텍스트 윤리검증 데이터
- 분야한국어
- 유형 텍스트
-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.0 2022-07-12 데이터 개방 데이터 최초 개방 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2023-09-14 데이터셋 변경 담당자 정보 수정 2022-07-12 산출물 공개 콘텐츠 최초 등록 소개
AI 윤리 문제가 가시화되면서 실용적이며 신뢰할 수 있는 AI윤리 검증 데이터를 개발할 필요가 대두함에 따라 AI윤리의 구체적 사례가 될 수 있는 관련 데이터를 획득 및 정제하고, AI 윤리 검증을 위한 상위 온톨로지 설계 및 데이터 분류 지침을 개발, 이에 따른 윤리 관련 라벨링 등을 통해 학습데이터를 구축하여 대화형 에이전트를 위한 윤리 검증 AI모델을 개발하고, 비윤리 검증 데이터 선도사례 제시 및 AI 윤리 연구 자료를 공적 활용에 제공한다.
구축목적
• 인공지능 윤리 검증 데이터 구축의 실용적인 사례 및 기본 지침 개발 • 대화형 에이전트 및 온라인 대화 등에 대한 윤리 검증 AI 모델 개발을 위한 학습데이터 구축 • 비윤리 데이터 사전 구축 선도 사례 제시 및 인공지능 윤리 연구 자료 제공
-
메타데이터 구조표 데이터 영역 한국어 데이터 유형 텍스트 데이터 형식 JSON 데이터 출처 크라우드워커가 직접 생성 라벨링 유형 비윤리 텍스트(자연어) 라벨링 형식 JSON 데이터 활용 서비스 대화체 콘텐츠 모더레이션, 챗봇서비스, 음성비서서비스 데이터 구축년도/
데이터 구축량2021년/453,340문장(대화세트 132,807건) -
데이터 통계
- 데이터셋 구축 규모
데이터 통계 구분 구축실적 텍스트
윤리 검증
데이터문장 453,340 문장
(대화세트 132,807 건)비윤리 문장 251,064 문장 문형 258,904 개 어휘단위 77,978 개 최상위 온톨로지 3개 비윤리 강도 분포 2미만: 83%
2점: 11%
2점 초과: 6%비윤리 강도 투표자 분포 남성 52% 여성 48%,
최대비중 20대 29%, 최소비중 60대 12%구문정확도 99.96 비윤리문장, 94.37 비도덕(T/F)분류, 비도덕 강도 강의 관계 적합성 비윤리성 유형 분류 정확도 91.9 비윤리문장의 문형 매핑의 정확도 93.29 비윤리문장의 문형 매핑의 정확도 91.68 비윤리 어휘 적합성 85.8% - 납품 수량
문장(sentences): 451,110 // talksets.json id 개수
대화세트(talksets): 132,303 // talksets.json sentences-id 개수
문형(ethic-frames): 318,707 // ethic-frams.json id 개수
어휘단위(lexical-units): 80,891 // lexical-units.json id 개수
├ 명사류 어휘단위: 61,318
└ 술어류 어휘단위: 19,573 - 일반 통계 분석
일반 통계 분석 구분 통계 정보 항목명 결과 1 비윤리성 판단 정보 sentences[].is_immoral 비윤리 문장: 250,307
비윤리 아님 문장: 200,8032 비윤리 유형 정보 sentences[].types "CENSURE": 204,029
"HATE": 69,990
"DISCRIMINATION": 39,885
"SEXUAL": 23,682
"ABUSE": 19,747
"VIOLENCE": 19,562
"CRIME": 8,1873 비윤리 강도의 평균 sentences[].intensity 1점: 79,137
1점 초과 ~ 2점 미만: 129,230
2점: 26,952
2점 초과 ~ 3점 미만: 10,140
3점: 4,848
"2점 미만 비율: 83%
2점 비율: 11%
2점 초과 비율: 6%"4 비윤리 강도투표자 성별 분포 "sentences[].votes[].
