-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.1 2023-12-20 데이터 최종 개방 1.0 2023-06-28 데이터 개방(Beta Version) 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2023-12-29 산출물 전체 공개 소개
• 1인미디어와 메타버스 시대에 인공지능을 통해 새로운 전통음악을 창작하고 전파하여 국악 대중화의 새로운 단계를 이끌 수 있도록 최적의 AI학습용 데이터를 개발
구축목적
• 우리나라 전통음악의 음원 인식과 전통적 특성을 지닌 음원 생성을 위한 통합적 학습데이터 구축
-
메타데이터 구조표 데이터 영역 문화관광 데이터 유형 오디오 데이터 형식 MIDI 악보(MID), 오디오 포맷(WAV), JSON 데이터 출처 기존 녹음 오디오 파일 수집 및 직접 제작 라벨링 유형 가사, 시김새, 템포, 음조직/장단 라벨링 형식 JSON 데이터 활용 서비스 1. AI 알고리즘 • 국악 장르 분류 및 음원 검색 • 음원에서 악기별 인식 및 음원 분리 • 음원 기반 MIDI 악보의 생성(자동 채보) • 크로스오버 국악 음악 작곡 및 편곡 등에 활용 • 국악분야 1인 크리에이터 시대를 위한 제작 툴 개발에 활용 • 학교 SW 교육 시 국악 인식 개선을 위한 프로그램 자료로 활용 2. 원천데이터 • 음원, MIDI 악보 데이터는 국악 교육자료로 활용 3. 분류체계정의 • 국악 디지털 아카이빙 구축 시 표준 분류체계로 활용 데이터 구축년도/
데이터 구축량2022년/MIDI 악보 파일 11,069개, 음원파일(Clip) 11,069개, 가사, 속성정보 11,069개 -
데이터 구축 규모
1. 원천데이터 구축 규모
● 총 구축시간: 154,076초
● 파일당 평균길이: 14초구분 원천데이터 구축 규모 구분 국악 데이터 국악 악보(MID) – 8,006 궁중음악, 풍류음악,민속악 3개 중분류 유사 국악 유사 국악 악보(MID) – 3,063 창작 국악, 퓨전국악 2개 중분류 합계 MID MIDI 악보 파일 11,069 개 WAV 음원파일(Clip) 11,069개 JSON 가사, 속성정보 11,069개 2. 원천데이터 분포
-장르별 분포NO 구분 대분류 중분류 소분류 코드(ID) 수량 비율 대분류 비율 국악/유사국악 비율 1 국악(A)
AM,AP궁중음악 ( C ) 1) 궁중음악 종묘제례악 C01 58 0.50% 5.50% 72.30% 2 문묘제례악 C02 24 0.20% 3 관현합주_여민락 C03 55 0.50% 4 여민락(만_령_해령) C04 47 0.40% 5 정읍(수제천) C05 11 0.10% 6 동동 C06 27 0.20% 7 보허자 C07 21 0.20% 8 낙양춘 C08 24 0.20% 9 취타 C09 129 1.20% 10 대취타 C10 18 0.20% 11 정재 C11 199 1.80% 12 궁중음악_기타 C99 1 0.00% 13 풍류음악 ( E ) 2) 기악풍류 영산회상 E01 1865 16.80% 29.00% 14 자진한잎 E02 183 1.70% 15 보허사 E03 3 0.00% 16 도드리 E04 264 2.40% 17 3) 정가 가곡 E05 562 5.10% 18 가사 E06 130 1.20% 19 시조 E07 193 1.70% 20 풍류음악_기타 E08 6 0.10% 21 민속악 ( F ) 4) 선율 기악 민속악 대풍류 F01 268 2.40% 37.80% 22 산조 F02 587 5.30% 23 시나위 F03 10 0.10% 24 5) 타악 중심 민속악 풍물놀이 F04 15 0.10% 25 사물놀이 F05 230 2.10% 26 무악 F13 358 3.20% 27 6) 성악 중심 민속악 민요 F06 1513 13.70% 28 잡가 F07 583 5.30% 29 판소리 F08 378 3.40% 30 단가 F09 80 0.70% 31 가야금병창 F10 3 0.00% 33 범패 F11 8 0.10% 34 창극 F12 3 0.00% 35 민속악_기타 F14 150 1.40% 36 유사국악(B)
