BETA 멀티모달 정보검색 데이터
- 분야영상이미지
- 유형 텍스트 , 이미지
- 생성 방식LMM
※ 25년 신규 개방되는 데이터로, 데이터 활용성 검토, 이용자 관점의 개선의견 수렴 등을 통해 수정/보완될 수 있으며 최종데이터, 샘플데이터, 산출물 등은 변경될 수 있습니다.
-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.0 2025-04-16 데이터 개방 Beta Version 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2025-04-16 산출물 전체 공개 소개
● 다양한 유형의 정보(텍스트, 시각요소 등)로 구성된 문서의 내용을 자동 요약하고 검색할 수 있는 서비스를 제공하기 위한 데이터
구축목적
● 문서의 내용을 인공지능(AI)으로 분석하기 위해 문서 내에 텍스트요소와 시각요소 라벨링과 문서의 형식과 레이아웃에 대해 캡션 가공하여 AI가 학습 할 수 있도록 학습용 데이터를 구축함
-
메타데이터 구조표 데이터 영역 영상이미지 데이터 유형 텍스트 , 이미지 데이터 형식 PDF, JPG, TXT 데이터 출처 ‘공공데이터포털’ 및 ‘대한민국 정책브리핑’ 등의 민간에 개방된 공공데이터 수집처 활용 라벨링 유형 바운딩박스(이미지, 자연어), 캡션(이미지, 자연어) 라벨링 형식 JSON 데이터 활용 서비스 문서정보 검색 엔진 솔루션 및 요약, 검색 활용 교육자료 개발 데이터 구축년도/
데이터 구축량2024년/원천데이터(PDF) : 20,123개 | 원천데이터(TXT) : 75,684개 | 원천데이터(JPG) : 75,684개 | 라벨링데이터(JSON) : 75,684개 -
● 데이터 구축 규모
● 데이터 구축 규모 파일 포맷 데이터 규모 데이터 정의 원천데이터(PDF) 20,123개 • 기존 원천데이터를 의미하며, 원시데이터를 정제 후 생성된 pdf 형식 문서 원천데이터(TXT) 75,684개 • 원천데이터의 문맥 데이터 원천데이터(JPG) 75,684개 • 원천데이터(pdf) 내 각각의 페이지를 분할한 이미지(jpg) 문서 라벨링데이터(JSON) 75,684개 • 바운딩박스(시각요소, 텍스트요소)
• 캡션(설명문 요소)● 데이터 분포
● 데이터 분포 항목명 결과 공공 민간 분포
(원천데이터)구분 수량 비율 공공기관 60,346 79.73% 민간기관 15,338 20.27% 합계 75,684 100% 파일 형식 분포
(원시데이터)포맷 원시데이터 수량
(단위 : 페이지)비율 hwp 71,753 94.81% pdf 3,931 5.19% 합계 75,684 100% 포맷 원천데이터 수량
(단위 : 문서)비율 pdf 20,123 100% 합계 20,123 100% visual_context
길이 분포어절 수량 비율 49 어절 이하 19,254 25.44% 50~59 어절 5,350 7.07% 60~69 어절 5,314 7.02% 70~79 어절 5,007 6.62% 80 어절 이상 40,759 53.85% 합계 75,684 100% visual_insruction
길이 분포어절 수량 비율 4 어절 이하 7,005 6.94% 5~9 어절 76,268 75.58% 10~14 어절 15,839 15.70% 15~19 어절 1,540 1.53% 20 어절 이상 262 0.26% 합계 100,914 100% visual_answer
길이 분포어절 수량 비율 9 어절 이하 4 0% 10~19 어절 4 0% 20~29 어절 5,438 5.39% 30~39 어절 53,135 52.65% 40 어절 이상 42,333 41.95% 합계 100,914 100% 인스턴스 유형 분포 문서 유형 인스턴스 유형 수량 비율 텍스트 C01 본문 234,215 36.65% C02 목록 14,714 2.24% I01 발행정보 625 0.10% L01 머리말 17,373 2.64% L02 꼬리말 25,995 3.96% L03 페이지번호 53,184 8.09% T01 제목 8,344 1.27% T02 소제목 95,429 14.52% T03 시각요소 제목 106,723 16.24% 시각
