BETA 공적말하기 실습 및 평가 데이터
- 분야교육
- 유형 오디오 , 이미지 , 비디오 , 텍스트
-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.0 2024-06-28 데이터 개방 Beta Version 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2024-06-28 산출물 공개 Beta Version 소개
- 공적 말하기 실습 및 평가를 위한 발표 영상 및 음성, 발표 자료 텍스트, 발표 평가 텍스트 데이터셋 구축과 공적 말하기 인식 및 분류, 수준 평가
구축목적
- 공적말하기는 전략적으로 목적을 달성하기 위한 자기표현의 한 방식으로서, 본학습 모델은 언어적 요소 및 비언어적 요소의 영상 관련 데이터 수집과 학습을 통해 공적 말하기의 능력 전체 향상 효과를 위한 서비스 제공을 목표로 함
-
메타데이터 구조표 데이터 영역 교육 데이터 유형 오디오 , 이미지 , 비디오 , 텍스트 데이터 형식 mp4, jpg 데이터 출처 자체 수집 라벨링 유형 발표평가, 키포인트 라벨링 형식 json 데이터 활용 서비스 인공지능 태그인식모델 및 부정적 제스처 분류모델 기반 말하기 평가 서비스 데이터 구축년도/
데이터 구축량2023년/원천데이터 : 언어적 800건 / 비언어적 288,000건 라벨링데이터 : 언어적 800건 / 비언어적 28,800건 -
- 데이터 구축 규모
구분 상세구분 수량 소계 비율 비고 1. 언어적 1. A00 중학생 3학년 100 800 12.50% 2. A01 고등학생 200 25% 3. A02 20대 200 25% 4. A03 30대 100 12.50% 5. A04 40대 100 12.50% 6. A05 50대 이상 100 12.50% 2. 비언어적 1. B01 손동작(머리) 2,400 28,800 8.33% 2. B02 손동작(얼굴) 2,400 8.33% 3. B03 손동작(몸긁기) 2,400 8.33% 4. B04 손동작(손톱) 2,400 8.33% 5. B05 머리동작(고개흔들기) 2,400 8.33% 6. B06 머리동작(좌우흔들기) 2,400 8.33% 7. B07 머리동작(숙이기) 2,400 8.33% 8. B08 팔동작(뒷짐) 2,400 8.33% 9. B09 팔동작(무의미반동) 2,400 8.33% 10. B10 자세(좌우흔들기) 2,400 8.33% 11. B11 자세(비스듬히) 2,400 8.33% 12. B12 자세(비비꼬기) 2,400 8.33% 합계 29,600 ▲ 표 6 - 데이터 구축 규모
- 데이터 분포- [언어적] 성별 데이터 수량
연령구분 소계 남성 여성 1. A00 중학생 3학년 100 46 54 2. A01 고등학생 200 153 47 3. A02 20대 200 116 84 4. A03 30대 100 43 57 5. A04 40대 100 29 71 6. A05 50대 이상 100 28 72 합계 800 415 385 ▲ 표 7 - [언어적] 성별 데이터 수량
- [언어적] 분류 항목별 데이터 수량
연령구분 소계 찬성/반대 주장 설명 1. A00 중학생 3학년 100 10 36 54 2. A01 고등학생 200 48 59 93 3. A02 20대 200 60 60 80 4. A03 30대 100 28 36 36 5. A04 40대 100 28 36 36 6. A05 50대 이상 100 36 28 36 합계 800 210 255 335 ▲ 표 8 - [언어적] 분류별 데이터 수량
- [언어적] 원고 난이도별 데이터 수량
연령구분 소계 상 중 하 1. A00 중학생 3학년 100 18 46 36 2. A01 고등학생 200 44 63 93 3. A02 20대 200 60 80 60 4. A03 30대 100 36 36 28 5. A04 40대 100 36 28 36 6. A05 50대 이상 100 36 36 28 합계 800 230 289 281 ▲ 표 9 - [언어적] 난이도별 데이터 수량
- [언어적] 발표 환경별 데이터 수량
연령구분 소계 강의실 학교 회의실 1. A00 중학생 3학년 100 0 100 0 2. A01 고등학생 200 0 200 0 3. A02 20대 200 108 7 85 4. A03 30대 100 2 0 98 5. A04 40대 100 0 0 100 6. A05 50대 이상 100 0 0 100 합계 800 110 307 383 ▲ 표 10 - [언어적] 발표 환경별 데이터 수량
- [언어적] 청중 규모별 데이터 수량