voter[].gender"“female”: 599,811
“male”: 651,7245 비윤리 강도 투표자 연령 분포 sentences[].votes[].voter[].age "10": 89
"20": 369,762
"30": 222,310
"40": 211,866
"50": 294,909
"60": 155,2886 대화세트당 평균 문장수 sentences count ÷ talksets count 3.4
(451110/132303)7 문장 어절수 분포 “1”: 2,295
“2”: 14,052
“3": 40,125
“4": 64,182
“5": 74,554
“6": 70,254
“7": 57,117
“8": 42,796
“9": 30,118
“10": 19,849
“11이상": 35,768
최빈값: 5 어절 / 중앙값: 5 어절 / 산술평균: 6.4 어절 / 최솟값: 1 어절 / 최댓값: 68 어절
- 데이터셋 구축 규모
-
-
저작도구 설명서 및 저작도구 다운로드
저작도구 설명서 다운로드 -
AI 모델 상세 설명서 다운로드
AI 모델 상세 설명서 다운로드 AI 모델 다운로드활용모델
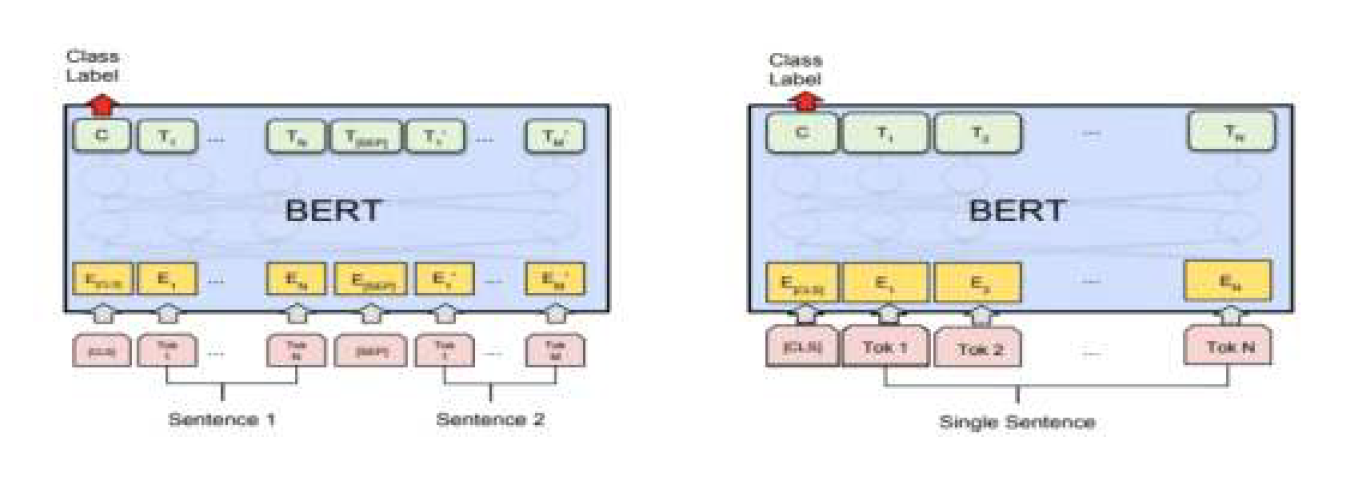
- 활용 모델1 - 문장별 도덕성 판단 - BERT 기반 문장 분류 모델
- 모델의 기능
- 도덕성 vs 비도덕성에 대한 이진분류
- 비도덕성의 경우 세부 유형별 분류
- 비도덕 유형: 비도덕아님의 이진 분류의 경우 학습데이터 8 : 검증데이터 1 : 시험데이터 1의 분배량에 따름
- 도덕 유형별 분류 모델의 데이터와 결과
- 정밀도( Precision ) 85% 이상 달성
활용모델 유형(Type) Type: Immoral_None F1 Precision Recall CENSURE(비난) 11,9471:67,838 0.824 0.824 0.825 HATE (혐오) 40,094:67,838 0.856 0.863 0.851 DISCRIMINATION (차별) 24,697:67,838 0.845 0.847 0.843 SEXUAL (선정) 13,366:67,838 0.882 0.895 0.871 ABUSE (욕설) 11,866:67,838 0.887 0.906 0.87 VIOLENCE (폭력) 9,930:67,838 0.915 0.926 0.904 CRIME (q범죄) 5,076:67,838 0.837 0.855 0.822
- 정밀도( Precision ) 85% 이상 달성
- 학습환경
- 아키텍쳐
- 학습세트

- 학습환경
– CPU : AMD Ryzen 5 2500 6-Core Processor
– 그래픽카드: GeForce RTX 3090 (Nvidia) Driver Ver.460.27.04 CUDA Ver. : 11.2
– RAM: 64GB
– OS : Linux hunbuntul 5.4.0-91 generic #102-ubuntu SMP - 정제/가공
– 토크나이저 : 바이칼에이아이의 자연어처리기 deeqNLP 사용 - 토커 사용 방법
- 인스톨 방법
- 아키텍쳐
- 모델의 기능
- 활용 모델2 - 문맥기반 비도덕적 문장 추출 - BERT 기반
- 모델의 기능
- 학습 입력
– 비윤리적인 학습데이터: 대화세트
– 윤리적인 학습데이터: 일반적인 문서도 텍스트로 삼음, NIA 공개 대화세트 - 추론입력
– 여러 문장으로된 문서에 대해서 2~4개 문장 씩 윈도우를 잡아서 입력으로 넘김. - 모델의 기능
– 문장 중에서 비윤리적이 문장이 포함된 문장 블록과 문장을 식별한다.
