로지스)데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 정선희 070-8805-2612 shj@koreadeep.com AI모델 관련 문의처
AI모델 관련 문의처 담당자명 전화번호 이메일 정선희 070-8805-2612 shj@koreadeep.com 저작도구 관련 문의처
저작도구 관련 문의처 담당자명 전화번호 이메일 정선희 070-8805-2612 shj@koreadeep.com
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기] [공용IRB 심의신청 가이드라인]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 safezone1@aihub.kr 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.
오프라인 데이터 이용 안내
본 데이터는 K-ICT 빅데이터센터에서도 이용하실 수 있습니다.
다양한 데이터(미개방 데이터 포함)를 분석할 수 있는 오프라인 분석공간을 제공하고 있습니다.
데이터 안심구역 이용절차 및 신청은 K-ICT빅데이터센터 홈페이지를 참고하시기 바랍니다.

국방데이터 개방 안내
본 데이터는 국방데이터로 군사 보안에 따라 AI허브에서 데이터를 제공하지 않으며,
군 담당자를 통한 별도의 사용 신청이 필요합니다.