BETA 오피스 문서 생성 데이터
- 분야영상이미지
- 유형 텍스트 , 이미지
- 생성 방식LMM
※ 25년 신규 개방되는 데이터로, 데이터 활용성 검토, 이용자 관점의 개선의견 수렴 등을 통해 수정/보완될 수 있으며 최종데이터, 샘플데이터, 산출물 등은 변경될 수 있습니다.
-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.0 2025-04-16 데이터 개방 Beta Version 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2025-04-16 산출물 전체 공개 소개
● 다양한 오피스 문서의 의도된 구조와 내용을 이해하고, 이를 활용하여 문서 작업을 효율화하기 위한 데이터
구축목적
● 초거대AI를 활용한 AI 산업의 흐름에 발맞춰 생성형 문서 데이터 구축 필요 ● 고품질·대규모 AI 데이터 구축·개방하여 초거대AI 모델 구축·활용 계획 실현
-
메타데이터 구조표 데이터 영역 영상이미지 데이터 유형 텍스트 , 이미지 데이터 형식 PDF, JPG 데이터 출처 ‘공공데이터포털’ 및 ‘대한민국 정책브리핑’ 등의 민간에 개방된 공공데이터 수집처 활용 라벨링 유형 바운딩박스(이미지, 자연어), 캡션(이미지, 자연어) 라벨링 형식 JSON 데이터 활용 서비스 다양한 오피스 문서의 의도된 구조와 내용을 이해하고, 이를 활용하여 문서 작업을 효율화하기 위한 데이터 데이터 구축년도/
데이터 구축량2024년/원천데이터(PDF) : 10,261개 | 원천데이터(JPG) : 47,072개 | 라벨링데이터(JSON) : 300,477개 -
● 데이터 구축 규모
데이터 구축 규모 파일 포맷 데이터 규모 데이터 정의 원천데이터(PDF) 10,261개 다양한 오피스 문서의 공통 변환 문서 원천데이터(JPG) 47,072개 라벨링 데이터 학습을 위한 오피스 문서 내 각 페이지 이미지 변환 문서 라벨링데이터(JSON) 300,477개 바운딩박스(시각요소, 텍스트요소) 캡션(설명문 요소) ● 데이터 분포
데이터 분포 항목명 결과 파일 형식 분포(원시데이터) 포맷 (원시) 원천 수량 비율 pdf 7,385 79.98% hwp 2,595 14.69% ppt 281 4.88% pptx 0.46% 합계 10,261 100% 텍스트요소
(안내문 요소),
시각요소 분포요소 비율 텍스트 요소 / 설명문(안내문) 70% 시각 요소 30% 합계 100% 시각요소 설명문
길이 분포어절 수량 비율 5어절 이하 28,717 37.30% 6~10어절 37,372 48.54% 11~15어절 8,292 10.77% 16어절 이상 2,604 3.38% 합계 76,985 100% 시각요소 설명문
총 어절 수총 553,547어절 레이아웃 설명문
길이 분포어절 수량 비율 5어절 이하 0 0% 6~10어절 18,132 38.52% 11~15어절 22,974 48.81% 16어절 이상 5,966 12.67% 합계 47,072 100% 레이아웃 설명문
총 어절 수총 557,840어절 공공/민간 분야
분포분야 라벨링 수량 비율 공공 분야 202,420 67.37% 민간 분야 98,057 32.63% 합계 300,477 100% 문서 유형 분포
(원천데이터)문서유형 데이터 비율 원천 라벨링 보고서 설명형 2,934 54,007 55.40% 목록형 2,825 112,443 보도
자료보도자료 1,595 27,273 11.73% 뉴스기사 1,000 7,978 발표
자료프리젠
테이션907 81,931 27.27% 행정문서 결제형 500 3,227 5.60% 계약형 500 13,618 합계 10,261 300,477 100% 레이아웃 안내문
비율 분포1:01:00 AM
(문서 페이지 수 : 47,072
레이아웃안내문 수 : 47,072)클래스 분포 구분 id 수량 비율 설명문
(안내문)레이아웃
안내문47,072 15.67% 15.67% 텍스트
요소주제목 10,020 3.33% 58.71% 부제목 1,536 0.51% 본문 55,905 18.61% 목록 108,959 36.26% 시각