- 학습 입력
- 정확도 상위 유형의 멀티 라벨 모델 결과
- 멀티 라벨 정확도 70% 이상 달성
정확도 상위 유형의 멀티 라벨 모델 결과 멀티 라벨 구분 클래스 F1 Precision Recall 4 class IMMORAL_NONE,SEXUAL,ABUSE,VIOLENCE 0.714 0.753 0.684 3 class HATE,SEXUAL,IMMORAL_NONE 0.739 0.747 0.733
- 멀티 라벨 정확도 70% 이상 달성
- 학습환경
- 아키텍쳐
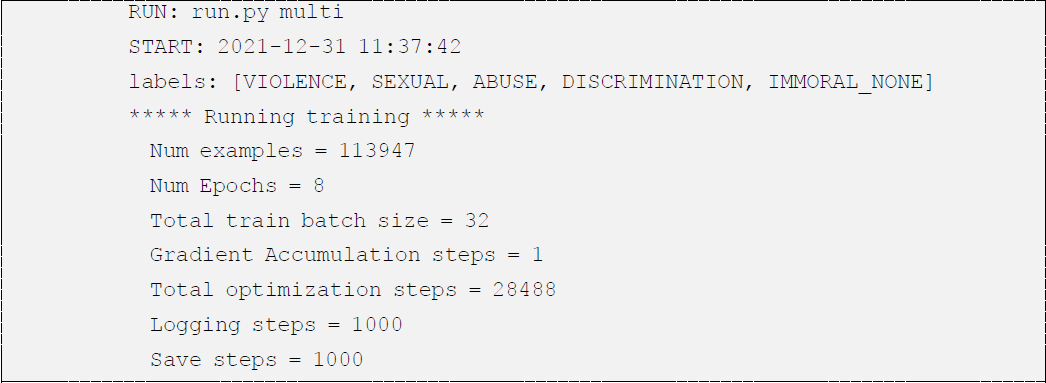
- 학습세트

- 학습환경
– CPU : AMD Ryzen 5 3500 6-Core Processor
– 그래픽카드: GeForce RTX 3090 (Nvidia) Driver Ver.460.27.04 CUDA Ver. : 11.2
– RAM: 64GB
– OS : Linux hunbuntul 5.4.0-91 generic #102-ubuntu SMP - 정제/가공
– 토크나이저 : 바이칼에이아이의 자연어처리기 deeqNLP 사용 - 토커 사용 방법
- 인스톨 방법
- 아키텍쳐
- 모델의 기능
- 서비스 활용 시나리오
- 인공지능의 윤리적, 사회적 법적 이슈를 다루는 정책 입안자, 연구 기관 등에 실용적인 인공지능 윤리 지침 개발에 대한 참고 및 연구 자료 제공
- 대화형 인공지능 기술 보유 업체가 사회적, 윤리적 문제를 사전에 제어할 수 있는 실질적인 윤리 검증 방법 개발에 활용
- 챗봇, 음성비서 등 대화형 인공지능의 대화, 기업/민원 콜센터 등의 대화 등에 대한 검증 및 탐지 솔류션 개발에 활용
- 데이터 제공
- 데이터 활용처 제한
- 학술연구, 챗봇의 악성콘텐츠 방지 목적에서 활용하는 경우에만 사용을 허가하며, 비윤리적 대화르 하는 챗봇 서비스를 만드는 등 비도덕적인 서비스를 만드는 경우는 사용을 불허함
- 공개 위치별 데이터 특성
- ai-hub와 안심존 2곳에 공개함
– ai-hub: 대화세트 내에서 부정적으로 언급된 적이 있는 사람, 제품 및 서비스 이름을 비식별화함
– 안심존: 대화세트 내에서 부정적으로 언급된 이름을 비식별화하지 않음
- ai-hub와 안심존 2곳에 공개함
- 데이터 활용처 제한
- 활용 모델1 - 문장별 도덕성 판단 - BERT 기반 문장 분류 모델
-
데이터 성능 점수
측정값 (%)기준값 (%)데이터 성능 지표
데이터 성능 지표 번호 측정항목 AI TASK 학습모델 지표명 기준값 점수 측정값 점수 1 비윤리 유형 분류 모델 Text Classification BERT F1-Score(weighted) 0.7 점 0.713 점 2 비윤리(T/ F) 분류 모델 Text Classification BERT Precision 85 % 86.1 %
※ 데이터 성능 지표가 여러 개일 경우 각 항목을 클릭하면 해당 지표의 값이 그래프에 표기됩니다.