연령구분 소계 5인이하 6~10인이하 11~30인이하 1. A00 중학생 3학년 100 0 100 0 2. A01 고등학생 200 0 59 141 3. A02 20대 200 197 3 0 4. A03 30대 100 64 36 0 5. A04 40대 100 57 43 0 6. A05 50대 이상 100 46 54 0 합계 800 364 295 141 ▲ 표 11 - [언어적] 청중 규모별 데이터 수량
- [언어적] 주제별 데이터 수량
연령구분 소계 수량 주제 1. A00 중학생 3학년 100 10 에너지 보호에 대한 본인의 생각 18 다문화 가족을 대하는 본인의 자세 18 존경하는 위인에 대한 생각 18 학교 폭력에 대한 본인 생각 및 해결방안을 작성 18 살고 싶은 집 18 나의 친구에 대한 본인의 생각 2. A01 고등학생 200 20 과학의 발전에 대한 본인의 생각 24 반려동물 사육에 대한 본인의 의견 24 미래의 나의 모습 24 교권 회복을 위한 학생 체벌의 의견 24 한류를 지키는 방법 24 미래 도시에 대한 본인의 생각 24 나의 선행 21 내가 가장 좋아하는 과목 15 전통과 악습에 대한 본인 생각을 작성 3. A02 20대 200 20 인공지능의 사회적 책임 20 미디어 발전과 사용 방법 20 현명한 소비 방법 20 범죄자 신상공개에 대한 의견 20 SNS상의 문제에 대한 본인의 생각 20 습관들이기 위한 노력과 경험 20 익명성에 대한 본인의 의견 20 나의 취미 20 표절을 해결할 수 있는 대안제시 20 나의 성격 4. A03 30대 100 18 e스포츠에 대한 본인의 생각 18 인종차별에 대한 본인의 생각 18 소수의 의견에 대한 본인의 생각 18 대체 에너지의 다양한 방법 18 국내 여행의 추억 10 비혼주의자에 대한 본인의 의견 5. A04 40대 100 18 생물학적으로 다른 남/여에 대한 본인의 생각 18 사회적 불평등에 대한 본인의 생각 18 예절의 기준에 대한 의견 18 장애에 대한 부정적인 인식 개선 방안 10 징벌적 배상제도 도입에 대한 견해 18 참된 스승의 사례 6. A05 50대 이상 100 18 혐오시설 건설 문제에 대한 본인의 생각 18 남한과 북한의 통일에 대한 본인의 생각 18 위생을 지키는 방법 18 비트코인을 결제화폐로서 인정하는지에 대한 본인의 의견 18 타인을 중시하지 않았던 사례 10 지적 재산권에 대한 본인의 생각 작성 합계 800 ▲ 표 12 - [언어적] 주제별 데이터 수량
- [언어적] 태그 분류별 수량
연령구분 소계 간투어 반복/수정 긴 쉼 본문과
다른표현1. A00 중학생 3학년 3,391 1,142 1,057 15 1,177 2. A01 고등학생 6,136 1,226 2,088 50 2,772 3. A02 20대 9,107 3,688 2,923 63 2,433 4. A03 30대 3,888 1,315 1,107 18 1,448 5. A04 40대 3,569 944 894 22 1,709 6. A05 50대 이상 4,769 1,457 936 22 2,354 합계 30,860 9,772 9,005 190 11,893 ▲ 표 13 - [언어적] 태그 분류별 수량
- [언어적] 발화 크기별 데이터 수량
연령구분 소계 크다 중간 작다 1. A00 중학생 3학년 100 17 70 13 2. A01 고등학생 200 22 162 16 3. A02 20대 200 40 146 14 4. A03 30대 100 15 72 13 5. A04 40대 100 25 73 2 6. A05 50대 이상 100 8 89 3 합계 800 127 612 61 ▲ 표 14 - [언어적] 발화 크기별 데이터 수량
- [언어적] 발화 어절수별 데이터 수량
연령구분 소계 220~300 301~400 401~500 501~600 1. A00 중학생 3학년 100 49 48 3 2. A01 고등학생 200 44 152 4 3. A02 20대 200 0 142 56 2 4. A03 30대 100 2 74 24 5. A04 40대 100 1 67 31 1 6. A05 50대 이상 100 3 63 32 2 합계 800 99 546 150 5 ▲ 표 15 - [언어적] 발화 어절수별 데이터 수량
- 비언어적
