-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.1 2023-12-22 데이터 최종 개방 1.0 2023-06-14 데이터 개방 (Beta Version) 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2023-11-15 산출물 전체 공개 소개
- 방송 콘텐츠 분야의 유럽어 통·번역 성능 향상을 통해 한국 문화 확산 및 콘텐츠 산업 활성화를 위한 한국어 방송 콘텐츠의 인공지능 학습용 유럽어 통·번역 말뭉치 데이터 - 상황별 신조어, 약어, 은어, 관용적 의미와 어투까지 효과적으로 전달할 수 있는 인공신경망기계번역(Neural Machine Translation; NMT)용 한-유럽어 통·번역 음성 및 텍스트 pair 데이터
구축목적
ㅇ 분야 특화 번역모델을 이용한 번역서비스 제공 - 전문 번역사 중심의 번역공정으로는 지속적으로 늘어나게 될 K-콘텐츠의 수출을 지원하기에는 어려움이 있고, 문화적/언어적 특성을 잘 처리할 수 있는 특화 번역모델 기술의 개발로 품질이 우수하고 신속한 번역 서비스의 제공이 가능 ㅇ 범용성 높은 인공지능 데이터 구축 및 공개 - 활용성 높은 분야를 선정하고 원본 데이터 확보 가능성 확인 - 인공지능 학습에 적합한 콘텐츠(문장) 선정 - 정확도 높은 학습 데이터 구축 ㅇ 고품질 인공지능 학습 데이터 확보 - 고품질 학습용 한국어 유럽어 양방향 데이터 구축 - 분야 특화가 가능한 번역모델 학습 데이터 구축 ㅇ 인공지능 데이터를 통한 일자리 창출 및 기술 향상 기여 - 크라우드소싱으로 작업 - 공개 데이터를 활용한 다국어 인공지능 번역의 성능 향상 - 활용 사례 및 수정/구축 결과 공유
-