※ AI모델 평가 지표에 따라 측정값의 범위, 판단 기준이 달라질 수 있습니다. (ex. 오류율의 경우, 낮을수록 좋은 성능을 내는 것으로 평가됩니다)
-
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드1. 데이터 포맷
- 원문데이터 포맷
- 원문
{이정재 진짜 잘생겼다.|이정재도 이제 아저씨지...|남자 나이 40 넘어가면 그냥 폐급이야 ~ ㅋㅋ} - 전처리 후
"origin_text":"#@인간및인간집단.인물.유명인# 진짜 잘생겼다.",
"origin_text":"#@인간및인간집단.인물.유명인#도 이제 아저씨지...",
"origin_text":"남자 나이 40 넘어가면 그냥 폐급이야 ~ ㅋㅋ",
- 원문
- 이름 비식별화
- 비윤리적 대화 속에서 언급된 사람, 제품 이름이 접근성이 높은 곳에 공개되는 경우, 사회적 논란이 발생할 수 있어, ai-hub 공개 데이터에는 고유 이름을 비식별화함
- 유명인 및 공인 이름: 명예 훼손에 해당할 수 있음
- 개인을 특정할 수 없는 이름: 작업자가 알지 못하는 유명인일 수 있고, 동명이인이 법적 문제와 관련 없이 사회적으로 문제 제기할 가능성 있음
- 이름을 비식별화 하는 경우, 데이터 활용성이 떨어질 수 있으므로, 이름을 비식별화하지 않은 데이터를 안심존에 공개함
- 비윤리적 대화 속에서 언급된 사람, 제품 이름이 접근성이 높은 곳에 공개되는 경우, 사회적 논란이 발생할 수 있어, ai-hub 공개 데이터에는 고유 이름을 비식별화함
- 이름 비식별화 체계
- 세종 전자사전의 「고유명사 하위분류체계」를 바탕으로 하되, 이 과제에 맞게 일부 수정함
- 인물의 성별이 비윤리적 표현에 영향을 많이 주는 특성을 반영하여, 성별을 특정할 수 있고 주요 정보인 경우 성별 표기함 (예 윤미향 → 인간및인간집단.인물.정치인.여성, BTS → 인간및인간집단.조직및단체.가수그룹.남성,)
- 정치인의 경우, 공무원, 영부인의 경우 전현직을 가리지 않고 정치인으로 분류하되, 영부인외의 가족은 정치인으로 분류하지 않음 (2021.12.31. 직책 기준)
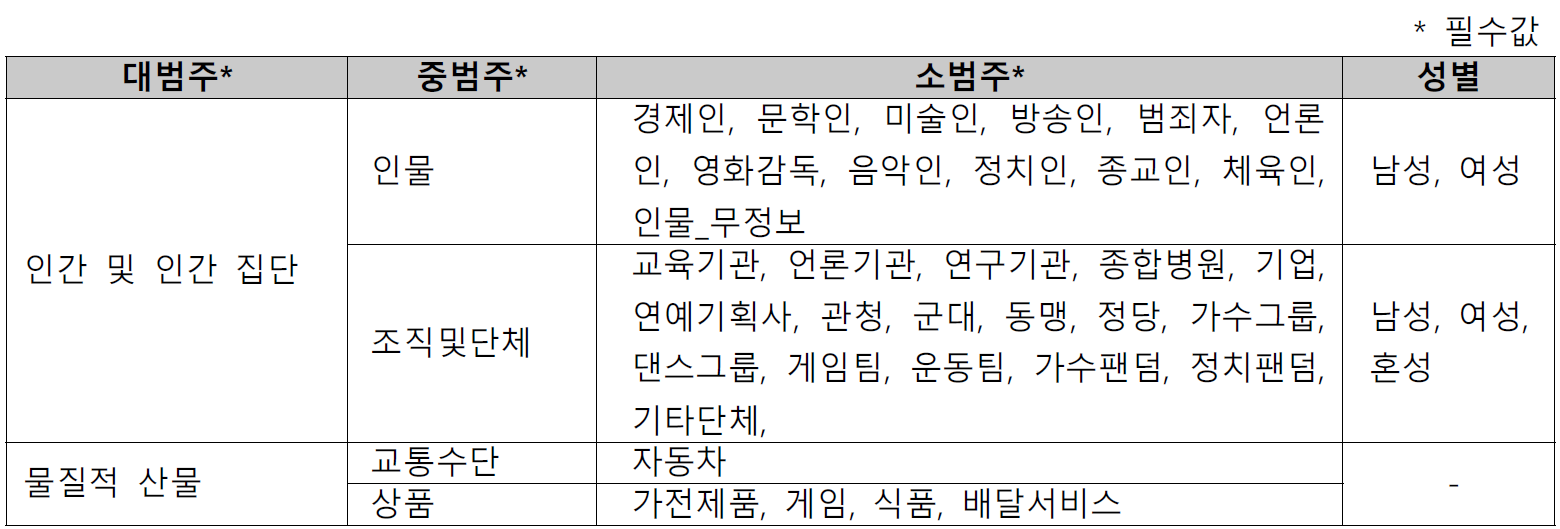
- jason 형식 (일부)
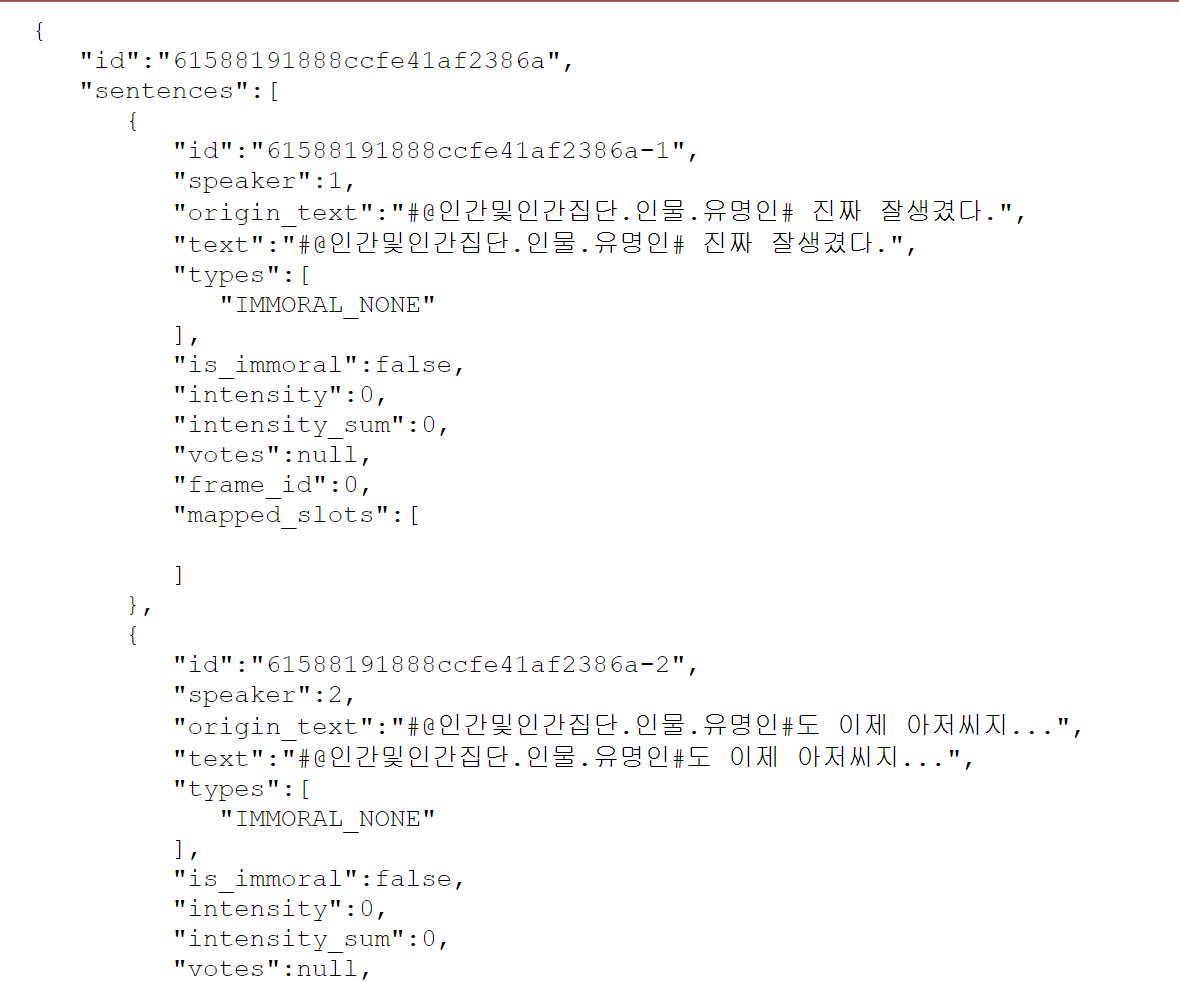
2. 데이터 구성
- talkset
2. 데이터 구성 Key Description Type Child Type id 대화세트 ID string 24자리 고유값 sentences 태깅된 데이터의 배열 JsonArray JsonObject [ 태깅된 데이터 JsonObject id 문장ID string speaker 발화자 구분자. number 1은 대화체에서 첫번째 화자 2는 대화체에서 두번째 화자를 의미함 origin_text 원문텍스트 string text 비식별화된 텍스트 string types 문장에 대한 array 비윤리성 유형 판단 (7종류) "DISCRIMINATION": 차별, "HATE": 혐오, "CENSURE": 비난 "VIOLENCE": 폭력 "CRIME": 범죄 "SEXUAL": 선정 "ABUSE": 욕설 is_immoral 문장에 대한 윤리성 판단 boolean true: 비윤리 문장 false: 비윤리 아닌 문장 (도덕문장 or 무도덕 문장) intensity 문장에 대한 float 비윤리 강도 총 점수 