요소표 13,648 4.54% 25.62% 차트 19,421 6.46% 다이어그램 2,099 0.70% 사진 20,831 6.93% 일러스트 20,986 6.98% 합계 300,477 100% 100% -
-
AI 모델 상세 설명서 다운로드
AI 모델 상세 설명서 다운로드 AI 모델 다운로드● 모델학습
- 모델은 Gemma2-9b와 SigLIP으로 구성된 LLaVA로, 558,000건의 이미지 설명문 쌍 데이터로 시각 사전학습된 모델을 활용
- 시각 사전 학습 시 LLM과 Vision Encoder의 weight는 업데이트 하지 않고 Projector만 갱신
- 이후 미세조정에서 Projector와 vision encoder의 weight는 업데이트 하지 않으며 LLM의 weight만 업데이트
- 미세조정엔 제작업체에서 건내받은 16,574개의 레이아웃 안내문이 포함된 데이터와 89,863개의 레이아웃 안내문이 포함되지 않은 데이터로 수행
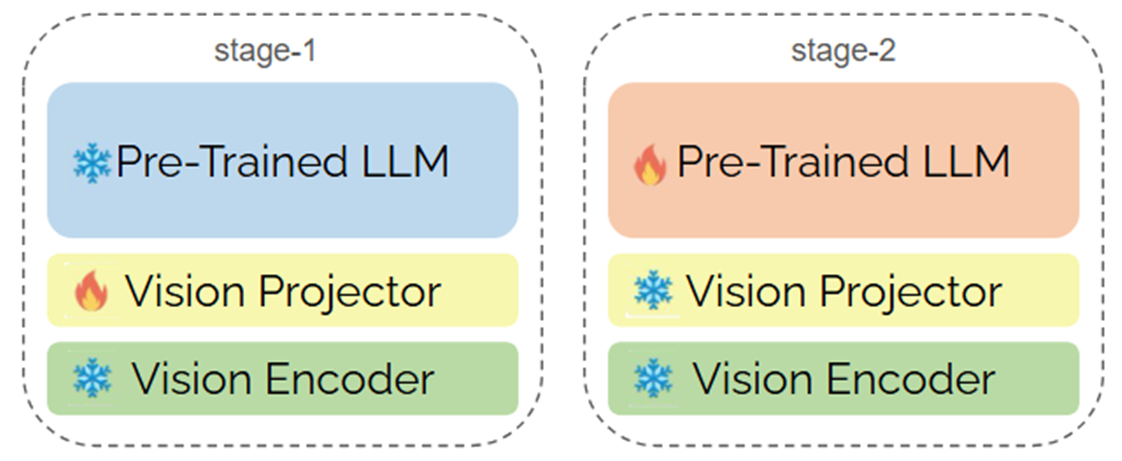
<모델 학습 개요> -
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드● 어노테이션 포맷
어노테이션 포맷 구분 속성명 타입 필수여부 설명 예시 1 raw_data_info 1-1 doc_name string Y 원시데이터 제목/주제 “영란은행, 코로나19 사태 대응 추가대책 발표 및 시장반응” 1-2 date string Y 원시데이터 수집일자 “240813“ 1-3 doc_type string Y 문서 유형 “보고서(목록형)” 1-4 format string Y 문서 포맷 “pdf” 1-5 page_direction string Y 문서 방향 “vertical” 1-6 copyright string Y 저작권 “미디어그룹사람과숲” 1-7 organ_type string Y 공공 민간 구분 “공공기관” 1-8 publisher string Y 발행처 “한국은행” 2 source_data_info 2-1 raw_data_name string Y 원문데이터 파일명 "OC1_240813_TY1-2_0002.pdf" 2-2 source_data_name_pdf string Y 원천데이터 파일명
(문서 전체)"OC2_240813_TY1-2_0002.pdf" 2-3 source_data_name_jpg string Y 원천데이터 파일명
(문서 페이지)"OC2_240813_TY1-2_0002_001.jpg" 2-4 document_resolution array Y 원천데이터 해상도 [2480, 3508] 3 learning_data_info 3-1 learning_data_name string Y 학습데이터 파일명 "OC3_240813_TY1-2_0002 3-2 page_num string Y 페이지 번호 “1” 3-3 class_num string Y 클래스 번호 “2” 3-4 bounding_box array N 바운딩박스 좌표 [305, 834, 2173, 1067] 3-5 class_name string Y 클래스명 “T03” 3-6 plain_text string N 원문 텍스트 "영란은행 MPC는 코로나19 사태에 따른 시장불안 확산 등에 대응하여 3.19일 임시 통화정책회의를 다시 개최하여 금리 인하 및 추가 양적 완화조치를 시행하기로 결정" 3-7 visual_description string N 시각요소 설명문 “보도자료 문서의 특성을 나타내는 서식 형태의 표가 기록되어 있습니다” 3-8 layout_instruction string N 레이아웃 지시문 “이 문서의 레이아웃에 대해 요약하시오” 3-9 layout_description string N 레이아웃 설명문 “이 문서는 보도자료 형식이다. 텍스트 요소에는 주제목, 부제목, 본문이 있고, 시각 요소에는 표가 있다.” 3-10 document