BM,BP창작국악 ( R ) 전통적_창작국악 전통적_창작국악 CR1 619 5.60% 16.90% 27.70% 37 현대적_창작국악 현대적_창작국악 CR2 1249 11.30% 38 퓨전국악 ( S ) 클래식_퓨전국악 클래식_퓨전국악 FS1 262 2.40% 10.80% 39 팝_퓨전국악 팝_퓨전국악 FS2 714 6.50% 40 월드_퓨전국악 월드_퓨전국악 FS3 219 2.00% 합계 11069 100% -악기별 분포
NO 대분류 중분류 소분류 코드(ID) 수량 비율 악기 분포 1 현악기 String(S) 발현악기Plucked (SP) 가야금 SP01 1397 12.60% 36.70% 2 거문고 SP02 859 7.80% 3 비파 SP03 10 0.10% 4 철현금 SP04 2 0.00% 5 금 SP05 8 0.10% 6 슬 SP06 7 0.10% 7 찰현악기 Rubbed (SR) 해금 SR01 1409 12.70% 8 아쟁 SR02 370 3.30% 9 관악기(W) 리드 없는 악기(WN) 대금 WN01 900 8.10% 24.90% 10 소금 WN02 228 2.10% 11 단소 WN03 144 1.30% 12 퉁소 WN04 53 0.50% 13 훈 WN05 5 0.00% 14 지 WN06 4 0.00% 15 소 WN07 6 0.10% 16 리드악기(WR) 피리 WR01 1052 9.50% 17 태평소 WR02 217 2.00% 18 생황 WR03 149 1.30% 19 나발 WR04 1 0.00% 20 나각 WR05 1 0.00% 21 타악기(P) 무율타악기(PN) 장구 PN01 534 4.80% 12.10% 22 꽹과리 PN02 224 2.00% 23 북 PN03 216 2.00% 24 징 PN04 212 1.90% 25 바라 PN05 34 0.30% 26 목탁 PN06 2 0.00% 27 종 PN07 2 0.00% 28 소고 PN08 5 0.00% 29 정주 PN09 4 0.00% 30 축 PN10 1 0.00% 31 어 PN11 1 0.00% 32 유율타악기(PT) 양금 PT01 72 0.70% 33 편종 PT02 17 0.20% 34 편경 PT03 17 0.20% 35 성악(V) 인성 여성 VF01 1762 15.90% 26.30% 36 남성 VM02 1134 10.20% 37 혼성 VH03 10 0.10% 합계 11069 100% -
-
AI 모델 상세 설명서 다운로드
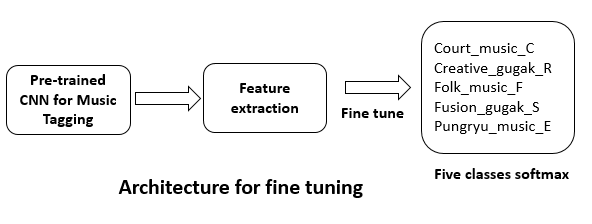
AI 모델 상세 설명서 다운로드 AI 모델 다운로드1. 장르 분류 모델: Pre-trained CNN
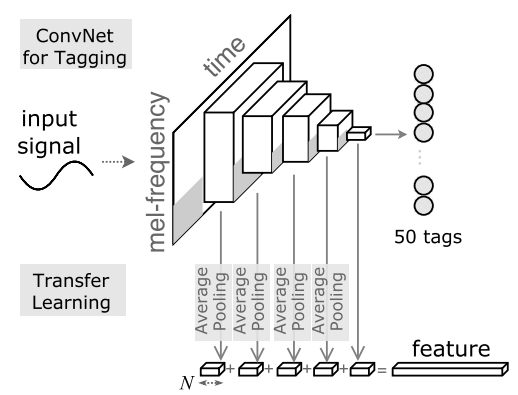
· Keunwoo Choi et. al. (2017). Transfer Learning for Music Classification and Regression Tasks. arXiv preprint arXiv:1703.09179,https://arxiv.org/abs/1703.09179
Exponential Linear Unit(ELU)는 모든 convolution layer에서 활성화 함수(activation function)로 사용된다. (2, 4), (4, 4), (4, 5), (2, 4), (4, 4)의 max-pooling은 모든 convolution layer 후에 각각 적용된다. 모든 convolution layer에서 커널 크기는 (3, 3), 채널 수 N은 32이며 batch normalization이 사용된다. 입력은 single channel, 96 mel bins, 1360 temporal frame이다. 학습 후 1~4층의 feature map은 average pooling을 사용하여 subsampling하고, 5층의 feature map은 이미 스칼라(크기 1 × 1)이기 때문에 그대로 사용한다. 이러한 32차원 feature들을 연결하여 ConvNet feature를 형성한다.