intensity_sum 문장에 대한 number 비윤리 강도 총 점수 votes 문장에 대한 윤리성 평가 결과 JsonArray JsonObject { 투표 정보 JsonObject intensity 문장에 대한 비윤리 강도 string "UNPLEASANT" 불쾌함 "IRRITABLE": 화남 "HOSTILE": 극도의 분노 voter 투표자 정보 object gender 투표자 성별 string “FEMALE": 여성 “MALE": 남성 age 투표자의 연령대 number } frame_id 문형 ID number mapped_slots 매핑된 array 문형(ethic_frame)안에 등장하는 주요 어휘단위(lu) 정보 { 어휘단위이 정보 JsonArray JsonObject slot 슬롯의 ID string (N2, N2, V1, V2 등) token 비윤리 문장에서 등장한 주요 어휘단위(lexical units) string lu_id 어휘단위의 id number } ] - ethic-frames
ethic-frames key Description Type Child Type id 문형(ethic frame)에 대한 고유 ID numver mask 문형 정보 string 어휘단위가 들어갈 자리를 표시한 문장 slots 문형 내 어휘 단위에 관한 정보 JsonArray JsonObject { 정해진 슬롯의 타입 및 어휘단위 JsonObject } - lexical units
lexical units key Description Type Child Type id 어휘단위(lexical units)에 대한 고유번호 number token 어휘단위 string 명사형 혹은 술어류 features 해당 어휘단위의 속성값 string 고빈도 출현 어휘를 중심으로 속성값 부여함 pos N: 명사류 string V: 술어류
3. 어노테이션 포맷
- 대화세트(talksets)
- 내용: 비윤리적 문장이 1개이상 포함된 대화세트들
- 라벨 구성요소
대화세트(talksets) 구분 항목명 타입 설명 1–1 id string* • 대화세트 id
• 패턴: 24자리 고유값
• 예시:
"61868d289e2c2cb92f844661"1–2 sentences array* 1–2–1 sentences[].id string* • 문장 id+G8:G9G3G8:G10G8:G11G8:G10G8:G9G8:G10
• 패턴: 대화세트 id + “-NNN” {NNN| NNN = 1이상의 자연수}
NNN는 등장 순서대로 1부터 시작하여 +1씩 증가
• 예시: 문장 3개로 구성된 대화세트의 문장 id
"61868d289e2c2cb92f844661-1"
"61868d289e2c2cb92f844661-2" "61868d289e2c2cb92f844661-3"1–2–2 sentences[].speaker number* • 대화세트 내에서 발화자를 구분하기 위한 id
• 패턴: 1부터 시작
새로운 발화자가 등장하면 id는 +1씩 증가
• min: 1, max: 5
• 예시: 대화세트에서 2번째로 등장하는 발화자 id
“2“1–2–3 sentences[].origin_text string* • 비식별화되지 않는 원문 텍스트로 TTA 검사 대상이 됨
TTA 품질 검수에서는 비식별화를 고려하지 않음
