※ 25년 신규 개방되는 데이터로, 데이터 활용성 검토, 이용자 관점의 개선의견 수렴 등을 통해 수정/보완될 수 있으며 최종데이터, 샘플데이터, 산출물 등은 변경될 수 있습니다
-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.0 2025-04-16 데이터 개방 Beta Version 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2025-04-16 산출물 전체 공개 소개
규제 체계, 체크리스트, 검사 보고서 등 다양한 상황 내 규정 데이터 구축
구축목적
규제 체계, 체크리스트, 검사 보고서 등 다양한 상황 내 규정 데이터를 구축하여 규정 문서를 자동 생성하고, 분류하기 위함
-
메타데이터 구조표 데이터 영역 한국어 데이터 유형 텍스트 데이터 형식 json 데이터 출처 공공누리 데이터 라벨링 유형 질의응답, 텍스트 분류 라벨링 형식 json 데이터 활용 서비스 규정 질의응답 서비스, 승급자 대상 시험문제 생성 서비스, 규정 문서 생성 서비스 데이터 구축년도/
데이터 구축량2024년/406,658건 -
1. 데이터 통계
데이터 통계 데이터 종류 데이터 형태 원천데이터 규모 라벨링데이터 규모 어노테이션 규모 질의응답 텍스트 분류 자원 및 에너지 산업 텍스트 348,218 45,484 16,450 29,034 제조 및 건설 산업 텍스트 347,115 44,607 9,093 35,514 유통 및 서비스 산업 텍스트 356,341 48,026 20,562 27,464 정보 및 금융 서비스 텍스트 765,629 114,454 20,832 93,622 공공 및 사회 서비스 텍스트 887,911 101,241 20,415 80,826 문화, 여가 및 기타 서비스 텍스트 394,226 52,846 16,418 36,428 총계 3,099,440 406,658 103,770 302,888 2. 데이터 분포
- 라벨링 데이터 T1 (질의응답) 산업군별 분포
데이터 분포-라벨링데이터 T1(질의응답) 산업군별 분포 산업군 데이터 수량 비율 자원 및 에너지 산업 16,450 15.85% 제조 및 건설 산업 9,093 8.76% 유통 및 서비스 산업 20,562 19.81% 정보 및 금융 서비스 20,832 20.08% 공공 및 사회 서비스 20,415 19.67% 문화, 여가 및 기타 서비스 16,418 15.82% 합계 103,770 100% - 라벨링 데이터 T2 (텍스트 분류) 산업군별 분포
데이터 분포-라벨링 데이터 T2(텍스트 분류) 산업군별 분포 산업군 데이터 수량 비율 자원 및 에너지 산업 29,034 9.59% 제조 및 건설 산업 35,514 11.73% 유통 및 서비스 산업 27,464 9.07% 정보 및 금융 서비스 93,622 30.91% 공공 및 사회 서비스 80,826 26.69% 문화, 여가 및 기타 서비스 36,428 12.03% 합계 302,888 100% - 민간 분야 데이터 분포 : 5,025건 (2.45%)
-
-
AI 모델 상세 설명서 다운로드
AI 모델 상세 설명서 다운로드 AI 모델 다운로드1. 활용 모델 : Llama 3 70B base
사전 학습 데이터 : 15조 토큰의 사전 데이터가 학습된 초거대 AI 모델
모델 설명 : 지시 미세 조정(Instruction fine-tuning)에 의해서 다양한 특화 task에 더욱 효과적인 성능을 보이는 모델. task별 지시 데이터셋으로 모델의 생성 문장을 수행해야하는 task에 적합하도록 학습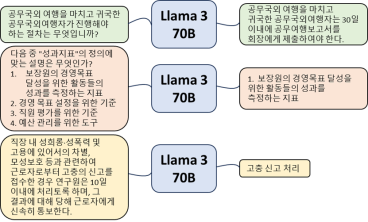
2. 실험 환경
1) 데이터셋 구성실험환경-데이터셋 구성 task 서술형 질의응답 객관식 질의응답 텍스트 분류 학습데이터 56,888 26,128 242,310 검증데이터 7,111 3,266 30,289 평가데이터 7,111 3,266 30,289 합계 71,110 32,660 302,888 2) 학습 방법
(1) 질문(서술형, 객관식)과 답변, 문장과 주제어 쌍으로 구성
(2) 질문이나 문장에 대하여 답변과 주제어를 각각 생성하도록 모델학습 (각각 독립적인 3개의 모델)3) 성능평가지표 : BERTScore (서술형 질의응답), ACC (객관식 질의응답), F1-점수 (텍스트 분류)
4) 성능 평가 결과
BERTScore: 0.846 (보조, RougeL: 0.22), ACC: 0.829, F1-점수: 0.8435) 목표 대비 성능