요소V01 표 40,197 6.12% V02-1 차트(세로막대형) 12,071 1.84% V02-2 차트(가로막대형) 1,571 0.24% V02-3 차트(원형) 2,228 0.34% V02-4 차트(꺾은선형) 23,431 3.57% V02-5 차트(영역형) 577 0.09% V02-6 차트(분산형) 388 0.06% V02-7 차트(방사형) 176 0.03% V02-8 차트(혼합형) 16,771 2.55% V03 다이어그램 2,999 0.46% 합계 657,011 100% 문서 유형 분포 분야 수량 결과 구성비 보고서 57,372 75.80% 보도자료 18,312 24.20% 합계 75,684 100% 레이아웃 유형 분포 어절 수량 결과 구성비 Type-1 텍스트+표 18,190 24.03% Type-2 텍스트+차트 19,821 26.19% Type-3 텍스트+ 17,502 23.13% 다이어그램 Type-4 텍스트+ 20,171 26.65% 2가지 시각요소 합계 75,684 100% 시각요소 캡션 분포 분야 수량 결과 구성비 표 40,197 40.03% 차트 57,213 56.98% 다이어그램 2,999 2.99% 합계 100,409 100% -
-
AI 모델 상세 설명서 다운로드
AI 모델 상세 설명서 다운로드 AI 모델 다운로드● VGT
Task • 탐지(Detection) • Document Layout Analysis 알고리즘 개요 • Vision Grid Transformer
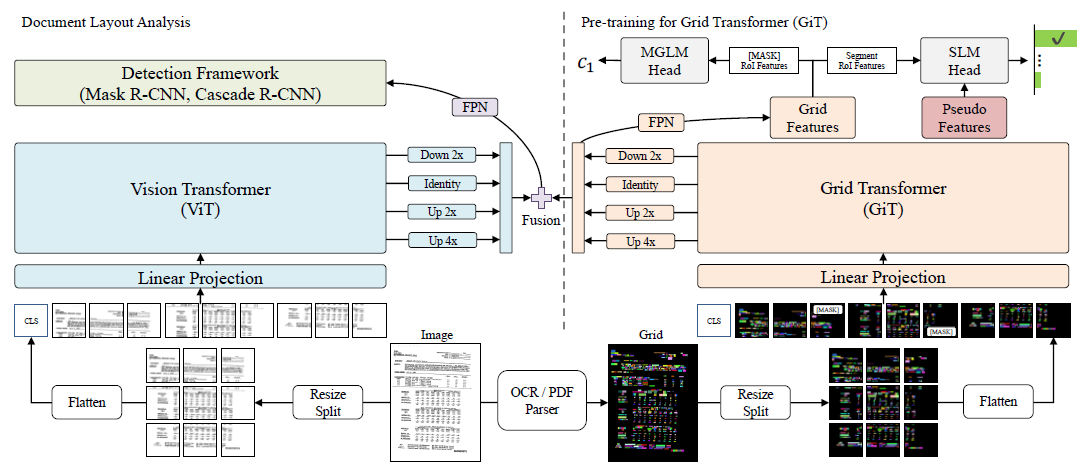
모델 입출력 • 입력 : 문서 페이지 이미지 • 출력 : 페이지 내에서 탐지된 레이아웃 요소의 바운딩 박스 모델 설명 • Vision Transformer(ViT)와 Grid Transformer(GiT)의 two-stream 구조를 가져 손실되는 정보가 적다는 장점이 있음 • MGLM(Masked Grid Language Modeling), SLM(Segment Language Modeling) 방법으로 사전 학습하여 과적합 문제에 상대적으로 자유롭고 학습량이 많지 않을 때도 높은 성능을 보임 • FPN(Feature Pyramid Network)를 통한 다중 스케일의 멀티모달 특징을 추출하여 다양한 크기의 레이아웃 요소를 효과적으로 처리 서비스 활용 시나리오 • 문서 내에 존재하는 레이아웃 요소를 탐지하여 다양한 서비스로 연계할 수 있으며, 대표적으로는 OCR 및 레이아웃 순서 파악을 통한 문서 파싱, 레이아웃 요소 배치에 기반한 문서 종류 판단 등이 가능 • 과제에서 전제하고 있는 멀티모달 정보검색 시나리오의 경우, 탐지된 요소들 중 이미지 요소만 추출한 뒤 근처의 텍스트 요소와 결합하여 검색에 사용되기 용이한 형태로 문서 데이터를 변환할 수 있음 ● InternVL2
Task • 생성(Generation) • Figure Description Generation 알고리즘 개요 • InternVL2
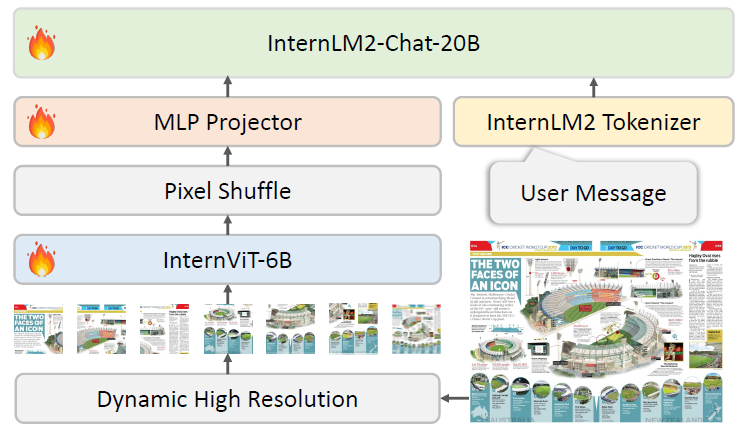
모델 입출력 • 입력 : 시각 요소의 이미지, 시각 요소와 연관된 텍스트 정보, 설명 생성 지시문 • 출력 : 생성된 시각 요소의 설명문 모델 설명 • 시각 처리와 언어 처리의 two-stream 구조를 가지며, 시각 처리는 InternViT 구조, 언어 처리는 InternLM, Llama-3 등을 기반 • 모델에 입력되는 이미지의 종횡비와 해상도에 따라 1~40개의 448x448 픽셀 타일로 분할하여 최대 4K 해상도를 지원하는 동적 고해상도 방식을 채택하여 차트 분석 및 인포그래픽 해석 등의 분야에서의 성능을 향상. 서비스 활용 시나리오 • 사용자로부터 이미지 및 텍스트 입력을 받아 캡션을 생성할 수 있으며, Document Layout Analysis 모델과 연계하여 문서 페이지를 입력받았을 때 탐지된 시각 요소에 대한 캡션을 자동 생성하는 확장 등 가능 • 또한 Multimodal RAG와 연계하여 사용자로부터 검색 지시문을 입력받았을 때 가장 연관있는 시각 요소를 인출한 후 설명문을 생성하여 반환할 수 있음 -