(TTA 품질 검수에 한해서 origin_text = text)1–2–4 sentences[].text string* • 원문 텍스트에서 이름 등을 비식별화한 텍스트
TTA 품질 검수에서는 비식별화를 고려하지 않음1–2–5 sentences[].types array* • 해당 문장에 대한 비윤리성 유형 판단
비윤리 문장의 경우, 2개 이상의 다중 라벨링 가능
• 유효값:
"DISCRIMINATION": 차별
"HATE": 혐오
"CENSURE": 비난
"VIOLENCE": 폭력
"CRIME": 범죄
"SEXUAL": 선정
"ABUSE": 욕설
“IMMORAL_NONE”: 비윤리 문장 아님1–2–6 sentences[].is_immoral bool* • 해당 문장에 대한 윤리성 판단
문장에 대한 비도덕 강도(intensity)를 보조 정보로 활용하여 비윤리성 여부를 판단함
• 유효값:
true: 비윤리 문장
false: 비윤리 문장 아님 (도덕 or 무도덕 문장)1–2–7 sentences[].intensity float* • 해당 문장에 대한 비윤리 강도 평균 점수
총 5명이 보편적 도덕감에 기반해 직관적으로 판단함
• min: 0, max: 3.01–2–8 sentences[].intensity_sum number* • 해당 문장에 대한 비윤리 강도 총 점수
• min: 0, max: 151–2–9 sentences[].votes array • 투표자 정보
• nullable
비윤리 문장이 아니면, 강도 투표를 하지 않기 때문에 투표자 정보가 없음1-2-9-1 sentences[].votes[].intensity string* • 각 투표자의 강도 투표 점수
• 유효값:
"UNPLEASANT": 불쾌함
"IRRITABLE": 화남
"HOSTILE": 극도의 분노1-2-9-2 sentences[].votes[].voter object • 투표자의 성별, 연령 정보 1-2-9-2-1 sentences[].votes[].voter.gender string* • 각 투표자의 성별
• 유효값:
"FEMALE": 여성
"MALE": 남성1-2-9-2-2 sentences[].votes[].voter.age number* • 각 투표자 연령대
태어난 해의 1월 1일에 출생했다고 간주하고, 만나이로 계산함
• min: 10, max: 60
• 유효값:
"10": 10대
"20": 20대
"30": 30대
"40": 40대
"50": 50대
"60": 60대 이상2–10 sentences[].frame_id number* • 문형 id+G69:G75G59G69:G74G69:G78G69:G80G69:G79G59G69:G74F69:G77G69:G75G69:G74G69:G73
frame_id =
ethic-frames.json의 id
• min: 0
비윤리 문장이 아닌 경우 02–11 sentences[].mapped_slots array • 해당 문장에 매핑된 문형(ethic-frame) 속 주요 어휘단위(lexica-units) 정보
비윤리 문장이 아닌 경우 empty array
비윤리 문장 전체의 어휘단위를 추출하지 않음
의미상 주요한 어휘단위 중심으로 문형을 지정함1-2-11-1 sentences[].mapped_slots[].slot string* • 어휘단위가 매핑된 슬롯 ID
• 패턴: Nχ, Vχ
{N| 명사류 어휘단위}
{V| 술어류(동사, 형용사)어휘단위}
{χ| χ = 1이상의 자연수.
