-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.1 2023-12-13 데이터 최종 개방 1.0 2023-06-07 데이터 개방(Beta Version) 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2023-12-27 산출물 전체 공개 소개
음성인식 성능개선을 위해 다양한 극한 소음환경에서 발성된 음성데이터를 수집/정제/가공하여 인공지능(AI) 학습용 데이터셋 구축
구축목적
음성인식기 성능 저하의 가장 큰 요인인 극한 소음 환경에서 소음을 제거하는 학습 방법을 적용하여 극한 소음 환경에서도 강인한 음성 인식 성능이 나오도록 연구 개발을 목적으로 함
-
메타데이터 구조표 데이터 영역 한국어 데이터 유형 오디오 데이터 형식 wav 데이터 출처 자체 수집 라벨링 유형 전사(음성) 라벨링 형식 json 데이터 활용 서비스 AI 스피커 등 음성인식 서비스 데이터 구축년도/
데이터 구축량2022년/극한 소음 음성 데이터 2,000시간 -
ㅇ 데이터 구축 규모
- 극한 소음 환경 클래스 분류소음분류 소분류 세부내용 (예시) 1.교통수단 지상운송수단 자동차 경기장, 고속도로(졸음쉼터), 터널, 대형트럭 철로운송수단 열차가 통과하는 선로, 육교근처소음, 플랫폼 기차 통과 소리, 철길 건널목 항공운송수단 항공기, 경비행기, 헬리콥터 이착륙 소음, 내부소음 수상운송수단 수상택시, 모터 보트소음 2.공사장 경장비소음 공사장의 기계음 소리들(그라인더, 기계톱, 절단기, 전동해머드릴) 중장비소음 공사장의 중장비 소리들(굴삭기, 착암기, 천공기, 항타기(충격음발생기계)) 3.공장 공장기계음 공장 기계에서 발생하는 소리(제철소, 자동차공장, 방직공장, 목재소, (전기톱, 프레스 등)) 4.시설류 실내시설 게임장(오락실), 공연장(오케스트라, 국악, 콘서트), 실내 서핑장, 실내 사격장, 실내 경기장 실외시설 실외 경기장(야구, 축구, 경마, 경륜 등), 폐차장, 놀이시설, 행사장 등 5.기타 실내기타소음 기계실(서버실 등), 펌프실, 공조시설, 자동차 검사소 등 실외기타소음 여름철 매미소리, 산업용 진공 기계 소리, 싸이렌 소리, 농기계 (예초기, 트랙터, 경운기), 무선 모형 엔진 소리, 드론, 천연폭포, 빗소리 등 6.복합소음 2가지이상소음 공장소리+빗소리, 자동차 소리+싸이렌 소리 등 - 구축 규모
소음 환경 구축 시간 1. 교통수단 512.9 2. 공사장 423.3 3. 공장 512.9 4. 시설류 325.2 5. 기타 140.5 6. 복합소음 168.1 합계 2,082.9 ㅇ 데이터 분포
- 극한 소음 환경 분포소음 환경 시간 구성비 1. 교통수단 512.9 24.6% 2. 공사장 423.3 20.3% 3. 공장 512.9 24.6% 4. 시설류 325.2 15.6% 5. 기타 140.5 6.7% 6. 복합소음 168.1 8.1% 합계 2082.9 100.0% 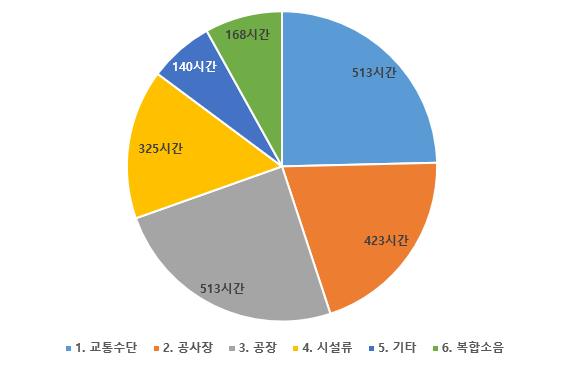
- 대화 주제 분포
대화 주제 시간 구성비 1. 개인 및 관계 349.2 16.8% 2. 주거와 생활 304.1 14.6% 3. 상거래쇼핑 235.1 11.3% 4. 식음료 280.9 13.5% 5. 공공서비스 155.9 7.5% 6. 여기와 오락 314.0 15.1% 7. 일과 직업 273.0 13.1% 8. 행사 및 모임 170.6 8.2% 합계 2,082.9 100.0% - 화자 성별 분포
성 별 건(수) 구성비 남성 23,062.0 45.6% 여성 27,550.0 54.4% 합계 50,612.0 100.0% - 화자 연령대 분포
성 별 건(수) 구성비 20대 12,386.0 24.5% 30대 12,858.0 25.4% 40대 11,816.0 23.3% 50대 13,552.0 26.8% 합계 50,612.0 100.0% - 소음원 거리 분포
거리 건(수) 구성비 근거리 23,470.0 92.7% 원거리 1,836.0 7.3% 합계 25,306.0 100.0% - 화자 발성 정도 분포
화자 발성 건(수) 구성비 고음 5,585.0 22.1% 중간음 13,584.0 53.7% 저음 6,137.0 24.3% 합계 25,306.0 100.0% - 녹음 환경 분포
