한국어-영어 합성 기계번역 품질 예측 데이터셋
- 분야한국어
- 유형 텍스트
-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.0 2022-11-28 데이터 최초 개방 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2022-11-28 콘텐츠 최초 등록 소개
한국어-영어 합성 기계번역 품질 예측 데이터(A Synthetic Quality Estimation Dataset for Korean-English Neural Machine Translation, QUAK)는 한국어 문장과 영어 기계번역 문장을 참조하여 각 문장들에 대한 기계번역 결과 품질을 토큰별 OK/BAD 태그로 예측하는 기계번역 품질 예측 모델 학습 데이터셋이다. 해당 데이터로 학습한 기계번역 품질 예측 모델은 정답 문장이 없이도 번역의 품질을 예측할 수 있으므로 정답 문장이 없는 real-world problems에 적용될 수 있다. 기계번역 결과 중 어떠한 토큰(어절)이 잘못 번역되었는지를 단어별로 OK/BAD 태그하며, 얼라인된 소스토큰에 대해서도 태그를 나타내므로 번역 언어를 모르는 사용자들도 어떤 단어의 번역이 잘못되었는지를 알 수 있다.
구축목적
한국어-영어 기계번역 품질 예측을 위한 모델 학습
-
메타데이터 구조표 데이터 영역 한국어 데이터 유형 텍스트 데이터 형식 txt 데이터 출처 AI-HUB 한국어-영어 번역(병렬) 말뭉치, Wikipedia 라벨링 유형 OK/BAD 시퀀스 (텍스트) 라벨링 형식 txt 데이터 활용 서비스 사용자 입력 문장과 해당하는 기계번역 결과에 대한 토큰별 번역 품질 제공 서비스 데이터 구축년도/
데이터 구축량2021년/학습 데이터: 1,578,002(QUAK-M(1.58M), P, H), 6,578,002(QUAK-M(6.58M)) , 검증 데이터: 12,000 , 평가 데이터: 12,000 -
1. 데이터 구축 규모
- 학습 데이터: 1,578,002(QUAK-M(1.58M), P, H), 6,578,002(QUAK-M(6.58M))
- 검증 데이터: 12,000
- 평가 데이터: 12,000
2. 데이터 분포
* 표 설명:
- #: 개수, Source Sentences: 소스 문장, MT Output: 번역 문장, pseudo-PE: 수도 사후교정 문장, Mean/Median/STD/Variance: 평균/중앙값/표준편차/분산, TER(Translation Edit Rate): 편집 거리(edit distance) 기반 스코어, Source OK/BAD tags: 소스 문장 중 OK/BAD 태그 개수, MT Output OK/BAD tags: 번역 문장 중 OK/BAD 태그 개수
- 학습 데이터 TER(번역 편집 거리) 분포
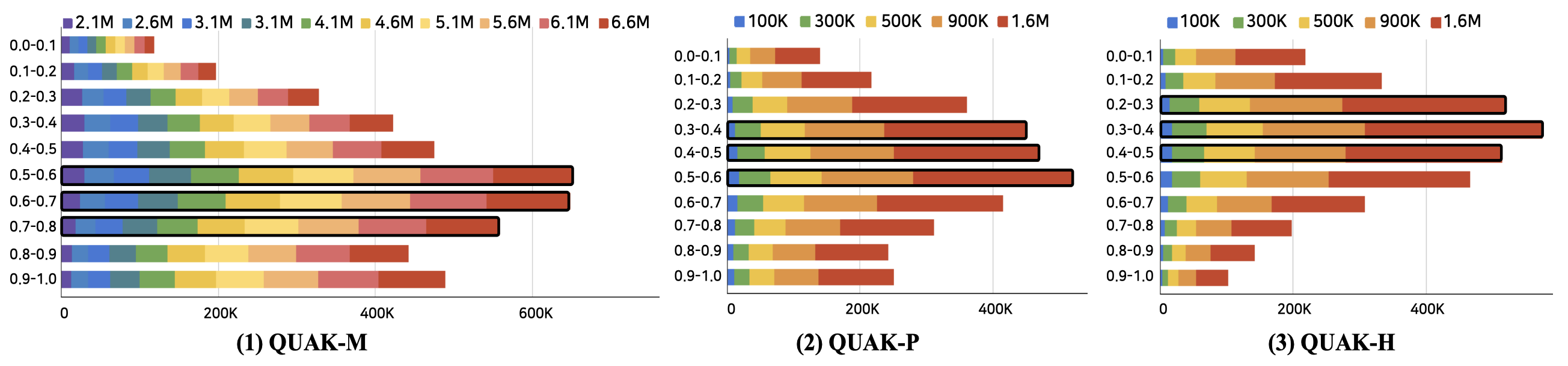
- 학습 데이터 분포
Train QUAK-M QUAK-P QUAK-H # Sentences Source 6,578,002 1,578,002 1,578,002 MT Output 6,578,002 1,578,002 1,578,002 PE 6,578,002 1,578,002 1,578,002 # Tokens Source 92,848,776 25,149,673 25,149,673 MT Output 139,620,328 42,051,001 39,850,492 PE 148,922,086 42,103,966 42,103,966 Average Token Per Sentence Source 14.12 15.94 15.94 MT Output 21.23 26.65 25.25 PE 22.64 26.68 26.68 TER Mean 0.61 0.5 0.42 Median 0.63 0.5 0.4 STD 0.24 0.25 0.23 Variance 0.06 0.06 0.05 Word-level #Source OK tags 50,421,860 15,600,416 16,269,784 #Source BAD tags 42,426,916 9,549,257 8,879,889 #MT Output OK tags 204,721,896 65,852,185 65,033,087 #MT Output BAD tags 81,096,762 19,827,819 16,245,899 - 검증 데이터 분포