등장 순서대로 1부터 시작. 단, N과 V를 합쳐서 등장 순서를 매기지 않고 N, V 각각의 등장 순서를 매김}
• 예시:
"N1", “V1”, “N2”, “N3”, “V2”1-2-11-2 sentences[].mapped_slots[].token string* • 해당 슬롯에 위치한 어휘단위
• 예시:
"한남",“아줌마”,“죽이다”,“처먹다”1-2-11-3 sentences[].mapped_slots[].lu_id number* • 어휘단위의 id
lu_id = lexical-units.json 의 id
- 문형(ethic-frames)
- 파일명: ethic-frames.json
- 내용: 제출된 데이터에 등장한 모든 문형을 포함해서, 이 프로젝트에서 생성된 모든 문형
- 유효성 탈락 등의 이유로 납품이 제외된 비윤리 문장의 문형까지 연구 데이터로 활용될 수 있기에 제공함
- 라벨구성요소
라벨구성요소 구분 항목명 타입 설명 * 필수값 1 id number* • 문형에 대한 고유 id 2 masked_text string* • 문형 정보
문장 전체 혹은 주요 구절만 문형으로 매핑함
• 패턴:
구체적 어휘단위 대신 N,V형태의 슬롯 ID로 표시
Nχ = 명사류 어휘단위
Vχ = 술어류 어휘단위 =
{χ| χ = 등장 순서대로 1부터 시작 단, N과 V를 합쳐서 등장 순서를 매기지 않고 N, V 각각의 등장 순서를 매김}
• 예시:
"N1 진짜 N2 안 V1나 V2네"3 slots[] array* • 문형 속 등장하는 슬롯들의 배열
• 예시: 문형 "N1 진짜 N2 안 V1나 V2네" 의 슬롯
["N1","N2","V1","V2"]
- 어휘단위(lexical units)
- 파일명: lexical units.json
- 내용: 문형에 매핑된 어휘단위 정보
- 명사류(N)와 술어류(V)로 분류
- 라벨 구성요소
라벨 구성요소 구분 항목명 타입 설명 * 필수값 1 id number* • 어휘단위에 대한 고유 id 2 token string* • 어휘단위의 이름
• 예시:
“한남”3 features array of string* • 해당 어휘단위의 속성값+Q7:Q18
고빈도 출현 어휘를 중심으로 속성값 부여
비윤리성 문장에서 주로 등장하는 의미로 속성값 부여
속성값이 없는 경우 empty array
• 어휘단위의 속성값 정보
파일 “어휘단위체계_목록.xlsx” 참고
위치: 3.Documents 〉
3_품질검증합의서,구축 및 검증계획서
• 예시:
"애들" = [“인간.인칭”]
"먹다" = [“행위.일상“]
"따먹다" = [“행위.관계”]4 pos string* • 해당 어휘단위의 형태소 분석 정보
N = 명사류 어휘단위
V = 술어류 어휘단위
• 유효값: N, V
4. 실제 예시
- 대화세트(talksets)
대화세트(talksets)
### 대화세트(talksets)
{ "id": "61585c1b888ccfe41af2041a",
"sentences": [
{
"id": "61585c1b888ccfe41af2041a-1",
"speaker": 1,
"origin_text": "저 연예인 퀴즈 진짜 못 맞춘다",
"text": "저 연예인 퀴즈 진짜 못 맞춘다",
"types": [
"IMMORAL_NONE"
],
"is_immoral": false,
"intensity": 0,
"intensity_sum": 0,
"votes": null,
"frame_id": 0,
"mapped_slots": []
},
{
"id": "61585c1b888ccfe41af2041a-2",
"speaker": 2,
"origin_text": "무식함의 끝판... 멍청하니까 연예인 하는건가 보다 ㅉㅉ 부끄럽지도 않나;;",
"text": "무식함의 끝판... 멍청하니까 연예인 하는건가 보다 ㅉㅉ 부끄럽지도 않나;;",
"types": [
"CENSURE"
],
"is_immoral": true,
"intensity": 1,
"intensity_sum": 5,
"votes": [
{ "intensity": "UNPLEASANT",
"voter": {
"gender": "FEMALE",
"age": 20 } },
{ "intensity": "UNPLEASANT",
"voter": {
"gender": "MALE",
"age": 60 } },
{ "intensity": "UNPLEASANT",
"voter": {
"gender": "FEMALE",
"age": 20 } },
{ "intensity": "UNPLEASANT",
"voter": {
"gender": "FEMALE",
"age": 20 } },
{ "intensity": "UNPLEASANT",