- [비언어적] 동작별 데이터 수량동작구분 소계 동작 세부 정의 1. B01 손동작(머리) 2,400 손으로 머리카락(머리)를 만지는 행위 2. B02 손동작(얼굴) 2,400 손으로 얼굴을 만지는 행위 3. B03 손동작(몸긁기) 2,400 손으로 몸을 긁는 행위 4. B04 손동작(손톱) 2,400 손톱을 만지작거리는 행위 5. B05 머리동작(고개흔들기) 2,400 (흘러내린 머리 등을 넘기기 위해) 고개를 흔드는 행위 6. B06 머리동작(좌우흔들기) 2,400 (말이 막혔거나 실수 했을 때) 고개를 좌우로 흔드는 행위 7. B07 머리동작(숙이기) 2,400 고개를 숙이고 있는 행위 8. B08 팔동작(뒷짐) 2,400 뒷짐을 지고 있는 행위 9. B09 팔동작(무의미반동) 2,400 팔을 의미없이 접었다 펴는 행위 10. B10 자세(좌우흔들기) 2,400 몸을 좌우로 흔드는 행위 11. B11 자세(비스듬히) 2,400 비스듬히 서 있는 행위 12. B12 자세(비비꼬기) 2,400 몸을 비비꼬는 행위 합계 28,800 ▲ 표 16 - [비언어적] 동작별 데이터 수량
- [비언어적] 성별 데이터 수량
동작구분 소계 남성 여성 1. B01 손동작(머리) 2,400 1,212 1,188 2. B02 손동작(얼굴) 2,400 1,212 1,188 3. B03 손동작(몸긁기) 2,400 1,212 1,188 4. B04 손동작(손톱) 2,400 1,212 1,188 5. B05 머리동작(고개흔들기) 2,400 1,212 1,188 6. B06 머리동작(좌우흔들기) 2,400 1,212 1,188 7. B07 머리동작(숙이기) 2,400 1,212 1,188 8. B08 팔동작(뒷짐) 2,400 1,212 1,188 9. B09 팔동작(무의미반동) 2,400 1,212 1,188 10. B10 자세(좌우흔들기) 2,400 1,212 1,188 11. B11 자세(비스듬히) 2,400 1,212 1,188 12. B12 자세(비비꼬기) 2,400 1,212 1,188 합계 28,800 14,544 14,256 ▲ 표 17 - [비언어적] 성별 데이터 수량
- [비언어적] 연령별 데이터 수량
동작구분 소계 중학생
3학년
고등학생 20대 30대 40대 50대이상 1. B01 손동작(머리) 2,400 300 600 600 300 300 300 2. B02 손동작(얼굴) 2,400 300 600 600 300 300 300 3. B03 손동작(몸긁기) 2,400 300 600 600 300 300 300 4. B04 손동작(손톱) 2,400 300 600 600 300 300 300 5. B05 머리동작(고개흔들기) 2,400 300 600 600 300 300 300 6. B06 머리동작(좌우흔들기) 2,400 300 600 600 300 300 300 7. B07 머리동작(숙이기) 2,400 300 600 600 300 300 300 8. B08 팔동작(뒷짐) 2,400 300 600 600 300 300 300 9. B09 팔동작(무의미반동) 2,400 300 600 600 300 300 300 10. B10 자세(좌우흔들기) 2,400 300 600 600 300 300 300 11. B11 자세(비스듬히) 2,400 300 600 600 300 300 300 12. B12 자세(비비꼬기) 2,400 300 600 600 300 300 300 합계 28,800 3,600 7,200 7,200 3,600 3,600 3,600 ▲ 표 18 - [비언어적] 연령별 데이터 수량
-
-
AI 모델 상세 설명서 다운로드
AI 모델 상세 설명서 다운로드 AI 모델 다운로드- 언어적
유형 요약 설명 학습 모델 태깅 탐지 (태그 인식 및 분류) 모델 데이터명 공적말하기 실습 및 평가 데이터 모델 KLUE-BERT (BERT) 성능 지표 태깅 탐지 F1-점수(F1-Score) 64% 이상 개발 내용 - 구축된 데이터를 활용하여 문장의 태그를 탐지(인식)하는 모델 개발
- BERT의 Token Classification을 활용
- 태그가 포함된 발화된 문장에서 태그 시퀀스를 결과로 출력응용 서비스 발화된 문장에 있는 간투어, 긴쉼(휴지), 반복어구 등의 태그를 탐지(인식)하여 말하기평가를 해주는 서비스 제공 유형 설명 모델명 KLUE-BERT (BERT) 모델 description KLUE-BERT는 한국어 자연어 처리를 위한 사전 학습 모델인 BERT의 한국어 버전입니다. KLUE-BERT는 다양한 자연어 처리 태스크를 수행할 수 있으며, 그 중 하나가 다중 태그 인식 및 분류입니다.
KLUE-BERT는 벤치마크 데이터인 KLUE에서 베이스라인으로 사용되었던 모델로, 모두의 말뭉치, CC-100-Kor, 나무위키, 뉴스, 청원 등 문서에서 추출한 63GB의 데이터로 학습되었습니다. Morpheme-based Subword Tokenizer를 사용하였으며, vocab size는 32,000이고 모델의 크기는 111M입니다.
