-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.0 2024-06-28 데이터 개방 Beta Version 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2024-06-28 산출물 공개 Beta Version 소개
- 텍스트 기반의 콘텐츠 내용에 맞는 한국형 만화·웹툰 이미지 생성을 위한 Text to Image 데이터 - 네이버 웹툰 장르 구분을 기준으로 10개 장르 카테고리(로맨스, 판타지, 액션, 일상, 스릴러, 개그, 무협&사극, 드라마, 감성, 스포츠)로 구축함
구축목적
- 한국 만화·웹툰 문화와 이미지 생성 기술 발전을 위한 저작권 문제가 해결된 인공지능 학습용 데이터셋 설계 및 구축
-
메타데이터 구조표 데이터 영역 문화관광 데이터 유형 텍스트 , 이미지 데이터 형식 JPEG 데이터 출처 저작권을 보유한 작가와 사용 계약 체결 라벨링 유형 이미지 캡셔닝 (자연어) 라벨링 형식 JSON 데이터 활용 서비스 만화·웹툰 이미지 생성 서비스 데이터 구축년도/
데이터 구축량2023년/53,525 -
- 총 데이터 수량
원천 데이터 분류 형식 수량 단위 로맨스 .jpeg 12,687 장 드라마 .jpeg 11,920 장 판타지 .jpeg 8,787 장 스릴러 .jpeg 5,689 장 액션 .jpeg 4,838 장 개그 .jpeg 4,156 장 일상 .jpeg 3,366 장 무협&사극 .jpeg 1,003 장 감성 .jpeg 577 장 스포츠 .jpeg 502 장 총합 .jpeg 53,525 장 라벨링 데이터 분류 라벨링 유형 객체수 형식 파일 수량 파일 비율 로맨스 자연어 라벨링 12,687 .json 12,687 1 : 1 드라마 자연어 라벨링 11,920 .json 11,920 1 : 1 판타지 자연어 라벨링 8,787 .json 8,787 1 : 1 스릴러 자연어 라벨링 5,689 .json 5,689 1 : 1 액션 자연어 라벨링 4,838 .json 4,838 1 : 1 개그 자연어 라벨링 4,156 .json 4,156 1 : 1 일상 자연어 라벨링 3,366 .json 3,366 1 : 1 무협&사극 자연어 라벨링 1,003 .json 1,003 1 : 1 감성 자연어 라벨링 577 .json 577 1 : 1 스포츠 자연어 라벨링 502 .json 502 1 : 1 총합 자연어 라벨링 53,525 .json 53,525 1 : 1 - 학습용 데이터 수량
원천 데이터 분류 형식 수량 단위 로맨스 .jpeg 10,145 장 드라마 .jpeg 9,536 장 판타지 .jpeg 6,997 장 스릴러 .jpeg 4,551 장 액션 .jpeg 3,870 장 개그 .jpeg 3,324 장 일상 .jpeg 2,692 장 무협&사극 .jpeg 801 장 감성 .jpeg 461 장 스포츠 .jpeg 402 장 총합 .jpeg 42,779 장 라벨링 데이터 분류 라벨링 유형 객체수 형식 파일 수량 파일 비율 로맨스 자연어 라벨링 10,145 .json 10,145 1 : 1 드라마 자연어 라벨링 9,536 .json 9,536 1 : 1 판타지 자연어 라벨링 6,997 .json 6,997 1 : 1 스릴러 자연어 라벨링 4,551 .json 4,551 1 : 1 액션 자연어 라벨링 3,870 .json 3,870 1 : 1 개그 자연어 라벨링 3,324 .json 3,324 1 : 1 일상 자연어 라벨링 2,692 .json 2,692 1 : 1 무협&사극 자연어 라벨링 801 .json 801 1 : 1 감성 자연어 라벨링 461 .json 461 1 : 1 스포츠 자연어 라벨링 402 .json 402 1 : 1 총합 자연어 라벨링 42,779 .json 42,779 1 : 1 - 검증용 데이터 수량