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드● 어노테이션 포맷
● 어노테이션 포맷 번호 항목명 타입 필수
여부설명 범위 예시 1. raw_data_info 1.1 raw_data_name string Y 원시데이터명 - “MI1_240808_TY2_0292.hwp” 1.2 doc_name string Y 문서 제목/주제 - “금융기관 대출행태서베이 2023년 4/4분기 동향 및 2024년 1/4분기 전망“ 1.3 date string Y 원시데이터 수집 일자 - “240808” 1.4 doc_type string Y 문서 분류 “보고서”, “보도자료”, “보고서” 1.5 format string Y 문서 포맷 유형 “hwp”, “hwpx”, “pdf” 1.6 copyright string Y 수집처 “미디어그룹사람과숲” “미디어그룹사람과숲” 1.7 organ_type string Y 공공 민간 구분 “공공기관”. “민간기관” “공공기관” 1.8 publisher string Y 발행처 - “한국은행” 2. source_data_info 2.1 source_data_name_pdf string Y 원천데이터 파일명 - MI2_240808_TY2_0292.pdf“ 2.2 source_data_name_txt string Y 문맥데이터 파일명 - MI2_240808_TY2_0292.txt“ 2.3 source_data_name_jpg string Y 원천데이터(이미지)파일명 - MI2_240808_TY2_0292_1.jpg“ 2.4 document_resolution array Y 원시추출페이지 [2480, 3508] [2480, 3508] 3. learning_data_info 3.1 learning_data_name string Y 라벨링데이터명 - “MI3_240808_TY2_0292_1.json” 3.2 page_num string Y 원천페이지 번호 “1”~“9” “1” 3.3 visual_context string Y 시각요소 문맥 (현재 페이지 전문) “국내은행 2024년 1/4분기중 국내은행의 대출태도는…(중략)” 3.4 type_id string Y 원천데이터 타입 ID “Type-01”, “Type-02”, “Type-03”, “Type-04”, “Type-01” 3.5 type_name string Y 원천데이터 타입명 “텍스트+표”, “텍스트+차트”, “텍스트+다이어그램”, “텍스트+2가지 시각요소” “텍스트+표” 3.6 annotation array Y - - - 3.6.1 class_id string Y 객체 아이디 “T01”, “T02”, “T03”, “C01”, “C02”, “L01”, “L02”, “L03”, “I01”, “V01”, “V02-1”,“V02-2”, “V02-3”,“V02-4”,“V02-5”,“V02-6”, “V02-7”,“V02-8” “V03” “T01” 3.6.2 instance_id string Y 라벨링데이터 인스턴스 ID(데이터ID_수집일자_문서 분류_원천문서번호_ 페이지정보_객체ID_인스턴스 번호) - “MI3_240725_TY2_0001_2_L02_2” 3.6.3 class_name string Y 라벨링데이터 클래스 명 “제목”, “소제목”, “시각요소 제목”, “본문”, “목록”, “머리말”, “꼬리말”, “페이지번호”, “발행정보”, “표”, “차트(세로막대형)”, “차트(가로막대형), ” “차트(원형)”, “차트(꺾은선형)”, “차트(영역형)”, “차트(분산형)”, “차트(방사형)”, “차트(혼합형)”, “다이어그램” “제목” 3.6.4 bounding_box array Y 바운딩박스 좌표. [x,y,w,h] 형식으로 기입 - [277, 1925, 684, 89]] 3.6.5 visual_instruction string N 시각요소 지시문(질문)