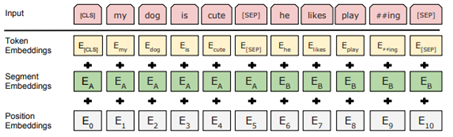
[그림 5] BERT input representation
이미지 출처 : BERT: Pre-training of Deep Bidirectional Transformers for
Language Understanding 논문 참조모델 아키텍쳐
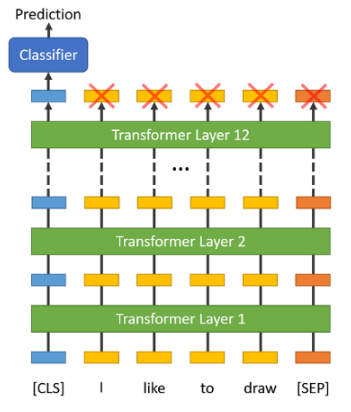
[그림 6] KLUE-BERT 아키텍처
input 전사 스크립트(STT 발화 내용 텍스트 문장), 특정 평가항목(휴지)에 대한 라벨링 데이터 output 입력된 텍스트 문장에서 인식된 태그명에 대한 정보 task 개체명 인식(태깅 탐지) training dataset ㅇ 문장(Sentence)과 태그시퀀스(Tag sequence)로 구성된 학습데이터셋, 검증데이터셋, 테스트데이터셋을 구성하기 위해 데이터 가공 및 정제 수행
- 문장(Sentence)은 STT 발화된 텍스트를 마침표 기준으로 문장 분리하여 구성
- 문장(Sentence) 열에 있는 태그매핑된 발화내용(script_tag_txt)에서 사전에 정의된 태그들을 모두 제거
- 태그시퀀스(Tag sequence) 열은 띄어쓰기 기준으로 음절이 아닌 어절 기준으로 태그시퀀스화 수행
ㅇ 태그시퀀스화 과정에서 태그시퀀스는 라벨링데이터(json) 파일에 있는 태그매핑과 발화된 텍스트가 포함되어 있는 태그매핑된 발화내용(script_tag_txt)으로 생성됨
- 태그명에 해당되지 않는 것은 O라는 태그로 매핑을 시키고 반복어구 가 포함된 어절은 REP-B로 매핑
- 나머지 태그명 중 긴쉼인 , 간투어인 , 발음오류 및 본문과 다른 표현인 이 포함된 어절은 각각 PS-B, FIL-B, WR-B로 매핑하여 학습데이터셋(training dataset) 구성
ㅇ 학습데이터(training dataset) 예시
[그림 7] 학습데이터(training dataset) 예시
training 요소들 ㅇ 손실함수(loss function) :
- 간투어(FIL), 반복어구(REP), 긴쉼(PS), 발음오류(WR) 태그를 제외한 나머지는 O 태그로 매핑
- O는 정수 –100으로 정수인코딩 (인덱스화)
- O 태그(–100)를 제외하고 손실률 계산
ㅇ optimizer : Adam
- 보편적으로 활용되는 최적화함수(Optimizer Function) Adam을 활용
ㅇ epoch : 7
ㅇ learning rate: 5e-5
ㅇ batch size: 32evaluation metric 유효성 검증
목표 지표: F1-점수(F1-Score) 64% 이상
달성 수치 : F1-score 65.93
- f1: 65.93
precision recall f1-score support
FIL 0.89 0.91 0.90 831
PS 0.75 0.94 0.83 16
REP 0.80 0.75 0.77 848
WR 0.51 0.28 0.36 1294
micro avg 0.75 0.59 0.66 2989
macro avg 0.74 0.72 0.72 2989
weighted avg 0.70 0.59 0.63 2989
·- 비언어적
유형 설명 모델명 STGCN++ 모델 설명 STGCN++ 모델은 기존 STGCN에 수정을 하여 강력한 인식 성능과 계산 오버헤드를 줄인 모델로서 특히 공간 그래프 컨볼류션과 시간 모듈을 통합하여 디자인을 수정한 모델입니다.
Skeleton-based action recongnition 알고리즘을 벤치마킹하여 최선의 성능 달성한 모델로서 PYSKL 툴킷을 제공하여 모델 사용 효율성 또한 제공합니다.
또한 Openmmlab의 mmAction2 프레임워크에도 SOTA 모델로 제공되고 있어 사용편의성이 높습니다.
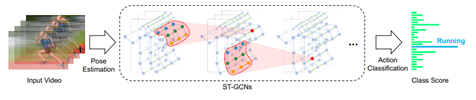
[그림 8] STGCN++ model classification
모델 아키텍쳐 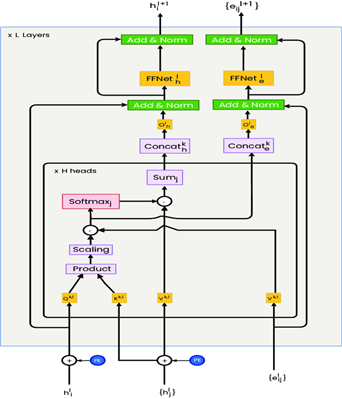
[그림 9] STGCN 모델 아키텍처
input 사람의 전신이 보이는 영상, 사람의 동작 시퀀스마다의 스켈레톤 라벨링 데이터 output 입력된 영상에 대한 동작의 분류 정보 task 동작 인식 및 분류 training dataset
ㅇ 연속된 동작 시퀀스가 포함된 영상과 스켈레톤 데이터로 구성된 학습 데이터셋, 검증 데이터셋, 테스트 데이터셋을 구성하기 위해 가공 및 정제 수행
- 영상은 발표자의 동작 영상중 각 동작의 시작 프레임부터 끝 프레임까지의 연속된 프레임중 10개의 프레임을 샘플링하여 구성
- 샘플링한 연속된 프레임에서 사람의 관절 키포인트를 찍어 가공하여 동작의 연속성을 포함한 시퀀스 스켈레톤 데이터 확보
ㅇ 학습데이터(training dataset) 예시
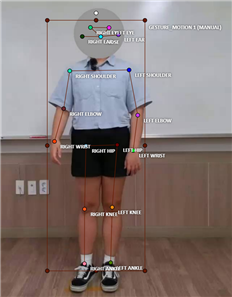
[그림 10] 학습데이터예시활용서비스
모델학습:
STGCN++은 기존 STGCN에 수정을 하여 강력한 인식성능과 계산 오버헤드를 줄인 모델로 특정 동작의 연속에 대한 스틸-컷 이미지들의 라벨링 데이터를 바탕으로 학습, 검증, 시험, 8:1:1 로 데이터를 나누어 학습합니다.