Valid QUAK-M QUAK-P QUAK-H # Sentences Source 12,000 12,000 12,000 MT Output 12,000 12,000 12,000 PE 12,000 12,000 12,000 # Tokens Source 209,894 199,624 199,624 MT Output 318,959 340,855 318,921 PE 342,021 341,996 341,996 Average Token Per Sentence Source 17.5 16.64 16.64 MT Output 26.58 28.4 26.58 PE 28.5 28.5 28.5 TER Mean 0.45 0.57 0.45 Median 0.44 0.56 0.44 STD 0.21 0.23 0.21 Variance 0.04 0.05 0.04 Word-level #Source OK tags 84,873 113,192 121,700 #Source BAD tags 82,343 86,432 77,924 #MT Output OK tags 339,304 511,542 506,437 #MT Output BAD tags 157,308 182,168 143,405 - 평가 데이터 분포
Test Google Amazon MS Systran # Sentences Source 12,000 12,000 12,000 12,000 MT Output 12,000 12,000 12,000 12,000 PE 12,000 12,000 12,000 12,000 # Tokens Source 199,413 199,413 199,413 199,413 MT Output 340,264 303,535 325,973 346,030 PE 342,385 342,385 342,385 342,385 Average Token Per Sentence Source 16.62 16.62 16.62 16.62 MT Output 28.36 25.29 27.16 28.84 PE 28.53 28.53 28.53 28.53 TER Mean 0.57 0.63 0.63 0.46 Median 0.57 0.64 0.64 0.44 STD 0.23 0.21 0.21 0.26 Variance 0.05 0.04 0.05 0.07 Word-level #Source OK tags 112,647 94,562 97,825 134,503 #Source BAD tags 86,766 104,851 101,588 64,910 #MT Output OK tags 510,085 429,775 465,441 560,221 #MT Output BAD tags 182,443 189,295 198,505 143,839 -
[소개]
1. 태스크 설명 및 필요성
기계번역 서비스를 활용하는 사용자들은 정답 문장 없이 소스 문장을 번역하며, 번역하는 언어에 대해 모국어처럼 구사하지 못하기 때문에 번역 결과를 얼마나 신뢰해도 되는지, 번역 결과 중 잘못된 부분은 없는지를 알 수가 없음. 이에 등장한 것이 기계번역 품질 예측 태스크임. 기계번역 품질 예측이란 정답 문장 없이도 소스 문장과 번역 결과만을 참조하여 번역 결과에 대한 품질을 나타내는 기계번역 분야 하위 태스크임. 기계번역 품질 예측 모델은 소스 문장과 번역 문장을 입력으로 받아 각 문장에 대한 어절별 OK/BAD 태그를 결과로 출력함. 이를 통해 사용자들은 번역 결과 중 선택적으로 틀린 부분만을 수정하거나 옳은 부분만을 받아들일 수 있으며, 여러 번역 결과 중 가장 좋은 번역 결과를 선택할 수 있다는 장점이 있음
2. 데이터 및 제작 방법 소개
이러한 기계번역 품질 예측 모델을 학습하기 위해서는 데이터가 필요함. 따라서 사전에 구축된 AI-HUB의 한국어-영어 번역(병렬) 말뭉치 및 Wikipeida 코퍼스를 활용해 완전 자동화된 방식으로 기계번역 품질 예측 데이터셋을 재구성함
학습데이터는 활용하는 원시 데이터에 따라 QUAK-M(Monolingual), P(Parallel), H(Hybrid)의 세 가지로 나뉨. M의 경우 모노 코퍼스를 활용하며, P는 병렬 코퍼스, H는 M과 P의 하이브리드 버전임