1.1. 설치

1.2 Feature 및 파라미터
· Log-scale Mel-spectrogram:
· SAMPLING_RATE=16000, N_FFT=512, N_MELS=96,N_OVERLAP=256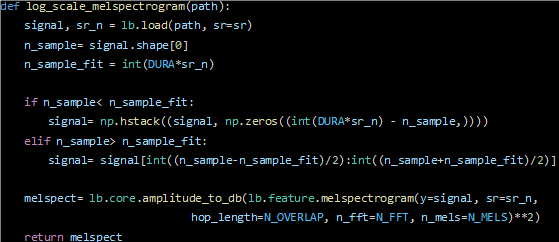
1.3. 전처리: 가상환경 전환 및 csv 파일 만들기
· augmentaion.py
· 데이터 증강(augmentation) 동안 입력 폴더 경로 할당.
예: “./dataset/Fusion_gugak_S/”
· 데이터 증강 배수 N을 main 함수 내에 지정.
예: N = 2 는 audio 파일내의 1개 샘플당 2 개의 증강된 샘플 생성
· 증강(augmented)된 audio 샘플은 동일 입력 폴더에 저장
예: “./dataset/Fusion_gugak_S/”
· prepare_datasets.py
· 할당: PATH_DATASETS = “./genre_221216_docker_project/dataset/”
· 할당: FOLDER_CSV = “./genre_221216_docker_project/data_csv/”
· 할당: folder_dataset_gtg = “./genre_221216_docker_project/dataset/”
→ audio 경로와 해당 라벨의 .csv 파일 생성.
1.4 테스트 셋 검증

· -fp : 테스트 셋 폴더 경로
· -N : 테스트 셋 데이터 개수 입력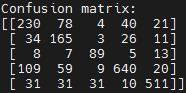
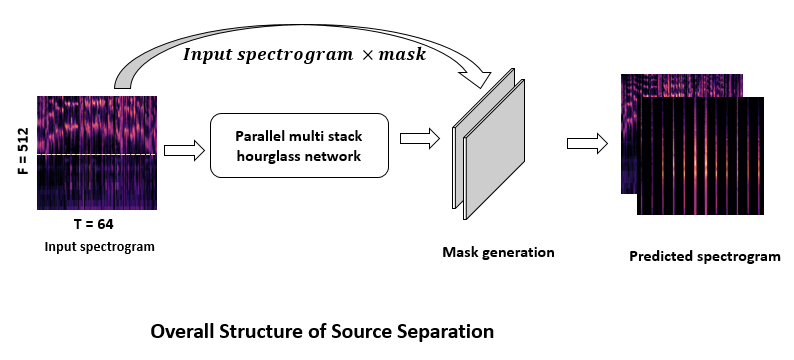
2. 음원 분리 모델: Parallel Stacked Hourglass Network (PSHN)
· B. Bhattarai, Y. R. Pandeya and J. Lee, "Parallel Stacked Hourglass Network for Music Source Separation," in IEEE Access, vol. 8, pp. 206016-206027, 2020, doi: 10.1109/ACCESS.2020.3037773.