녹음 환경 건(수) 구성비 스튜디오 7,534.0 29.8% 현장 17,772.0 70.2% 합계 25,306.0 100.0% - 화자별 발화 시간 분포
발화 시간 화자수 구성비 500분 이상 72.0 16.4% 100분 이상 ~ 500분 미만 119.0 27.2% 50분이상 ~ 100분 미만 71.0 16.2% 10분 이상 ~ 50분 미만 118.0 26.9% 10분 미만 58.0 13.2% 합계 438.0 100.0% -
-
AI 모델 상세 설명서 다운로드
AI 모델 상세 설명서 다운로드 AI 모델 다운로드ㅇ 학습모델
- TSCN : 딥러닝 기반 소음 제거 모델(Deep Noise Suppression)로 ICASSP 2021 DNS Challenge의 트랙1(실시간 소음감소)에서 1위를 차지한 모델로 최근 DNS 모델과 비교해서 가장 높은 성능 결과를 나타냄
→ 
→ CME-Net → CSR-Net → 
음성+소음 입력 Spectrogram 음성(소음감소) TSCN 모델 - CME-Net은 노이즈가 많은 스펙트럼의 크기를 입력으로, 깨끗한 음성 스펙트럼의 크기를 출력으로 사용하여 복잡한 스펙트럼을 얻기 위해 노이즈가 많은 위상을 추가로 결합함
- CSR-Net에서는 CSS와 원래 노이즈 스펙트럼을 모두 입력으로 받아 잔류 스펙트럼을 추정하는 방식으로, 즉 CME-Net은 스펙트럼의 크기를 최적화하고, CSR-Net은 위상을 수정 및 크기를 세분화 함ㅇ 데이터 셋 분할
구분 학습(Training) 검증(Validation) 테스트(Test) 계 소음+음성데이터 80% 10% 10% 100% 음성 데이터 ㅇ 활용서비스
- 인공지능 스피커, 음성 명령어 인식기, 음성 기반 안전 감시 시스템 등 다양한 음성인식 분야에서 소음으로 인한 간섭이 발생할 경우, 음성인식 엔진의 전처리로서 DNS를 활용하여 깨끗한 음성을 남기로 음성인식에 전달하기 위한 서비스
- 예시
· 도시 소음 등 시끄러운 환경에서 음성인식 키오스크의 인식률 향상
· 추가적인 학습을 위해서는 소음+음성(Noisy data)과 음성(Clean data)이 세트로 이루어진 데이터 셋을 구축하여, 응용 서비스에 특화된 소음을 따로 훈련할 수 있음
- 유의사항
· 현재 개발된 모델은 30초 단위의 16Khz 샘플링을 입력으로 사용하고, 출력 데이터 역시 30초 16Khz를 기본형식으로 하고 있음. 긴 음성의 경우 resampling 및 30초 단위의 절단 및 병합 과정이 필요함 -
데이터 성능 점수
측정값 (%)기준값 (%)데이터 성능 지표
데이터 성능 지표 번호 측정항목 AI TASK 학습모델 지표명 기준값 점수 측정값 점수 1 음성의 명료도 (76dB~85dB) Speech Recognition TSCN, ESPNet ESTOI 0.6 % 85 % 2 음성의 명료도 (86dB~95dB) Speech Recognition TSCN, ESPNet ESTOI 0.5 % 85 % 3 음성의 명료도 (96dB 이상) Speech Recognition TSCN, ESPNet ESTOI 0.4 % 86 % 4 음성인식 성능 향상도 (76dB~85dB) Speech Recognition TSCN, ESPNet F1-Score 0.15 점 0.24 점 5 음성인식 성능 향상도 (86dB~95dB) Speech Recognition TSCN, ESPNet F1-Score 0.1 점 0.19 점 6 음성인식 성능 향상도 (96dB 이상) Speech Recognition TSCN, ESPNet F1-Score 0.05 점 0.15 점 7 소리 분류 정확도 (76dB~85dB) Audio Classification ESResNet F1-Score 0.8 점 0.89 점 8 소리 분류 정확도 (86dB~95dB) Audio Classification ESResNet F1-Score 0.75 점 0.84 점 9 소리 분류 정확도 (96dB 이상) Audio Classification ESResNet F1-Score 0.7 점 0.83 점
※ 데이터 성능 지표가 여러 개일 경우 각 항목을 클릭하면 해당 지표의 값이 그래프에 표기됩니다.