STGCN++ 제스처 식별 모델 개발 단계:
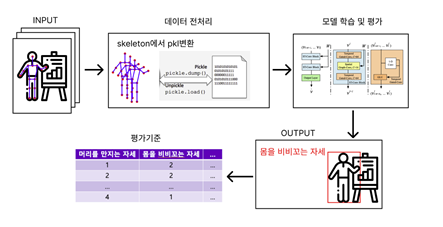
[그림 11] STGCN++ 제스처 식별 모델 개발 단계 -
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드- 데이터 설명
- 공적 말하기 실습 및 평가를 위한 언어적·비언어적 평가 루브릭 학습용 데이터- [언어적] 데이터 구성
항 목 설 명 타입 speaker age_flag 연령 구분 String gender 성별 String job 직업 String aud_flag 청중 구분 String presentation presen_topic 발표주제 String presen_type 발표분류 String presen_location 발표장소 String presen_script 발표 스크립트 원문 String presen_difficulty 발표 난이도 String script start_time 발화 시작시간 String end_time 발화 종료시간 String script_stt_txt 발화 내용(STT) String script_tag_txt 발화 내용(태그매핑) String syllable_cnt 음절수 Number word_cnt 발화 글자수(어절 수) Number audible_word_cnt 청자가 명료하게 들은 어절 수 Number sent_cnt 문장 수 Number evaluations evaluation eval_id 평가자 id String eval_flag 평가자 구분 String eval_grade 총체적 평가 등급 String repeat repeat_cnt 반복/수정 횟수 Number repeat_scr 반복/수정 점수 Number filler_words filler_words_cnt 간투어 횟수 Number filler_words_scr 간투어 점수 Number pause pause_cnt 휴지 횟수 Number pause_scr 휴지 점수 Number wrong wrong_cnt 발음 오류 횟수 Number wrong_scr 발음 점수 Number voice_quality voc_quality 음성 질 String voc_quality_scr 음성 질 점수 Number voice_speed voc_speed 음성 속도 Float voc_speed_sec_scr 음성 속도 점수 Number taglist tag_id 태그번호 String tag_keyword 태그키워드 String tag_type 태그 유형 Integer average repeat_scr 반복/수정 평균 점수 Float filler_words_scr 간투어 평균 점수 Float pause_scr 휴지 평균 점수 Float wrong_scr 발음 평균 점수 Float voc_quality_scr 음성 질 평균 점수 Float voc_speed_sec_scr 음성 속도 평균 점수 Float eval_grade 총체적 평가 평균 등급 String info filename 파일명 String id 파일 id String date 평가일자 String formats 포맷 String ▲ 표 1 – [언어적] 데이터 구성
- [비언어적] 데이터 구성
항 목 설명 타입 데이터셋 종류 dataset 데이터셋 기본정보 Object id 제스처 데이터 ID String name 파일명 String duration 영상 전체 시간 String resolution 영상 해상도 String 제스처 모션 키포인트 annotation 라벨링정보 String jpg_filename 스틸컷 파일명 String frame_count 스틸컷 프레임수 String keypoints 키포인트 배열 Array 발표자 및 발표내용 메타정보 metadata 라벨링 대상 객체 및 동작정보 String situation 발표분류 Array gesture_type 평가대상 String 제스처 분류 subject 발표주제 String gender 집단분류 String gesture_eval 제스처 긍부정 String 키포인트 메타정보 class 키포인트 라벨 정보 String id 키포인트 위치 번호 Array name 키포인트 위치 이름 String type 포인트 타입 String color 포인트 RGB 색상정보 String ▲ 표 2 - [비언어적] 데이터 구성
- [언어적] 어노테이션 포맷
구분 속성명 타입 필수여부 설명 범위 비고 1 speaker object Y 발표자 - - 1-1 age_flag string Y 연령 구분 A00/A01/A02/A03/A04/A05 A00: 중학교 3학년,
A01: 고등학생,
A02: 20대, A03: 30대, A04: 40대,
A05: 50대 이상1-2 gender string Y 성별 남자/여자 1-3 job string N 직업 중학생/고등학생/
직장인/
주부/(이하생략)대학생 1-4 aud_flag string Y 청중 구분 AD05/AD6-10/AD11-30/AD31-50/AD51-100/AD100 AD05: 5인 이하, AD6-10: 6~10인 이하, AD11-30: 11~30인 이하,
AD31-50: 31~50인 이하,
AD51-100: 51~100인 이하,
AD100: 100인 이상2 presentation - Y 발표 - - 2-1 presen_topic string Y 발표주제 A00_B_01 연령구분_주제_소주제
[연령구분]
A00: 중학교 3학년,
A01: 고등학생,
A02: 20대, A03: 30대, A04: 40대, A05: 50대 이상
[주제]
A~I
[소주제]
01~2-2 presen_type string Y 발표분류 S01/S02/S03 S01: 설명, S02: 주장, S03: 찬성/반대 2-3 presen_location string Y 발표장소 학교, 강의실, 회의실, 강당 (이하생략) 학교 2-4 presen_script string Y 발표 스크립트 원문 안녕하세요 여러분, 오늘은 저희가 존경하는 반*문 총장에 대해 이야기하고자 합니다. 그의 인류 평화와 지속가능한 발전을 향한 노력은 우리의 삶과 미래에 큰 영향을 미치고 있습니다.