_descriptionstring N 문서 설명문 “[###]국내 관광산업을 활성화시키기 위해 외국인 관광객이 ··· 전산으로도 확인할 수 있도록 개정했다.\n
[###]「국제우편물 수입통관 사무처리에 관한 고시」주요 개정 내용으로는\n
[###]국제우편물 통관시 간이한 방식으로 통관할 수 있는 ··· 소액 우편물에 대한 통관비용 및 통관시간 절감효과로 국민들의 편의를 제고할 수 있게 했다.\n
[@]OC3_240801_TY2-1_0154_013_V01.json”● 어노테이션 예시
{
"raw_data_info": {
"doc_name": "영란은행, 코로나19 사태 대응 추가대책 발표 및 시장반응",
"date": "240813",
"doc_type": "보고서(목록형)",
"format": "pdf",
"page_direction": "vertical",
"copyright": "미디어그룹사람과숲",
"organ_type": "공공기관",
"publisher": "한국은행"
},
"source_data_info": {
"raw_data_name": "OC1_240813_TY1-2_0002.pdf",
"source_data_name_pdf": "OC2_240813_TY1-2_0002.pdf",
"source_data_name_jpg": "OC2_240813_TY1-2_0002_001.jpg",
"document_resolution": [
2480,
3508
]
},
"learning_data_info": {
"learning_data_name": "OC3_240813_TY1-2_0002_001_002_T03.json",
"page_num": "1",
"class_num": "2",
"bounding_box": [
305,
834,
2173,
1067
],
"class_name": "T03",
"plain_text": "영란은행 MPC는 코로나19 사태에 따른 시장불안 확산 등에 대응하여 3.19일 임시 통화정책회의를 다시 개최하여 금리 인하 및 추가 양적 완화조치를 시행하기로 결정"
}
}
-
데이터셋 구축 담당자
수행기관(주관) : ㈜미디어그룹사람과숲
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 정용운 02-830-8583 wjdddyddns@humanf.co.kr 데이터 수집, 정제, 검수 수행기관(참여)
수행기관(참여) 기관명 담당업무 플리토 데이터 가공 포티투마루 AI 모델 학습 및 유효성 검증 데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 정용운 02-830-8583 wjdddyddns@humanf.co.kr 김재훈 010-5037-8975 jaehoon.kim@flitto.com AI모델 관련 문의처
AI모델 관련 문의처 담당자명 전화번호 이메일 김진서 010-2758-4385 tomkins@42maru.ai 정승범 010-7310-3792 jp@42maru.ai 저작도구 관련 문의처
저작도구 관련 문의처 담당자명 전화번호 이메일 정용운 02-830-8583 wjdddyddns@humanf.co.kr
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기] [공용IRB 심의신청 가이드라인]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 safezone1@aihub.kr 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.
오프라인 데이터 이용 안내
본 데이터는 K-ICT 빅데이터센터에서도 이용하실 수 있습니다.
다양한 데이터(미개방 데이터 포함)를 분석할 수 있는 오프라인 분석공간을 제공하고 있습니다.
데이터 안심구역 이용절차 및 신청은 K-ICT빅데이터센터 홈페이지를 참고하시기 바랍니다.

국방데이터 개방 안내
본 데이터는 국방데이터로 군사 보안에 따라 AI허브에서 데이터를 제공하지 않으며,
군 담당자를 통한 별도의 사용 신청이 필요합니다.