입력으로 Multiband Spectrogram이 사용된다. Spectrogram은 서로 다른 주파수 대역에서 유사한 패턴을 나타낸다. 특히 저주파는 높은 에너지로 둘러싸여 있고, 고주파는 낮은 에너지와 노이즈를 포함하고 있다. 따라서 Spectrogram을 주파수 축을 따라 반으로 나누어 두 개의 스펙트로그램을 생성하고 각 대역에 다른 convolution filter를 적용한다.
Stacked Hourglass Network(SHN)는 상위 대역, 하위 대역, 전체 대역에서 입력을 받고, 각각 Upper Band Stacked Hourglass Network(UBSHN), Lower Band Stacked Hourglass Network(LBSHN), Full Band Stacked Hourglass Network(FBSHN)를 통과한다. 이 세 가지를 모두 합친 것이 PSHN이다. UBSHN, LBSHN, FBSHN은 각각 총 4개의 Stacked Hourglass Module로 구성된다.
마스크를 추정하고 이전 Parallel hourglass module과 후속 Parallel hourglass module 사이의 spectrogram을 예측하는 과정을 중간 예측(Intermediate Predictions)이라고 한다. 상위 대역, 하위 대역 및 전체 대역 spectrogram을 위한 Stacked Hourglass module이 네 개 있다. 따라서 중간 예측을 위해 3개와 최종 예측을 위한 1개, 총 4개의 손실(loss)을 계산한다.
2.1. 설치

2.2. 전처리

· feature 및 parameter


2.3. 학습
2.4. 테스트 셋 검증

![테스트 셋 검증 결과 Median SDR janggu : [12.55483974] song : [20.32157809]](/web-nas/aihub21/files/editor/2023/06/aef50cec1033420c98322c2ece665c5a.png)
3. 자동 채보 모델: Omnizart (U-net 기반 피아노 채보 모델)

· Wu et al., (2021). Omnizart: A General Toolbox for Automatic Music Transcription. Journal of Open Source Software, 6(68), 3391, https://doi.org/10.21105/joss.03391
CNN(Convolutional Neural Network)은 합성곱 신경망으로 최소한의 전처리를 사용하도록 설계된 다계층 퍼셉트론이며 본 사업에서는 CNN을 통해 음원에서 국악 악기, 음정, 박자등의 특징점을 추출하여 분류, 분리(Separation), 자동 악보 제작(transcription)에 활용
3.1 설치

{dataset_path}에는 gugak_docker을 실행할 서버에 있는 데이터셋을 설치한 dataset 폴더 경로 입력
3.2 Feature 구성요소
· Multiplication of spectrum and cepstrum
· Spectrum of the audio.
· Generalized Cepstrum of Spectrum (GCoS)
· Cepstrum of the audio
· Central frequencies to each feature3.3. 전처리 및 학습
· 전처리
Dataset은 String, Vocal, Wind 세가지의 폴더로 구성된다. 각 카테고리 별로 Train dataset와 Test dataset으로 나누어준다. Train dataset과 Test dataset은 mid와 wav폴더로 구성된다.
각 wav 파일에서 feature를 추출해서 ‘.hdf’ 파일로 저장하고, 각 mid 파일에서 label(정답 음계)를 추출해서 ‘.pickle’ 파일로 저장한다. 결과적으로 train_feature, test_feature 폴더가 생성된다.
· 학습
3.4 테스트 셋 검증
· 전체 test dataset에 대해 inference를 하려는 경우
· 특정 폴더에 있는 dataset에 대해 inference를 하려는 경우

→ --model에는 string(현악기), vocal(음성), wind(관악기) 선택 가능
· dataset_path로 지정된 폴더 안에는 아래와 같은 구조를 가져야 함.