원천 데이터 분류 형식 수량 단위 로맨스 .jpeg 1,271 장 드라마 .jpeg 1,192 장 판타지 .jpeg 895 장 스릴러 .jpeg 569 장 액션 .jpeg 484 장 개그 .jpeg 416 장 일상 .jpeg 337 장 무협&사극 .jpeg 101 장 감성 .jpeg 58 장 스포츠 .jpeg 50 장 총합 .jpeg 5,373 장 라벨링 데이터 분류 라벨링 유형 객체수 형식 파일 수량 파일 비율 로맨스 자연어 라벨링 1,271 .json 1,271 1 : 1 드라마 자연어 라벨링 1,192 .json 1,192 1 : 1 판타지 자연어 라벨링 895 .json 895 1 : 1 스릴러 자연어 라벨링 569 .json 569 1 : 1 액션 자연어 라벨링 484 .json 484 1 : 1 개그 자연어 라벨링 416 .json 416 1 : 1 일상 자연어 라벨링 337 .json 337 1 : 1 무협&사극 자연어 라벨링 101 .json 101 1 : 1 감성 자연어 라벨링 58 .json 58 1 : 1 스포츠 자연어 라벨링 50 .json 50 1 : 1 총합 자연어 라벨링 5,373 .json 5,373 1 : 1 - 시험용 데이터 수량
원천 데이터 분류 형식 수량 단위 로맨스 .jpeg 1,271 장 드라마 .jpeg 1,192 장 판타지 .jpeg 895 장 스릴러 .jpeg 569 장 액션 .jpeg 484 장 개그 .jpeg 416 장 일상 .jpeg 337 장 무협&사극 .jpeg 101 장 감성 .jpeg 58 장 스포츠 .jpeg 50 장 총합 .jpeg 5,373 장 라벨링 데이터 분류 라벨링 유형 객체수 형식 파일 수량 파일 비율 로맨스 자연어 라벨링 1,271 .json 1,271 1 : 1 드라마 자연어 라벨링 1,192 .json 1,192 1 : 1 판타지 자연어 라벨링 895 .json 895 1 : 1 스릴러 자연어 라벨링 569 .json 569 1 : 1 액션 자연어 라벨링 484 .json 484 1 : 1 개그 자연어 라벨링 416 .json 416 1 : 1 일상 자연어 라벨링 337 .json 337 1 : 1 무협&사극 자연어 라벨링 101 .json 101 1 : 1 감성 자연어 라벨링 58 .json 58 1 : 1 스포츠 자연어 라벨링 50 .json 50 1 : 1 총합 자연어 라벨링 5,373 .json 5,373 1 : 1 -
-
AI 모델 상세 설명서 다운로드
AI 모델 상세 설명서 다운로드 AI 모델 다운로드- 데이터 전처리
원천 데이터 전처리 설명 • 모든 데이터의 가로 길이는 1024px로 고정되어 있으나, 세로 길이는 768px 이상으로 서로 다름
• 생성형 모델인 SDXL은 1024×1024px 사이즈로 전처리가 필요함데이터 유형 JPEG 이미지 방법 및 과정 1. 원천데이터가 잘리지 않도록 가로 및 세로 길이를 동일한 1024px로 리사이징
2. 만약 여백이 발생한다면 흰색으로 처리함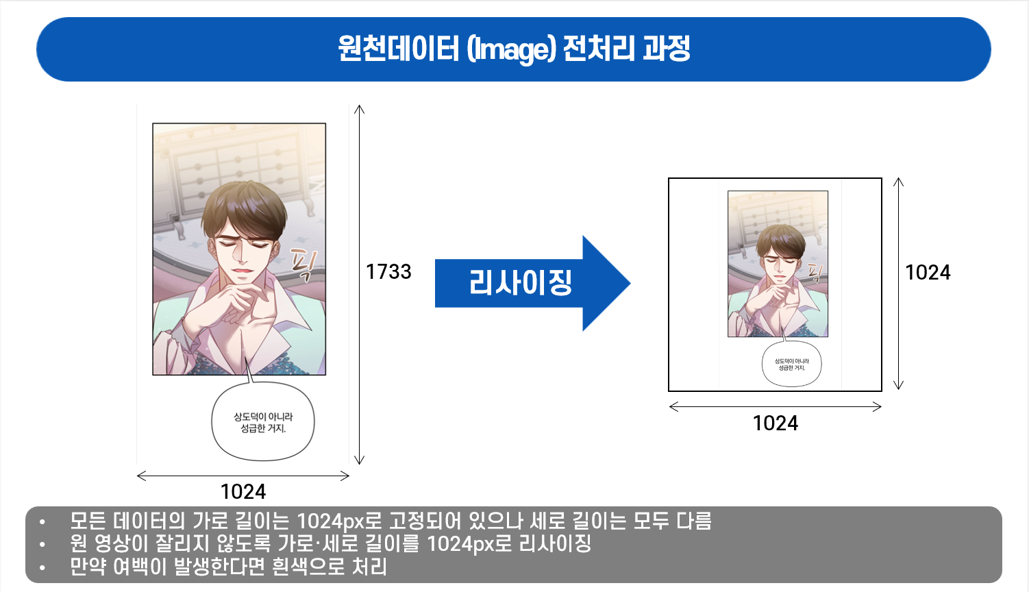
가공 데이터 전처리 설명 • 생성형 모델인 SDXL 영어에 최적화 되어 있으므로 학습할 때도 영어 텍스트를 사용하는 것이 좋음
• 본 사업에서 구축된 데이터의 JSON 파일의 value값은 한글로 되어 있으므로 번역할 필요가 있음데이터 유형 JSON 텍스트 방법 및 과정 1. 가공 데이터의 value값인 한글 텍스트들을 추출함
2. 한글 텍스트들을 AI 번역기를 통해 영어로 전환함
3. 이 때 사용되는 AI 번역기는 SOTA모델인 KoAlpaca를 사용함
- 활용 모델
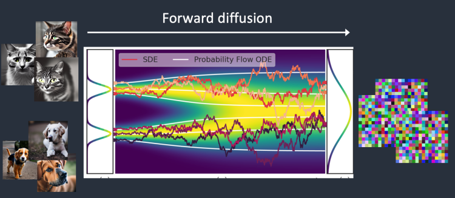
모델 이름 SDXL 모델 계열 Stable Diffusion 모델 설명 • Stable Diffusion 모델은 2개의 Diffusion 모델을 합친 형태