메타데이터 구조표 데이터 영역 한국어 데이터 유형 오디오 , 텍스트 데이터 형식 wav 데이터 출처 방송사와 저작권 계약을 통해 콘텐츠 수집 라벨링 유형 번역(자연어), 전사(음성), 발화(음성) 라벨링 형식 wav, json 데이터 활용 서비스 다국어 통역기, 다국어 영상 자막 자동 생성 서비스 데이터 구축년도/
데이터 구축량2022년/1)원천데이터 - 방송콘텐츠 600시간에 대한 한국어 원천 데이터 495,152개(WAV, 68.72GB) 2)라벨링데이터 - 방송콘텐츠 600시간에 대한 음성전사 데이터 495,152개(JSON, 0.36GB) - 한국어-독일어/프랑스어/이태리어 통번역 데이터 1,671,131개(JSON, 1.59GB) - 한국어-독일어/프랑스어/이태리어 원어민 발화 데이터 1,687,263개(WAV, 267.51GB) -
1. 데이터 구축 규모
(1-010-033) 방송컨텐츠 한국어-유럽어 통번역 음성 데이터
방송콘텐츠 약 600시간에 대한 원천 데이터 약 50만개 및 라벨링테이터 약 380만개구분 종류 형태 포맷 언어 규모 원천 데이터 방송콘텐츠 오디오 wav 한국어 600시간에 대한 음성 데이터 495,152개 음성전사 데이터 텍스트 json 한국어 600시간에 대한 음성전사 데이터 495,152개 통번역 데이터 텍스트 json 한국어-독일어/프랑스어/이탈리아아어 600시간에 대한 통번역 데이터 1,671,131개 발화음성 데이터 오디오 wav 독일어/프랑스어/이탈리아어 600시간에 대한 원어민 발화 데이터 1,687,263개 2. 데이터 분포
- 방송콘텐츠 대분류 5개 이상으로 데이터 편향 없이 균등하게 설계 구축
- 다양한 화자, 발화 스타일, 다양한 주제, 분야가 반영될 수 있는 카테고리 등 데이터 전체 구성 방안 및 균형적인 분포(1-010-033) 방송콘텐츠 한국어-유럽어 통번역 음성 데이터