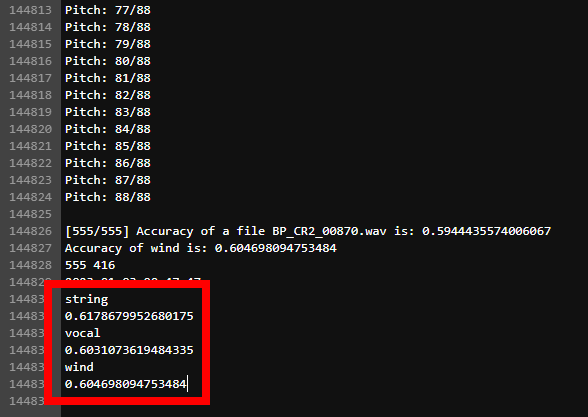
-
데이터 성능 점수
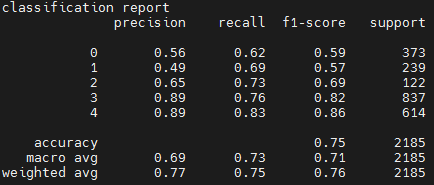
측정값 (%)기준값 (%)데이터 성능 지표
데이터 성능 지표 번호 측정항목 AI TASK 학습모델 지표명 기준값 점수 측정값 점수 1 MIDI 악보 생성 Generation U-Net based Omnizart Accuracy 55 % 56.86 % 2 국악 음원 장르 분류 Audio Classification Pre-trained CNN F1-Score 0.7 점 0.7483 점 3 국악 음원 악기 분리 Speech Separation Parallel Stacked Hourglass Network SDR 4 단위없음 6.99 단위없음
※ 데이터 성능 지표가 여러 개일 경우 각 항목을 클릭하면 해당 지표의 값이 그래프에 표기됩니다.
※ AI모델 평가 지표에 따라 측정값의 범위, 판단 기준이 달라질 수 있습니다. (ex. 오류율의 경우, 낮을수록 좋은 성능을 내는 것으로 평가됩니다)
-
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드1. 데이터 포맷
데이터 형식 데이터 내용 비고 MIDI 악보
(MID)• 해당 음원의 디지털 연주를 위한 MIDI 악보
• 음원 파일과 동기화 처리된 일부로 제공음원과 동기화 오디오 포맷
WAV• 메타정보(곡명, 제작자, 년도, 악기 등)
• 정의된 음원 속성 정보악보와 매칭하는 음원 구간 정제 필요 JSON • 해당 세트의 메타정보 및 속성정보
• 가사라벨링 데이터 2. 어노테이션 포맷
번호 항목 타입 필수 샘플 설명 / 속성명 속성 항목 설명 여부 예시 공통 항목 dataset_Info 1 dataset_id 데이터셋 식별자 string Y 2022_2_077_1 2 dataset_name 데이터셋 이름 string Y 국악 음원 데이터 국악 음원 데이터 3 dataset_src_path 데이터셋 폴더 위치 string Y /data/국악/ 4 dataset_ver 데이터셋 버전 number Y 5 5 dataset_type 데이터셋 형태 number Y 3 3. 오디오 음원 데이터 기본정보 6 music_source_info 6-1 music_source_nm 원천데이터 음원 파일 이름 string Y AM_C01_NNNNN 6-2 music_source_fmt 원천데이터 음원 파일 포맷 string Y wav wav 6-3 music_source_type 원천데이터 음원 파일 형태 string Y P 악곡(M: music)/악구(P:phrase) 6-4 music_nm_kor 악곡 이름 (한글) string Y 상사별곡 대금 6-5 phrs_nm_kor 악구 이름 (한글) string N 자진모리 6-6 play_time 음원길이 (초) number Y 90 NNNN 6-7 music_trk_nmbr 트랙 개수 number Y 1 1 : 단일 트랙 (분리) default : N: 멀티트랙 경우 트랙 수 숫자 6-8 multi_trk_src_file_name 트랙분리전 멀티트랙 음원파일 이름 string N MP_C01_SP02_00024.wav 트랙분리전 멀티 트랙 음원 파일 이름 6-9 samplingRate 샘플링레이트(Hz) number Y 44100 기본 44100 Hz 6-10 bitDepth 비트 뎁스 (bit) number Y 16 기본 : 16 bit 6-11 channel 채널(모노, 스트레오) string Y M 모노 : M 스테레오 : S 음원데이터 수집 정보 7 get_info 음원데이터 수집 정보 7-1 get_place 수집처 string N 전라북도청 국악 데이터 상세 정보 8 music_type_info 국악 분류 정보 8-1 music_category 국악 구분 대분류 string Y 국악 국악/유사국악 8-2 music_genre_cd 국악 구분 소분류 코드 string Y C01 국악 분류 기준 소분류 (GENRE)코드 8-3 instrument_cd 악기 분류 코드 string Y SP02 별도의 악기 