◯ Forward Diffusion : 본래 이미지에 잡음을 추가해 학습하는 모델
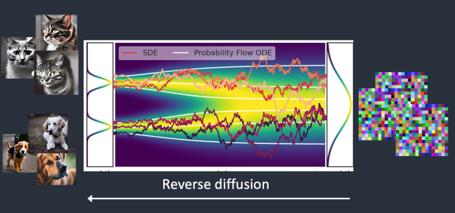
◯ Reverser Diffusion : 잡음에서 시작해 본래 이미지로 되돌아가며 학습하는 모델
• SDXL은 Stable Diffusion 계역 모델 중 SOTA를 기록한 모델
• 약 66억개의 파라미터를 기반으로 간단한 프롬프트를 이용해 더 나은 퀄리티의 이미지 생성 가능
• 기본 모델을 FineTuning하여 파생모델을 만들기 쉽다는 장점이 있음- 모델 결과 지표
지표명 FID(Frechet Inception Distance) 모델 설명 • 실제 이미지와 생성 이미지의 벡터 사이의 거리를 계산하여 유사성을 판단하는 지표
• FID값이 작을수록 거리가 가깝고 그만큼 유사한 이미지가 생성되었다는 지표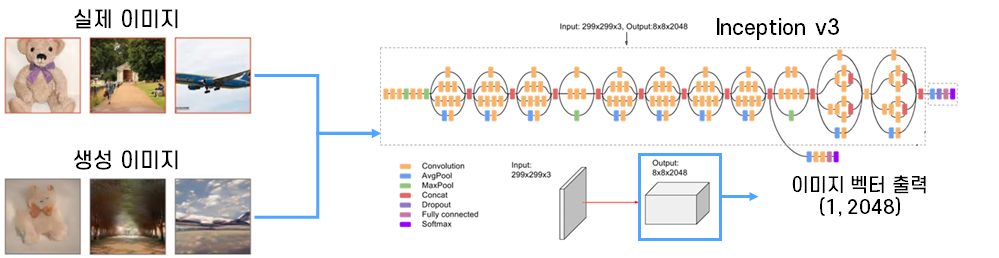
지표 수식 
지표명 AMTs(Amazon Machine Turks score) 모델 설명 • 데이터 검증 및 연구 수행부터 설문 조사, 콘텐츠 조정 등이 포함된 Amazon Mechanical Turk (AMT)의 시스템 모방 서비스로, 본 과제에서는 모델에서 생성된 프롬프트-이미지의 매칭 정도를 전문가의 직접 평가를 통해 유효성을 검사
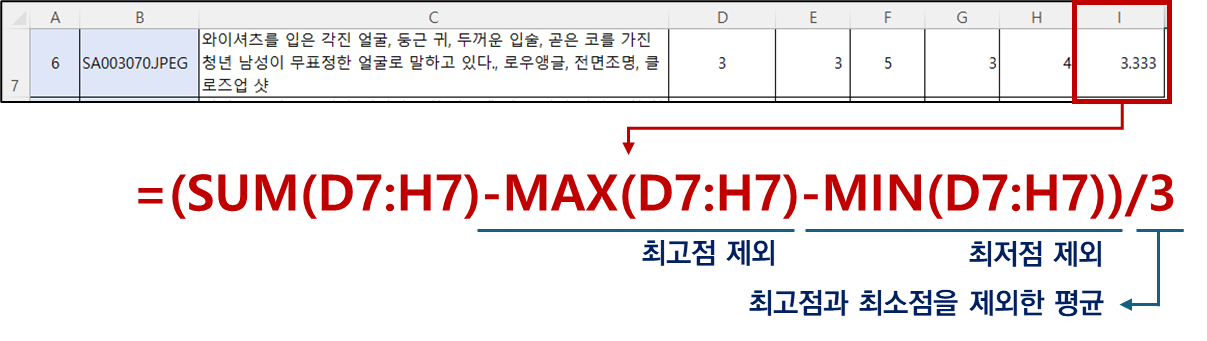
• 정성 평가 지표로는 리커드 5점 척도를 사용질문 입력한 프롬프트에 따라 이미지가 잘 생성되었는가? 평가 매우 부정 부정 보통 긍정 매우 긍정 1점 2점 3점 4점 5점 지표 수식 • 최종 평가는 각 샘플데이터의 최고점과 최저점을 제외한 평균을 구하고, 각 점수를 0점~100점으로 스케일링한 후 평균 산출

- 활용 서비스 분야
- 만화·웹툰 생성 시범 서비스 오픈 예정
- 영화, 연극, 드라마 등의 분야에서 콘티 및 스토리보드 작업 가능 -
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드- 데이터 구성
Key Description Type Child Type meta 메타 정보 JsonObject dataset 데이터셋 정보 JsonObject id 메타 식별자 String type 데이터 종류 String source_path 원천 파일 경로 String label_path 라벨 파일 경로 String caption_path 캡션 폴더 경로 String product 작품 정보 JsonObject genre 장르 String title 작품명 String writer 글 작가 String illustrator 그림 작가 String company 제작사 String platform 연재처 String post 연재 게시일 String category 만화/웹툰 유형 String images 이미지 정보 JsonObject type 이미지 파일 확장자 String width 이미지 가로 크기 Number height 이미지 세로 크기 Number label 라벨링 정보 JsonObject character 인물 JsonObject char_num 라벨링 인물 수 Number char_info 인물 정보 JsonArray JsonObject [ JsonObject gender 성별 String importance 중요도 String age 연령대 String kind 종족 String shape 신체 모양 String movement 신체 동작 String clothing 의상 String props 소품 String id 인물 식별자 String ] object 객체 JsonObject obj_num 객체 개수 Number obj_info 객체 정보 JsonArray String $value$ 객체 종류 String background 배경 JsonObject