※ AI모델 평가 지표에 따라 측정값의 범위, 판단 기준이 달라질 수 있습니다. (ex. 오류율의 경우, 낮을수록 좋은 성능을 내는 것으로 평가됩니다)
-
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드ㅇ 데이터 소개
- 음성인식기 성능 저하의 가장 큰 요인인 소음환경 중에서 보다 나은 인식 성능 개선을 위해 다양한 극한 소음 환경(예 : 비행기소리, 공장, 자동차 경주장, 공연장 등)에서 발성된 음성 데이터 구축
- 주변 소음이 자연스럽게 포함된 음성 데이터 및 해당 음성을 전사한 데이터 구축
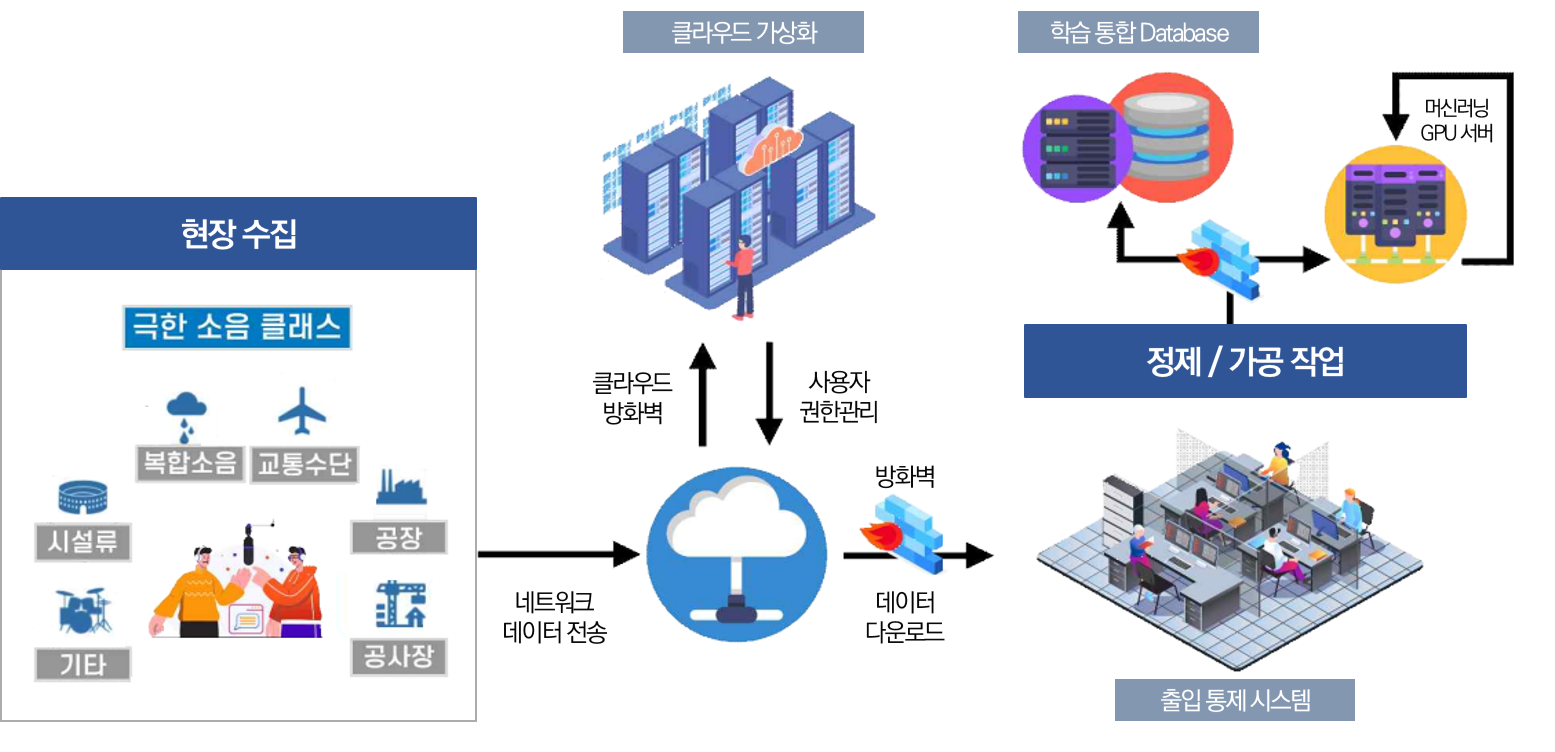
ㅇ 데이터셋 구성
파일 종류 파일 설명 비고 *_VN.wav 음성이 크고 소음이 작은 파일 원천데이터 *_NV.wav 소음이 크고 음성이 작은 파일 *.json 속성(메타)정보 파일 라벨링데이터 *.srt 전사 텍스트 파일 ㅇ 어노테이션 포맷
- 음성위주의 녹음파일, 음성+극한 소음의 녹음파일 모두 아래와 같은 어노테이션 포맷을 생성하며 메타항목은 전부 필수임No 항목 설명 필수여부 타입 0 dataSet 데이터셋 Y String 1 version 데이터셋 버전 Y String 2 mediaUrl 녹취된 음원의 URL Y String 3 date 녹취된 날짜 Y String 4 noiseInfo 소음원데이터 상세 정보 Y Array 4-1 category 소음원 카테고리 정보(교통수단, 공사장, 공장 등) Y String 4-2 subCategory 소음원 서브카테고리(지상운송, 철로운송, 항공운송 등) Y String 4-3 noisePlace 소음원 획득 장소 (녹취 세부 내용) Y String 4-4 bgnoisespl 구간내 소음원 최대 dB Y String 4-5 distance 소음발생원과의 평균거리(근거리/원거리) Y String 5 conversationType 화자 대화유형(개인 및 관계, 주거와 생활, 식음료 등) Y String 6 speakerNumber 화자수(예: 2명) Y String 7 speakerPlace 화자녹취장소 (현장/스튜디오) Y String 8 speakers 화자(목록:화자A, 화자B) Y Array 8-1 speaker 화자 아이디 : speakers에 등록된 순번 Y String 8-2 gender 화자(성별 : 남성, 여성) Y String 8-3 ageGroup 화자(연령대 : 20대,30대,40대,50대) Y String 9 dialogs 전사 데이터 목록 (화자 대화 목록) Y Array 9-1 speaker 화자 아이디 : speakers에 등록된 순번 Y String 9-2 speakerText 전사된 텍스트 Y String 9-3 startTime 전사된 텍스트의 음원 재생 시작 위치 Y Number 9-4 endTime 전사된 텍스트의 음원 재생 끝 위치 Y Number 9-5 speakTime 화자의 발성시간 (sec) Y Number 9-6 vocalVolume 화자의 발성정도(저음/중간음/고음) Y String 10 audioResolution 오디오 레졸류션 Y Array 10-1 bitDepth 비트뎁스 (16bit) Y Number 10-2 sampleRate 샘플레이트 (44.1kHz) Y Number 11 recStime 녹취시작시간(01~24) Y String 12 recLen 녹취시간(화자의전체대화시간) Y Number 13 recDevice 녹취장비구분((6ch Zoom h6 audio recorder / 4ch Tascam DR-40x / 스마트폰) Y String ㅇ 라벨링데이터 실제 예시