(이하생략)안녕하세요 여러분, 오늘은 저희가 존경하는 반*문 총장에 대해 이야기하고자 합니다. 그의 인류 평화와 지속가능한 발전을 향한 노력은 우리의 삶과 미래에 큰 영향을 미치고 있습니다.
(이하생략)2-5 presen_difficulty string Y 발표 난이도 H/M/L H: 상, M: 중, L: 하 3 script object Y 전사 스크립트 - - 3-1 start_time string Y 발화 시작시간 0:00 0:00 3-2 end_time string Y 발화 종료시간 0:00 6:41 3-3 script_stt_txt string Y 발화 내용
(STT)안녕하세요 여러분, 오늘은 저희가 존경하는 반*문 총장에 대해 이야기하고자 합니다.그의 인류 평화와 지속 가능한 발전을 향한 노력은 우리의 삶과 미래의 가장 오 큰 영향을 미치고 있습니다.
(이하생략)- 3-4 script_tag_txt string Y 발화 내용
(태그매핑)안녕하세요 여러분, 오늘은 저희가 존경하는 반*문 총장에 대해 이야기하고자 합니다.그의 인류 평화와 지속 가능한 발전을 향한 노력은 우리의 삶과 미래의 가장 오 큰 영향을 미치고 있습니다.
(이하생략)O : 평가항목외
FIL : 간투어
REP : 반복수정
PS : 휴지(5초 이상의 긴쉼)
WR : 발음오류/본문과 다른 표현3-5 syllable_cnt number Y 음절수 0~ 620 3-6 word_cnt number Y 발화 글자수 0~ 340 (어절 수) 3-7 audible_word_cnt number Y 청자가 명료하게 들은 어절 수 0~ 302 3-8 sent_cnt number Y 문장 수 0~ 2 4 evaluation object Y 평가 - - 4-1 eval_id string Y 평가자 id P01 전문가: P01~P10
준전문가: P11~P20
일반인: WP01~WP204-2 eval_flag string Y 평가자 구분 expert 전문가: expert,
준전문가: semi-expert,
일반인: person4-3 eval_grade string Y 총체적 평가 등급 A+/A0/B+/B0/C+/C0/D+/D0F A0 5 repeat - Y 반복/수정 평가 - - 5-1 repeat_cnt number Y 반복/수정 횟수 0~ 4 5-2 repeat_scr number Y 반복/수정 점수 1~5 3
[평가자가 일반인일 경우 NULL]6 filler_words object Y 간투어 평가 - - 6-1 filler_words_cnt number Y 간투어 횟수 - 6 6-2 filler_words_scr number Y 간투어 점수 1~5 2
[평가자가 일반인일 경우 NULL]7 pause object Y 휴지 평가 - - 7-1 pause_cnt number Y 휴지 횟수 - 4 7-2 pause_scr number Y 휴지 점수 1~5 5 [평가자가 일반인일 경우 NULL] 8 wrong object Y 발음 평가 - - 8-1 wrong_cnt number Y 발음 오류 횟수 - 10 8-2 wrong_scr number Y 발음 점수 1~5 4 [평가자가 일반인일 경우 NULL] 9 voice_quality object v 음성 질 평가 - - 9-1 voc_quality string Y 음성 질 VCQ05 VCQ05: 떨림이나 끊김이 없음, VCQ04: 떨림이나 끊김이 약간 있음, VCQ03: 떨림이나 끊김이 보통임, VCQ02: 떨림이나 끊김이 약간 많음, VCQ01: 떨림이나 끊김이 매우 많음 [평가자가 일반인일 경우 NULL] 9-2 voc_quality_scr number Y 음성 질 점수 1~5 5 [평가자가 일반인일 경우 NULL] 10 voice_speed object v 음성 속도 평가 - - 10-1 voc_speed float Y 음성 속도 0~ 5점: 초당 음절수(SPS) 5.2 이상 5.5 미만,
4점: 5.0이상 5.2미만 또는 5.5이상 5.7미만,
3점: 4.8이상 5.0미만 또는 5.7이상 5.9미만,
2점: 4.6이상 4.8미만 또는 5.9이상 6.1미만,
1점: 4.6미만 또는 6.1이상
[평가자가 일반인일 경우 NULL]10-2 voc_speed_sec_scr number Y 음성 속도 점수 1~5 4
[평가자가 일반인일 경우 NULL]11 taglist array Y 태그정보 - "taglist" : [{"tag_id" : "KW018417", "tag_keyword" : "영향", "tag_type" : 2}, {"tag_id" : "KW018418", "tag_keyword" : "가장", "tag_type" : 4}, { "tag_id" : "KW018419", "tag_keyword" : "강국의", "tag_type" : 4 , { tag_id" : "KW018420", tag_keyword" : "자성과", tag_type" : 4