exist 배경 존재 유무 Boolean background_info 배경 정보 String directing 연출 JsonObject composition 구도 JsonObject angle 앵글 String lighting 조명 String shot 카메라 샷 String contenxt 발화 모음 JsonArray JsonObject [ JsonObject dialogue 대사 String bubble 말풍선 String ] effect 효과글 JsonArray String $value$ 효과글 종류 String prompt 라벨링 프롬프트 String caption 이미지 캡셔닝 데이터 String - 어노테이션 포맷
No 항목 타입 필수 여부 비고 한글명 영문명 1 메타 정보 meta object Y 1 데이터셋 정보 dataset object Y 1 메타 식별자 id string Y 과제분류_장르_작품명_회차_분류번호 2 데이터 종류 type string Y 한국형 만화·웹툰 생성 데이터 3 원천 파일 경로 source_path string Y ../데이터 종류/원천/장르/파일명.jpeg 4 라벨 파일 경로 label_path string Y ../데이터 종류/라벨/파일명.json 5 캡션 폴더 경로 caption_path string Y ../데이터 종류/캡션/장르/파일명.json 2 작품 정보 product object Y 1 장르 genre string Y 로맨스, 드라마, 판타지, 스릴러, 액션, 개그 일상, 무협·사극, 감성, 스포츠 2 작품명 title string Y 3 글 작가 writer string Y 4 그림 작가 illustrator string Y 5 제작사 company string Y 6 연재처 platform string Y 7 연재 게시일 post string Y 8 만화/웹툰 유형 category string Y 만화, 웹툰 3 이미지 정보 images obejct Y 1 이미지 파일
확장자type string Y 2 이미지 가로
크기width number Y 1024 이상 3 이미지 세로
크기height number Y 768 이상 2 라벨링 정보 label object Y 1 인물 character object Y 1 라벨링 인물 수 char_num number Y 0 ~ 2 인물 정보 char_info array N 1 개별 인물 정보 [] object N 1 인물 식별자 id number N 2 중요도 importance string N 주인물, 보조인물 3 종족 kind string N 4 성별 gender string N 5 연령층 age string N 6 신체 모양 shape string N 7 신체 동작 movement string N 8 의상 clothing string N 9 소품 props string N 2 객체 object object Y 1 객체 개수 obj_num number Y 2 객체 정보 obj_info array N 1 객체 종류 obj_info.[] string N 3 배경 background object Y 1 배경 존재 유무 exist bool Y True : 배경있음 / False : 배경없음 2 배경 정보 background_
infostring N 4 연출 directing object Y 1 구도 composition object Y 1 앵글 angle string Y 하이앵글, 아이레벨, 로우앵글 2 조명 lighting string Y 전면조명, 상부조명, 하부조명,
측면조명, 역광조명3 카메라 샷 shot string Y 클로즈업 샷, 미디엄 샷, 풀 샷, 롱 샹 2 발화 모음 context array N 1 개별발화 [] object N 1 대사 dialogue string N 직접 입력 2 말풍선 bubble string N 말풍선 종류 3 효과글 effect array N 5 라벨링