(1) 서술형 질의응답 목표 성능 (BERTScore) 0.70 [cf. ROUGE :0.19]
서술형 질의응답 모델 성능 (BERTScore) 0.846 (+0.14), (ROUGE) 0.22
(2) 객관식 질의응답 목표 성능 (ACC) 0.40
객관식 질의응답 모델 성능 (ACC) 0.829 (+0.43)
(3) 텍스트 분류 목표 성능 (F1-점수) 0.83
텍스트 분류 모델 성능 (F1-점수) 0.843 (+0.01) -
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드1. 데이터 구성
데이터 구성 항목 파일포맷 데이터 규모 데이터(라벨링) 유형 데이터 종류 원천 데이터 json 3,099,440건 텍스트 규정 문장 라벨링 데이터 json 103,770건 텍스트 질의응답 json 302,888건 텍스트 텍스트 분류 2. 어노테이션 포맷
- Task1 질의응답어노테이션 포맷-Task1 질의 응답 구분 속성명 타입 필수여부 설명 범위 비고 1 info Object Y 문서 기본 정보 1-1 document_id String Y 문서 식별자 2 annotation Object Y 라벨링 정보 2-1 contents_title String Y 상위 제목 2-2 QnA Array Y 문답 2-3 QnA.question_id Number Y 질의 식별자 2-4 QnA.question_format String Y 질의 형식 주관식
객관식2-5 QnA.role String Y 질의 역할 반부패 및 공정거래
고용 및 노동 환경
정보 및 소비자 보호
환경 및 자본 시장
기타2-6 QnA.question_type String Y 질의 유형 정의형
정보형
비교 및 절차형
수치형2-7 QnA.instruction String Y 질의 2-8 QnA.input String N 보기 2-9 QnA.output String Y 답변 - Task2 텍스트 분류
어노테이션 포맷-Task2 텍스트 분류 구분 속성명 타입 필수여부 설명 범위 비고 1 info Object Y 문서 기본 정보 1-1 document_id String Y 문서 식별자 2 annotation Object Y 라벨링 정보 2-1 contents_title String Y 상위 제목 2-2 contents Array Y 문단 2-3 contents.sentence_id Number Y 문장 식별자 2-4 contents.sentence_text String Y 문장 텍스트 2-5 contents.sentence_class String N 문장 분류 - 메타 데이터
어노테이션 포맷-메타 데이터 구분 속성명 타입 필수여부 설명 범위 비고 1 info Object Y 문서 기본 정보 1-1 document_id String Y 문서 식별자 1-2 organization_name String Y 기관명 1-3 organization_type String Y 기관의 성격 공공기관
공기업
교육기관
기업(협회)
정부기관
준정부기관
민간
1-4 document_name String Y 문서명 1-5 document_type String Y 문서의 성격 규정
지침(방침)
규칙
세칙
시행
요령
내규
정관
검사 보고서
체크리스트
기타1-6 document_class String Y 산업군 자원 및 에너지 산업
제조 및 건설 산업
유통 및 서비스 산업
정보 및 금융 서비스
공공 및 사회 서비스
문화, 여가 및 기타 서비스1-7 publish_year String Y 발행 연도 1-8 enactment_date String N 제정일 1-9 revision_date String N 개정일 1-10 global_rule Array N 국제 규약 다수 규약 포함 1-11 contents_title String Y 상위 제목 1-12 contents_text String Y 마크업이 포함된 전체 텍스트 3. 데이터 포맷
1) 원천 데이터 : *.json
{
"info" : [
{
"document_id" : 179
}
],
"annotation" : [
{
"contents_title" : "제2장 인권경영 일반법칙",
"contents" : [
{
"sentece_id" : 2001
"sentence_title" : "제3조 (고용상의 비차별)",
"sentence_text" : "공사는 근로자를 고용함에 있어서 인종, 종교, 장애, 성별, 출생지, 정치적 견해 등을 이유로 차별해서는 안 된다."