}, { tag_id" : "KW018421", "tag_keyword" : "오", "tag_type" : 1, { tag_id" : "KW018422", "tag_keyword" : "의", tag_type" : 1 } ]11-1 tag_id string Y 태그번호 KW0001~ KW018417 11-2 tag_keyword string Y 태그키워드 영향 11-3 tag_type integer Y TAG 유형 2 1 : FIL(간투어)
2 : REP(반복수정)
3 : PS(휴지)
4 : WR(발음오류)12 average object Y 평균 - 12-1 repeat_scr float Y 반복/수정 평균 점수 4.3 12-2 filler_words_scr float Y 간투어 평균 점수 3 12-3 pause_scr float Y 휴지 평균 점수 3.3 12-4 wrong_scr float Y 발음 평균 점수 4.6 12-5 voc_quality_scr float Y 음성 질 평균 점수 3.4 12-6 voc_speed_sec_scr float Y 음성 속도 평균 점수 3.6 12-7 eval_grade string Y 총체적 평가 평균 등급 C+ 13 info object Y 정보 - - 13-1 filename string Y 파일명 A05_A_01_001_02_WA_MO_presentation.json 연령구분_주제_소주제_발표자순번_영상/제스처/음성구분_음성병합여부_비식별화여부_presentation.json
[연령구분]
A00: 중학교 3학년,
A01: 고등학생,
A02: 20대, A03: 30대, A04: 40대,
A05: 50대 이상
[주제] A~I
[소주제] 01~
[발표자순번] 001~
[영상/제스처/음성구분]
01: 제스처
02: 영상
03: 음성
02 (고정값)
[음성병합여부]
WA (고정값)
[비식별화여부]
MO (고정값)13-2 id string Y 파일 id EVAL_0001~ EVAL_0001 13-3 date string Y 평가일자 20230615 YYYYMMDD 13-4 formats string Y 포맷 *.json *.json ▲표 3 [언어적] 어노테이션 포맷
- [비언어적] 어노테이션 포맷
구분 항목명 타입 필수여부 설명 범위 or 설명 비고 1 dataset Object 데이터셋 기본정보 1-1 id String Y 제스처 데이터 ID 0~999999999 1-2 name String Y 파일명 1-3 duration String Y 영상 전체 시간 0.00 ~ 9999.99 1-4 resolution String Y 영상 해상도 2 annotation Array 라벨링정보 2-1 jpg_filename String Y 스틸컷 파일명 스틸컷 프레임에 해당하는 파일이름 2-2 frame_count String Y 스틸컷 프레임수 0 ~ 999999 2-3 keypoints String Y 키포인트 배열 해당 영상 프레임 별 이미지에 대한 모든 키포인트 정보 포함
예) 30 프레임 제스처의 경우 30 프레임의 개별 키포인트가 프레임 순서대로 배열로 저장[533.2, 859.2] 3 metadata Array 라벨링 대상
객체 및
동작정보3-1 situation String Y 발표분류 S01 : 설명
S02 : 주장
S03 : 찬성/반대3-2 gesture_type String Y 평가대상
제스처 분류B01 : 손동작/머리
B02 : 손동작/얼굴
B03 : 손동작/몸긁기
B04 : 손동작/손톱
B05 : 머리동작/고개흔들기
B06 : 머리동작/좌우흔들기
B07 : 머리동작/숙이기
B08 : 팔동작/뒷짐
B09 : 팔동작/무의미반동
B10 : 자세/좌우흔들기
B11 : 자세/비스듬히
B12 : 자세/비비꼬기3-3 subject String Y 발표주제 주제이름 3-4 gender String Y 집단분류 남자/여자 3-5 gesture_eval String Y 제스처 긍부정 긍정/부정/중립 4 class Array 키포인트 라벨
정보4-1 id String Y 키포인트 위치
번호00 ~ 32 4-2 name String Y 키포인트 위치
이름K14: 오른쪽 눈
K16: 오른쪽 귀
K00: 코
K15: 왼쪽 눈
K17: 왼쪽 귀
K02: 오른쪽 어깨
K05: 왼쪽 어깨
...