프롬프트prompt string Y 위의 라벨링 옵션 선택을 통해 자동생성된 프롬프트를 수동으로 수정 가능 3 이미지 캡셔닝 caption string Y 직접 입력 - 데이터 포맷
원천데이터 예시 
원천데이터 포맷 JPEG 가공데이터 예시 {
"meta": {
"dataset": {
"id": "1_로맨스_선비의방_61e_6",
"type": "한국형 만화·웹툰 생성 데이터",
"source_path": "../원천/01. 로맨스/SR177671.JPEG",
"label_path": "../라벨/01. 로맨스/LR177671.json"
},
"product": {
"genre": "로맨스",
"title": "선비의 방",
"writer": "이경아",
"illustrator": "이경아",
"company": "재담미디어",
"platform": "네이버 시리즈",
"post": "2017-07-03",
"category": "웹툰"
},
"images": {
"type": "JPEG",
"width": 1024,
"height": 1192
}
},
"label": {
"character": {
"char_num": 1,
"char_info": [
{
"gender": "남성",
"importance": "주인물",
"age": "청년",
"kind": "인간",
"shape": "살구색,날씬한,불안,묶은 머리,각진형,각진 눈,둥근 귀,얇은 입술",
"movement": "좌측을 향하는",
"clothing": "한복(남)",
"id": 0
}
]
},
"object": {
"obj_num": 0
},
"background": {
"exist": true,
"background_info": "배경 없음"
},
"directing": {
"composition": {
"angle": "아이레벨",
"lighting": "전면조명",
"shot": "미디엄 샷"
},
"context": [
{
"dialogue": "그 아이인가.",
"bubble": "원형/곡선"
}
]
},
"prompt": "남성,주인물,청년,인간,살구색,날씬한,불안,묶은 머리,각진형,각진 눈,둥근 귀,얇은 입술,좌측을 향하는,한복(남),배경 없음,아이레벨,전면조명,미디엄 샷"
},
"caption": "긴 머리에 슬픈 표정을 짓고 있는 여성이 있다."
}가공데이터 JSON 파일 예시 이미지 

가공데이터 포맷 JSON -
데이터셋 구축 담당자
수행기관(주관) : ㈜피씨엔
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 이우성 02-565-7740 wooslee@pcninc.co.kr 실무책임 수행기관(참여)
수행기관(참여) 기관명 담당업무 재담미디어 데이터 수집/획득 및 정제 세종대학교 산학합력단 데이터 가공 및 검수
AI모델 학습㈜비투엔 데이터 품질관리 실무책임 데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 이우성 02-565-7740 wooslee@pcninc.co.kr AI모델 관련 문의처
AI모델 관련 문의처 담당자명 전화번호 이메일 이수진 02-3408-1867 sju.dep.of.ai@gmail.com 저작도구 관련 문의처
저작도구 관련 문의처 담당자명 전화번호 이메일 이우성 02-565-7740 wooslee@pcninc.co.kr
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기] [공용IRB 심의신청 가이드라인]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 safezone1@aihub.kr 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.