{
"dataSet":"극한소음음성",
"version":"1.0",
"mediaUrl":"01.교통수단/02.철로운송수단/01_01_103203_220823_0005_VN.wav",
"date":"20220823",
"noiseInfo":{
"category":"교통수단",
"subCategory":"철로운송수단",
"noisePlace":"안양역 근처 철교",
"bgnoisespl":"91.5",
"distance":"근거리"
},
"conversationType":"개인및관계",
"speakerNumber":"2",
"speakerPlace":"현장",
"speakers":[
{
"speaker":"103",
"gender":"여성",
"ageGroup":"40"
},
{
"speaker":"203",
"gender":"남성",
"ageGroup":"40"
}
],
"dialogs":[
{
"speaker":"103",
"speakerText":"오늘 날씨도 만만치 않네. 시원하게 냉물로 샤워를 하거나 시원한 얼음물로 등목해야 하는 날씨야. 밖에 나오기조차 싫은 그런 너무 더운 날이야.",
"startTime":2,
"endTime":15.999,
"speakTime":13.999,
"vocalVolume":"고음"
},
{
"speaker":"203",
"speakerText":"난 이렇게 더운 날이면 몸이 진이 다 빠지더라. 근데 나와 다르게 너는 왜 이렇게 아무렇지 않아 보이네. 너는 괜찮아?",
"startTime":16.001,
"endTime":29.999,
"speakTime":13.998,
"vocalVolume":"고음"
},
- 중 략 -
],
"audioResolution":{
"bitDepth":16,
"sampleRate":44.1
},
"recStime":"14",
"recLen":316,
"recDevice":"6ch Zoom h6 audio recorder"
}
-
데이터셋 구축 담당자
수행기관(주관) : ㈜코테크시스템
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 김연봉 02-2253-7355 batnaic@kotech.co.kr 품질책임자 수행기관(참여)
수행기관(참여) 기관명 담당업무 ㈜단솔플러스 기술자문 ㈜인사이트정보 데이터 수집, 검수 ㈜코리아퍼스텍 데이터 정제, 가공, 검수 데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 김연봉 02-2253-7355 batnaic@kotech.co.kr
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 safezone1@aihub.kr 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.