학습데이터 중 QUAK-M의 경우 모노 코퍼스(1.58M: 병렬 코퍼스 중 타겟 문장, 6.58M: Wikipedia 문장)에 대해 Transformer 모델을 활용해 round-trip translation을 수행한 후, 번역 결과와 수도 사후교정 문장(모노 코퍼스) 간 토큰별 edit distance를 측정 및 word alignment 정보를 바탕으로 소스 문장 및 번역 문장에 어절별 번역 품질을 OK/BAD 태그하여 데이터를 생성함
QUAK-P의 경우 AI HUB 병렬 코퍼스 중 수도 사후교정 문장(타겟 문장)에 대해 backward translation을 수행한 후, 번역 결과와 타겟 문장 간 토큰 별 edit distance를 측정 및 word alignment 정보를 바탕으로 소스 문장 및 번역 문장에 어절별 번역 품질을 OK/BAD 태그하여 데이터를 생성함
QUAK-H의 경우 주어진 한정된 데이터 내 번역 결과의 다양성(diversity)을 고려하기 위해 소스 측은 QUAK-P로부터, 번역 결과 측은 QUAK-P로부터 문장을 가져와 edit distance 측정 및 word alignment 정보를 바탕으로 소스 문장 및 번역문장에 어절별 번역 품질을 OK/BAD 태그하여 데이터를 생성함
테스트 데이터의 경우 AI HUB 병렬 코퍼스 중 소스 문장에 대해 각 기계번역기로 번역한 결과와 타겟 문장 간 edit distance를 활용해 레이블링을 수행함. 따라서 번역기별 기계번역 품질 예측 성능을 보는 것과 동시에 네 가지 기계번역기에 대한 성능을 비교함으로써 특정 번역기에 편향된(biased) 품질을 예측하는지도 판단할 수 있음
3. 데이터를 활용한 학습 방법 소개
소스 문장과 번역 문장을 사전 학습된 다국어 언어모델의 입력으로 구성하고 각 문장들에 대한 OK/BAD 태그들을 출력하도록 모델을 학습함. 기계번역 품질 예측 모델의 평가는 Matthews correlation coefficient (MCC)로 측정하며, f1 score도 함께 평가 지표로 제시됨
[데이터셋 구성]
1. 대표도면
- [데이터 이름].mt: 번역 문장
- [데이터 이름].pe: 수도 사후교정 문장 (옳은 번역 문장)
- [데이터 이름].tags: 번역 문장의 어절별 OK/BAD 태그
- [데이터 이름].src: 소스 문장
- [데이터 이름].source_tags: 소스 문장의 어절별 OK/BAD 태그
- [데이터 이름].src-mt.alignments: 소스 문장 및 번역 문장 간 단어 얼라인 정보
- [데이터 이름].hter: 편집 거리 기반 TER 스코어2. 라벨링데이터 구성
- 1.대표도면 중 다음은 라벨링 데이터임
- 소스 문장 품질 라벨링 데이터: [데이터 이름].source_tags
- 번역 문장 품질 라벨링 데이터: [데이터 이름].tags3 라벨링데이터 실제예시
* 표설명
- MT Output: 번역 결과, pseudo-PE: 사후 교정문장, MT Output tags: 번역 결과 OK/BAD 태그,
Source: 소스 문장, Source tags: 소스 문장 OK/BAD 태그, Alignments: 소스 문장-번역 결과 간 단어 얼라인 정보, Edits: MT Output과 pseudo-PE 간 편집 거리
* 여기서 MT Output tags의 개수는 2x(MT Output 토큰 개수)+1임. MT Output 토큰 앞뒤로 Gap 태그라는 것을 두는데, 번역 문장과 사후교정 문장 비교 시 빠진 토큰(missing token)이 있는 경우 해당하는 Gap 태그의 위치에 OK/BAD 태그를 수행함
-
데이터셋 구축 담당자
수행기관(주관) : 고려대학교 산학협력단
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 어수경 02-3290-2684 djtnrud@korea.ac.kr 자연어데이터 생성/검수, 자연어처리 모델링 데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 고려대학교 자연어처리 연구실 02-3290-2684 djtnrud@korea.ac.kr
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 safezone1@aihub.kr 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.