}
]
}
]
}
2) 라벨링 데이터 : *.json
- Task1 질의응답{
"info" : [
{
"document_id" : 179
}
],
"annotation" : [
{
"contents_title" : "제2장 인권경영 일반법칙",
"QnA" : [
{
"question_id" : 17
"question_format" : "객관식",
"role" : "고용 및 노동환경",
"question_type" : "수치형",
"instruction" : "연소자 고용시 고용하지 못하는 나이는 몇 세 이하인가?",
"input" : "(1) 15세 이하 (2) 16세 이하 (3) 17세 이하 (4) 18세 이하",
"output" : "(1) 15세 이하"
}
]
}
]
}- Task2 텍스트 분류
{
"info": [
{
"document_id": 179
}
],
"annotaiton": [
{
"contents_title": "제2장 인권경영 일반원칙“
"contents": [
{
"sentence_id": 2001,
"sentence_text": "공사는 인종, 종교, 장애, 성별, 출생지, 정치적 견해 등을 이유로 차별해서는 안 된다.",
"sentence_class": "고용상의 비차별"
}
]
}
]
}3) 메타 데이터 : *.json
{
"info": [
{
"document_id": 179,
"organization_name" : "부산항만공사",
"organization_type": "공공기관",
"document_name": "부산항만공사 인권경영 이행지침(2023년 1월 개정)",
"document_type": "지침",
"document_class": "유통 및 서비스 산업",
"publish_year": "2023년",
"enactment_date" : "",
"revision_date" : "2023년 1월 9일",
"global_rule" : [],
"contents_title": "제 2 장 인권경영 일반원칙",
"contents_text" : "**제 3 조 (고용상의 비차별)** 공사는 근로자를 고용함에 있어서 인종, 종교, 장애, 성별, 출생지, 정치적 견해 등을 이유로 ...
**제 12 조 (이해관계자와의 소통)** ① 공사는 다양한 이해관계자에게 공사의 인권경영정책을 알리고 상호협력을 위해 적극적으로 소통해야 한다.
② 공사는 인권경영 이행현황을 홈페이지 또는 온라인상에 게시할 수 있다.”
}
]
} -
데이터셋 구축 담당자
수행기관(주관) : ㈜스위트케이
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 이준형 02-3434-3120 gott@sweetk.co.kr 사업총괄 및 관리사업총괄 및 관리 수행기관(참여)
수행기관(참여) 기관명 담당업무 ㈜스위트케이 사업총괄, 데이터 수집/검사, 저작도구 개발 및 운영 ㈜메트릭스 데이터 정제/가공 한서대학교 산학협력단 AI모델 개발 데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 윤종현 02-3434-3120 planb@sweetk.co.kr 고혜지 02-6244-0780 hjgo@metrix.co.kr AI모델 관련 문의처
AI모델 관련 문의처 담당자명 전화번호 이메일 이훈희 041-660-1363 hhlee@hanseo.ac.kr 박준범 041-660-1362 jbpark@hanseo.ac.kr 저작도구 관련 문의처
저작도구 관련 문의처 담당자명 전화번호 이메일 이준형 02-3434-3120 gott@sweetk.co.kr 윤종현 02-3434-3120 planb@sweetk.co.kr
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기] [공용IRB 심의신청 가이드라인]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 safezone1@aihub.kr 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.
오프라인 데이터 이용 안내
본 데이터는 K-ICT 빅데이터센터에서도 이용하실 수 있습니다.
다양한 데이터(미개방 데이터 포함)를 분석할 수 있는 오프라인 분석공간을 제공하고 있습니다.
데이터 안심구역 이용절차 및 신청은 K-ICT빅데이터센터 홈페이지를 참고하시기 바랍니다.

국방데이터 개방 안내
본 데이터는 국방데이터로 군사 보안에 따라 AI허브에서 데이터를 제공하지 않으며,
군 담당자를 통한 별도의 사용 신청이 필요합니다.