(시각요소에만 프로퍼티 존재)- “금융기관 대출행태 서베이…(중략)설명해주세요” 3.6.6 visual_answer string N 시각요소 답변문
(시각요소에만 프로퍼티 존재)- “국내은행 차주별 대출행태 지수를 …(중략) 다소 완화로 전망된다.” ● 어노테이션 예시
{
"raw_data_info": {
"raw_data_name": "MI1_240808_TY2_0292.hwp",
"doc_name": "금융기관 대출행태서베이 2023년 4/4분기 동향 및 2024년 1/4분기 전망",
"date": "240808",
"doc_type": "보도자료",
“format”: “hwp”
"copyright": "미디어그룹사람과숲",
"publisher": "한국은행“
"organ_type": "공공기관",
},
"source_data_info": {
"source_data_name_pdf": "MI2_240808_TY2_0292.pdf",
"source_data_name_txt": "MI2_240808_TY2_0292.txt",
"source_data_name_jpg": "MI2_240808_TY2_0292_1.jpg",
"document_resolution": [2480, 3508],
},
"learning_data_info": {
"learning_data_name": "MI3_240808_TY2_0292_1.json",
"page_num": "1",
"visual_context": "< 요 약 > Ⅰ 국내은행 2024년 1/4분기중 국내은행의 대출태도는 기업 및 가계 모두 다소 완화로 전망 신용위험은 기업 및 가계 모두 높은 수준을 지속할 것으로 예상 대출수요는 기업 및 가계주택은 증가, 가계일반은 보합 수준으로 전망 국내은행 1) 차주별 대출행태지수 2 ##MI3_240808_TY2_0292_1_V01_1## Ⅱ 비은행금융기관 2024년 1/4분기중 비은행금융기관의 대출태도는 대체로 강화 기조 가 유지될 전망 신용위험은 모든 업권에서 높은 수준을 지속할 것으로 예상 대출수요는 모든 업권에서 증가할 것으로 전망 비은행금융기관 1) 대출행태지수 2,3) ##MI3_240808_TY2_0292_1_V01_2##",
"type_id": "Type-04",
"type_name": "텍스트+2가지 시각요소",
"annotation": [
{
"class_id": "T02",
"instance_id": "MI3_240808_TY2_0292_1_T02_1",
"class_name": "소제목",
"bounding_box": [
287,
282,
1161,
213
]
},
{
"class_id": "C02",
"instance_id": "MI3_240808_TY2_0292_1_C02_1",
"class_name": "목록",
"bounding_box": [
277,
525,
1935,
550
]
},
{
"class_id": "T03",
"instance_id": "MI3_240808_TY2_0292_1_T03_1",
"class_name": "시각요소 제목",
"bounding_box": [
848,
1131,
749,
84
]
},
{
"class_id": "V01",
"instance_id": "MI3_240808_TY2_0292_1_V01_1",
"class_name": "표",
"bounding_box": [
282,
1235,
1940,
590
],
"visual_instruction": "금융기관 대출행태 서베이 2023년 4/4분기 동향 및 2024년 1/4분기 전망의 국내은행 차주별 대출행태지수에 관한 표에 대해 설명해 주세요",
"visual_answer": "국내은행 차주별 대출행태지수를 대기업, 중소기업, 가계주택, 가계일반으로 나누고 대출태도, 신용위험, 대출수요로 구분하여 나타낸 표이다. 2024년 1/4분기중 국내은행의 대출태도는 기업 및 가계 모두 다소 완화로 전망된다."