분류 언어 음성시간 다큐 한국어- 120시간(20%) 교양 독일어/프랑스어/이태리어 120시간(20%) 연예, 공연 (각 600시간) 120시간(20%) 영화, 드라마 30시간(5%) 오락, 예능 120시간(20%) 인터뷰 90시간(15%) 합계 600시간 대분류 중분류 소분류 음성시간 다큐 KBS, MBN 다큐온, 다큐세상, 자연의 철학자들, 사노라면등 120 (20%) 교양 KBS, MBN, CJENM VJ 특공대, 역사스페셜, 알약방, 생생정보마당, 논문 읽어드립니다, 역사 읽어드립니다 등 120 (20%) 연예/공연 KBS, MBN, CJENM 연예가중계, 안녕하세요, 황금알, 비포썸라이즈, 모모문고, 아큐멘터리, 아이돌 취향일기 등 120 (20%) 드라마/영화 CJENM, TVN, SHOWBOX, KPSFF Sometoon, 당신의 상상은 현실이 된다, 시그널, 또 오해영, 도둑들, 내부자들, 장애인영화제 등 30 (5%) 예능/오락 MBN, CJENM 알토란, 계자이너kkye, 코덕들의 파우치 소개서, 2 FACE 데이트 2, 걸리버여행기 등 120 (20%) 인터뷰 KBS, MBN 화요초대석, 집중인터뷰 이사람, 토요포커스등 90 (15%) -
-
AI 모델 상세 설명서 다운로드
AI 모델 상세 설명서 다운로드 AI 모델 다운로드1. 학습 AI모델
1) 음성전사 데이터의 평가로 CER 측정 활용
- 구축한 데이터의 유효성을 검증하기 위하여 가공이 완료된 본 데이터를 인공지능 학습 모델을 통해 검증
- 한국어 방송 콘텐츠 음성데이터는 발화데이터와 그 발화에 해당하는 전사 데이터로 가공되며 이는 한국어 음성인식을 위한 데이터로 활용될 수 있음
- 음성인식 유효성 검증은 최근 성능이 우수한 CTC와 transformer를 결합한 음성인식 알고리즘을 사용하였으며, 음성인식 품질 평가방법은 공인된 CER 기법을 사용하여 평가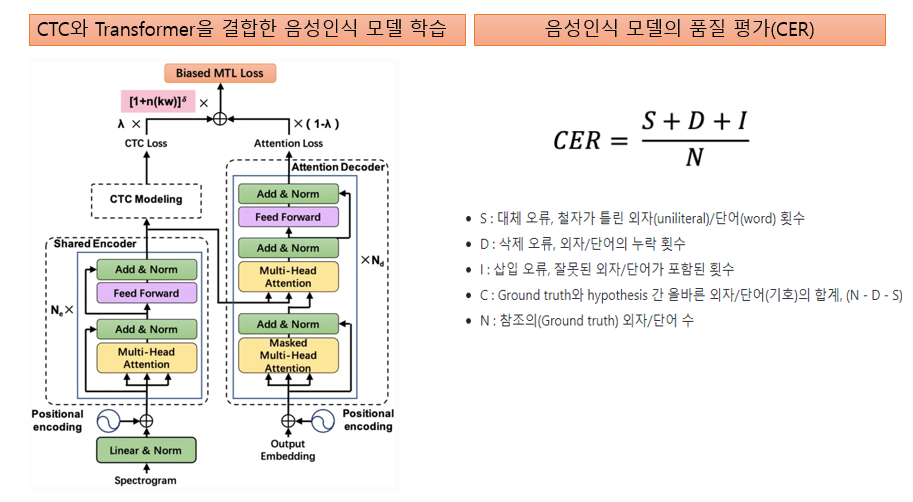