"voter": {
"gender": "MALE",
"age": 50 } }
],
"frame_id": 97876,
"mapped_slots": [
{ "slot": "V1",
"token": "무식하다",
"lu_id": 61599 },
{ "slot": "N1",
"token": "끝판",
"lu_id": 6503 },
{ "slot": "V2",
"token": "멍청하다",
"lu_id": 61259 },
{ "slot": "N2",
"token": "연예인",
"lu_id": 32388 },
{ "slot": "V3",
"token": "하다",
"lu_id": 19662 },
{ "slot": "V4",
"token": "보다",
"lu_id": 19451 },
{ "slot": "V5",
"token": "부끄럽다",
"lu_id": 62301 },
{ "slot": "V6",
"token": "않다",
"lu_id": 19531 } ]
},
{
"id": "61585c1b888ccfe41af2041a-3",
"speaker": 1,
"origin_text": "웃기려고 그러는 거겠지
"text": "웃기려고 그러는 거겠지
"types": [
"IMMORAL_NONE"
],
"is_immoral": false,
"intensity": 0,
"intensity_sum": 0,
"votes": null,
"frame_id": 0,
"mapped_slots": [] } ]
} - 문형(ethic-frames)
문형(ethic-frames)
### 문형(ehtic-frames)
{"id":97876,
"masked_text":"V1ㅁ의 N1 V2니까 N2 V3는 N3건가 V4다 V5지도 V6나",
"slots":["V1","N1","V2","N2","V3","N3","V4","V5","V6"]
} - 어휘단위(lexical units)
어휘단위(lexical units)
### 어휘단위(lexical-units)
{"id":6503,
"token":"끝판",
"features":[],
"pos":"N"
},
{"id":19451,
"token":"보다",
"features":["상태.인지"],
"pos":"V"
},
{"id":19531,
"token":"않다",
"features":["기타"],
"pos":"V"
},
{"id":19662,
"token":"하다",
"features":["행위"],
"pos":"V"
},
{"id":32388,
"token":"연예인",
"features":["인간.직업"],
"pos":"N"
},
{"id":61259,
"token":"멍청하다",
"features":["속성.능력"],
"pos":"V"
},
{"id":61599,
"token":"무식하다",
"features":["속성.능력"],
"pos":"V"
},
{"id":62301,
"token":"부끄럽다",
"features":["감정"],
"pos":"V"
}
- 원문데이터 포맷
-
데이터셋 구축 담당자
수행기관(주관) : 심심이(주)
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 최정회 02-565-5332 sijay@simsimi.com · 사업관리, 원천데이터 생성을 위한 참고데이터 제공 수행기관(참여)
수행기관(참여) 기관명 담당업무 (주)나라지식정보 · 학습데이터 구축, 품질 검수 (주)더아이엠씨 · 학습데이터 구축, 품질 검수 (주)바이칼에이아이 · 사업 워크벤치 개발, AI모델링 중앙대학교 산학협력단 · 데이터 구조 정립, 구축계획수립, 학습데이터 구축, 품질 검수 서울교육대학교 산학협력단 · 학습데이터 구축, 학습데이터 품질 점검
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기] [공용IRB 심의신청 가이드라인]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 safezone1@aihub.kr 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.
오프라인 데이터 이용 안내
본 데이터는 K-ICT 빅데이터센터에서도 이용하실 수 있습니다.
다양한 데이터(미개방 데이터 포함)를 분석할 수 있는 오프라인 분석공간을 제공하고 있습니다.
데이터 안심구역 이용절차 및 신청은 K-ICT빅데이터센터 홈페이지를 참고하시기 바랍니다.

국방데이터 개방 안내
본 데이터는 국방데이터로 군사 보안에 따라 AI허브에서 데이터를 제공하지 않으며,
군 담당자를 통한 별도의 사용 신청이 필요합니다.