},
{
"class_id": "T02",
"instance_id": "MI3_240808_TY2_0292_1_T02_2",
"class_name": "소제목",
"bounding_box": [
277,
1925,
684,
89
]
},
{
"class_id": "C02",
"instance_id": "MI3_240808_TY2_0292_1_C02_2",
"class_name": "목록",
"bounding_box": [
272,
2064,
1945,
481
]
},
{
"class_id": "T03",
"instance_id": "MI3_240808_TY2_0292_1_T03_2",
"class_name": "시각요소 제목",
"bounding_box": [
858,
2604,
764,
79
]
},
{
"class_id": "V01",
"instance_id": "MI3_240808_TY2_0292_1_V01_2",
"class_name": "표",
"bounding_box": [
253,
2704,
1979,
585
],
"visual_instruction": "금융기관 대출행태 서베이 2023년 4/4분기 동향 및 2024년 1/4분기 전망의 비은행금융기관 대출행태지수에 관한 표에 대해 설명해 주세요",
"visual_answer": "비은행금융기관 대출행태지수를 상호저축은행, 상호금융조합, 신용카드회사, 생명보험회사로 나누고 대출태도, 신용위험, 대출수요로 구분하여 나타낸 표이다. 2024년 1/4분기중 비은행금융기관의 대출태도는 대체로 강화 기조가 유지될 전망이다."
}
]
}
} -
데이터셋 구축 담당자
수행기관(주관) : ㈜미디어그룹사람과숲
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 정용운 02-830-8583 wjdddyddns@humanf.co.kr 데이터 수집, 정제, 검수 수행기관(참여)
수행기관(참여) 기관명 담당업무 솔트룩스이노베이션 데이터 가공 써로마인드 AI 모델 학습 및 유효성 검증 데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 ㈜미디어그룹사람과숲 정용운 이사 02-830-8583 wjdddyddns@humanf.co.kr AI모델 관련 문의처
AI모델 관련 문의처 담당자명 전화번호 이메일 ㈜써로마인드 김서윤 02-872-5127 sykim@surromind.ai ㈜써로마인드 류제환 02-872-5127 jhryu@surromind.ai 저작도구 관련 문의처
저작도구 관련 문의처 담당자명 전화번호 이메일 ㈜미디어그룹사람과숲 정용운 이사 02-830-8583 wjdddyddns@humanf.co.kr
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기] [공용IRB 심의신청 가이드라인]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 safezone1@aihub.kr 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.
오프라인 데이터 이용 안내
본 데이터는 K-ICT 빅데이터센터에서도 이용하실 수 있습니다.
다양한 데이터(미개방 데이터 포함)를 분석할 수 있는 오프라인 분석공간을 제공하고 있습니다.
데이터 안심구역 이용절차 및 신청은 K-ICT빅데이터센터 홈페이지를 참고하시기 바랍니다.

국방데이터 개방 안내
본 데이터는 국방데이터로 군사 보안에 따라 AI허브에서 데이터를 제공하지 않으며,
군 담당자를 통한 별도의 사용 신청이 필요합니다.