- 학습 모델에 사용된 데이터는 한국어 방송 콘텐츠 950시간 정도이며, 이는 세그먼트된 발화 음성 파일 기준으로 대략 937,500개 정도임
- 학습된 음성인식 모델로 실험한 결과 CER 기준 10.0이라는 객관적이고 정량적인 성능 수치가 나왔으며, 이는 사업 초기 계획했던 CER 15를 훨씬 초과하는 좋은 성능 결과를 얻음
- 이로써, 본 과제에서 가공된 한국어 방송 콘텐츠 음성 데이터는 그 품질이 우수함을 음성인식 유효성 검증을 통해 입증함
2) 특화 번역모델의 번역품질 평가 방안으로 BLEU 평가 활용
- 다국어로 번역하여 구축한 통번역 데이터의 유효성 검증을 입증하기 위해 Attention 기반의 Transformer 알고리즘을 통해 번역 모델을 구성
- 학습된 번역 모델로 실제 구축한 데이터를 검증하기 위해 BLEU라고 하는 범용적인 자동 평가 도구를 사용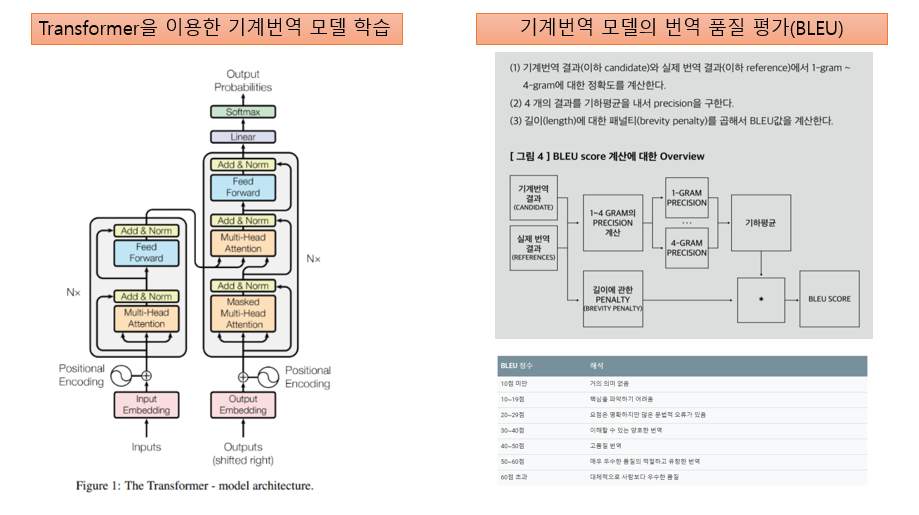
- 모델 구축은 언어별로 진행하였으며, 그 중 한영 병렬 말뭉치가 가장 많은 63만 문장쌍이며, 가장 적은 언어는 한불 47만 문장쌍임
- 언어별 학습을 통해 BLEU를 평가한 결과 한영 번역 모델이 가장 높은 50.27로 나왔고 가장 낮은 언어셋은 한러 38.41로 나옴
- 이러한 결과는 사업 제안서에서 제시한 BLEU 평가 점수 38을 모두 넘는 수치로 이는 구축한 다국어 번역 말뭉치 데이터 역시 그 품질이 우수함을 입증함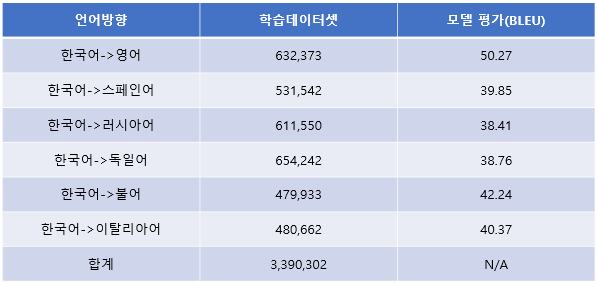
2. 데이터 활용
활용 분야 및 요구사항
- 연구분야: 구어체 텍스트 데이터를 활용하는 한국어-영어/유럽어 인공지능 번역 연구
- 산업분야: 구어체 방송콘텐츠 한국어-영어/유럽어 자막 및 번역 생성 서비스1. 데이터 활용