K10: 오른쪽 발목
K13: 왼쪽 발목
…그림 참조 4-3 type String Y 포인트 타입 “point” 고정 4-4 color String Y 포인트 RGB 색상정보 000000 ~
FFFFFF▲표 4 [비언어적] 어노테이션 포맷
- [언어적] 데이터 예시
언어적 평가데이터 정제/가공 결과물 speaker age_flag A00 gender 여자 job 중학생 aud_flag AD6-10 presentation presen_topic A00_C_01 presen_type S01 presen_location 학교 presen_script 안녕하세요 여러분, 오늘은 저희가 존경하는 반*문 총장에 대해 이야기하고자 합니다. 그의 인류 평화와 지속가능한 발전을 향한 노력은 우리의 삶과 미래에 큰 영향을 미치고 있습니다. 반*문 총장을 존경하는 이유에 대해 말씀 드리겠습니다.\n\n첫째로, 반*문 총장은 국제 사회에서의 뛰어난 리더십과 민주주의를 존중하는 모습으로 우리의 존경을 받고 있습니다. … presen_difficulty L script start_time 0:00 end_time 2:40 script_stt_txt 안녕하세요 여러분, 오늘은 저희가 존경하는 반*문 총장에 대해 이야기하고자 합니다.그의 인류 평화와 지속 가능한 발전을 향한 노력은 우리의 삶과 미래의 가장 오 큰 영향을 미치고 있습니다.반*문 총장을 존경하는 이에 대해 말씀드리겠습니다.첫째로 반*문총장은 국제 사회에서에뛰어난 리더십과 민주주의를 존중하는 모습으로 우리의 존경을 받고 있습니다. … script_tag_txt 안녕하세요 여러분, 오늘은 저희가 존경하는 반*문 총장에 대해 이야기하고자 합니다.그의 인류 평화와 지속 가능한 발전을 향한 노력은 우리의 삶과 미래의 가장 오 큰 영향을 미치고 있습니다.반*문 총장을 존경하는 이에 대해 말씀드리겠습니다.첫째로 반*문총장은 국제 사회에서에뛰어난 리더십과 민주주의를 존중하는 모습으로 우리의 존경을 받고 있습니다.그는 UN 사무총장으로서 국가 간의 갈등을 조정하고 세계 평화를 위한 노력을 기울였습니다.그의 지도력은 세계 강국의 정상들과의협력을 강화하고… ▲ 표 5 [언어적] 데이터 예시
- [비언어적] 데이터 예시
가공전 ![[비언어적] 원본 데이터 예시](/web-nas/aihub21/files/editor/2024/04/af643537fec1483795fa64c0ffd37e13.png)
▲ 그림 1 – [비언어적] 원본 데이터 예시가공후 ![[비언어적] 가공 후 데이터 예시](/web-nas/aihub21/files/editor/2024/04/9cfcd4ad748146bcad7fdc0b962ff1cd.png)
▲ 그림 2 – [비언어적] 가공 후 데이터 예시- [언어적] 라벨링 데이터 json 형식
![[언어적] 라벨링 데이터 json 형식](/web-nas/aihub21/files/editor/2024/04/5dd258e728b1488c8d1d9ae76600773f.png)
▲ 그림 3 – [언어적] 라벨링 데이터 json 형식- [비언어적] 라벨링 데이터 json 형식
![[비언어적] 라벨링 데이터 json 형식](/web-nas/aihub21/files/editor/2024/04/4ea1309cacff4b04944dbf59e8608272.png)
▲ 그림 4 – [비언어적] 라벨링 데이터 json 형식 -
데이터셋 구축 담당자
수행기관(주관) : ㈜ 유핏
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 김희곤 1544-9370 koscokim@ufits.co.kr 사업총괄 관리, 데이터 수집, 언어적 정제, 가공, 저작도구 수행기관(참여)
수행기관(참여) 기관명 담당업무 헬스클라우드(주) 비언어적 정제, 가공 ㈜지뉴소프트 언어적 AI모델 ㈜에이뉴트 비언어적 가공, AI모델, 저작도구 데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 ㈜유핏 안동철 070-4012-1836 ceo@ufits.co.kr AI모델 관련 문의처
AI모델 관련 문의처 담당자명 전화번호 이메일 ㈜지뉴소프트 최창원 02-3463-0802 cw.choi@gnewsoft.com 저작도구 관련 문의처
저작도구 관련 문의처 담당자명 전화번호 이메일 ㈜에이뉴트 조민택 02-6225-2095 contextminer@ainewt.ai
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기] [공용IRB 심의신청 가이드라인]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 safezone1@aihub.kr 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.