분류 코드 참고 8-4 main_instr_player 연주자/가창자 이름 string N 안소선 라벨링 정보 9 annotation_data_info 라벨링 데이터 정보 9-1 mode_cd 음조직 코드 string N MG09 별도의 음조직 분류 코드 참고) 9-2 gukak_Beat_cd 국악 장단 코드 string N DQ0404 별도의 77_1_국악음원라벨링데이터분류기준_장단 코드 참고) 9-3 single_Tonguing_cd 시김새 코드 Array N VB02 별도의 77_1_국악음원라벨링데이터분류기준_ 시김새코드 참고) 9-3-1 annotation_category Annotation 종류 string N 시김새 음조직/장단/시김새 / 템포 / 가사 9-3-2 annotation_ID annotation 식별자 number N 1 9-3-3 annotation_code Annotation 종류별 분류 코드 string N MF03 77_1_국악음원라벨링데이터분류기준_시김새 코드 참고 예:남도요성VB02 9-3-4 start_time 라벨링 속성 시작 시점 number N sss.xxx 시간단위는 초 단위 9-3-5 end_time 라벨링 속성 종료 시점 number N sss.xxx 시간단위는 초 단위 9-4 tempo 템포 Array N 40 별도의 코드 없이 메트로놈 수치를 라벨링하는 것으로 함 이하 라벨링 데이터는 9-3 시김새와 동일 9-5 lyrics 가사 Array N 이하 라벨링 데이터는 9-3 시김새와 동일 3. 데이터 구성
라벨링데이터 실제예시{ "dataset_info": {
"dataset_id": "2022_2_077_1",
"dataset_name": "국악 음원 데이터",
"dataset_src_path": "/data/국악/C_궁중음악",
"dataset_ver": 6,
"dataset_type": 3
},
"music_source_info": {
"music_src_nm": "AM_C01_08594",
"music_src_fmt": "wav",
"music_src_type": "M",
"music_nm_kor": "종묘제례악 중 귀인",
"phrs_nm_kor": "",
"play_time": 49.714,
"music_trk_nmbr": 1,
"multi_trk_src_file_name": "",
"samplingRate": 44100,
"bitDepth": 16,
"channel": "S"
},
"get_info": {
"get_place": "국립국악원"
},
"music_type_info": {
"music_catagory_1": "국악",
"music_genre_cd": "C01",
"instrument_cd": "SR02",
"main_instr_player": ""
},
"annotation_data_info": {
"mode_cd": "MF01",
"gukak_beat_cd": "NB0013",
"single_tonguing_cd": [],
"tempo": [
{
"annotation_category": "템포",
"annotation_ID": 1,
"annotation_code": 98,
"start_time": "0.000",
"end_time": "49.714"
}
],
"lyrics": []
}
} -
데이터셋 구축 담당자
수행기관(주관) : 전주대 산학협력단
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 김병오 063-220-2298 kbo@jj.ac.kr 총괄책임, 수집, 인공지능 수행기관(참여)
수행기관(참여) 기관명 담당업무 ㈜비타소프트 정제, 인공지능 ㈜메트릭스 가공, 검수 전라북도청 수집 데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 김병오 063-220-2298 kbo@jj.ac.kr
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 safezone1@aihub.kr 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.