데이터명 AI 모델 모델 성능 지표 응용서비스(예시) 1-010-033 방송콘텐츠 한국어-유럽어 통번역 음성 데이터 방송콘텐츠 분야 한-유럽어 음성인식 모델 CER 15% 이하 방송콘텐츠 한-유럽어 AI 자막화 서비스 1-010-033 방송콘텐츠 한국어-유럽어 통번역 음성 데이터 방송콘텐츠 분야 한-유럽어 자막번역 모델 STT: CER < 15% 방송콘텐츠 한-유럽어 AI 자막 번역 서비스 BLEU 40점 이상 1-010-033 방송콘텐츠 한국어-유럽어 통번역 음성 데이터 방송콘텐츠 분야 한-유럽어 통번역 모델 STT: CER < 15% 방송콘텐츠 한-유럽어 AI 통역 서비스 BLEU 40점 이상 TTS Good > 60% 2. 응용 서비스
한국문화 특화 번역 모델로 K-콘텐츠 글로벌화를 위한 세종학당, 해외문화원 등을 통하여 K-콘텐츠 클라우드 번역 서비스
3. 응용서비스 개발
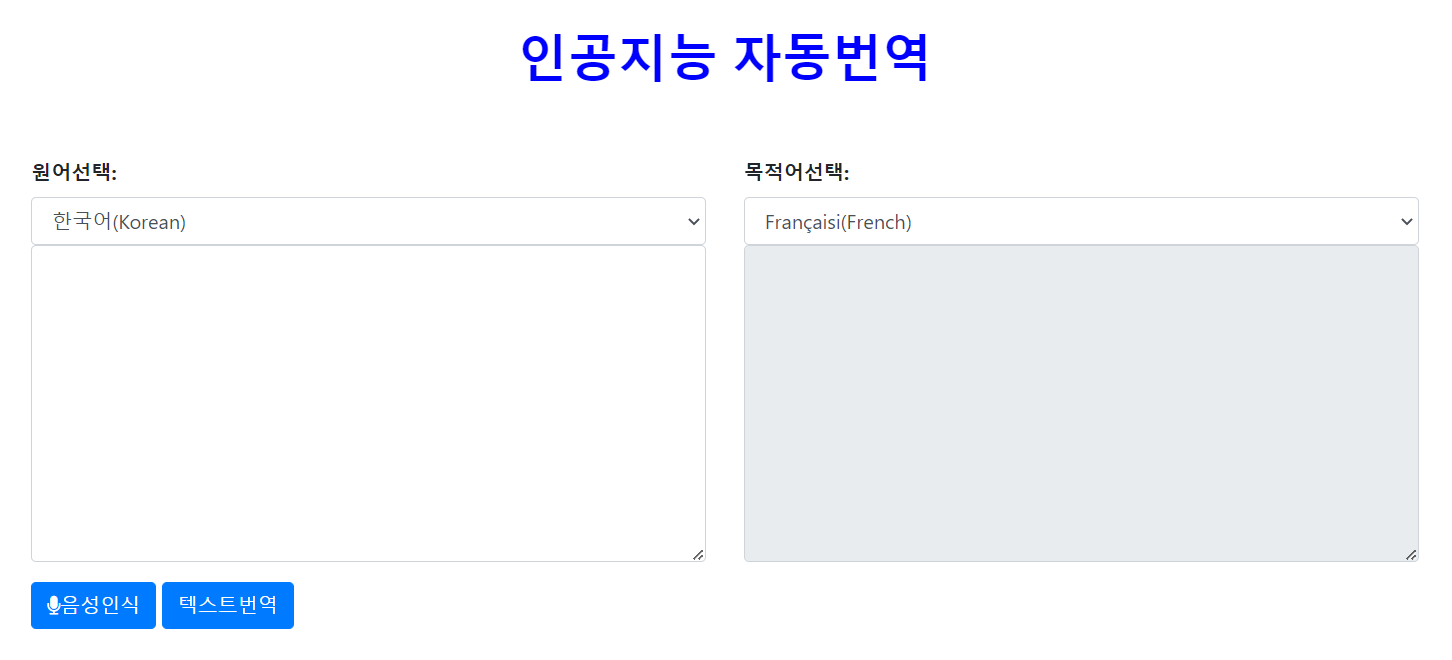
ㅇ다국어 통역기
- 한국어 음성을 인식해서 다국어로 통번역하는 웹서비스
- 인공지능 음성인식과 자동번역 학습모델을 활용하여 개발
- 도메인 특화 성능 고도화를 통해 고객 맞춤형 통번역 서비스 제공 가능
ㅇ다국어 영상 자막 자동 생성 서비스
- 방송 및 유튜브 영상의 한국어 음성을 자동 인식
- 한국어 텍스트를 사용자가 선택한 다국어로 번역하여 자막을 자동으로 생성
- 정확도가 높을 경우 1시간 영상 기준으로 기존 자막화 시간 29시간에서 10분 이내로 단축할 수 있는 효율적인 서비스임
- 자막은 “srt” 또는 “vtt”형태로 다운로드 가능
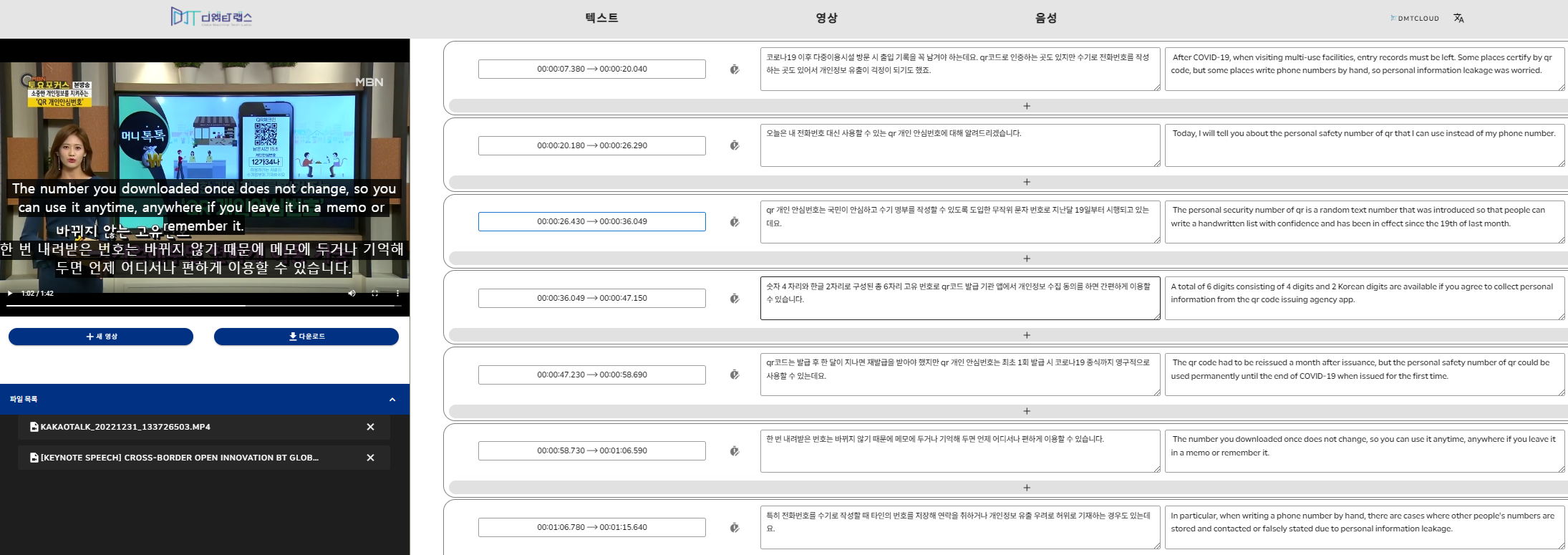
- 영상 음성에 대한 인식 결과 또는 자동번역 오류가 있을 경우 이를 수정할 수 있는 편집 기능도 함께 제공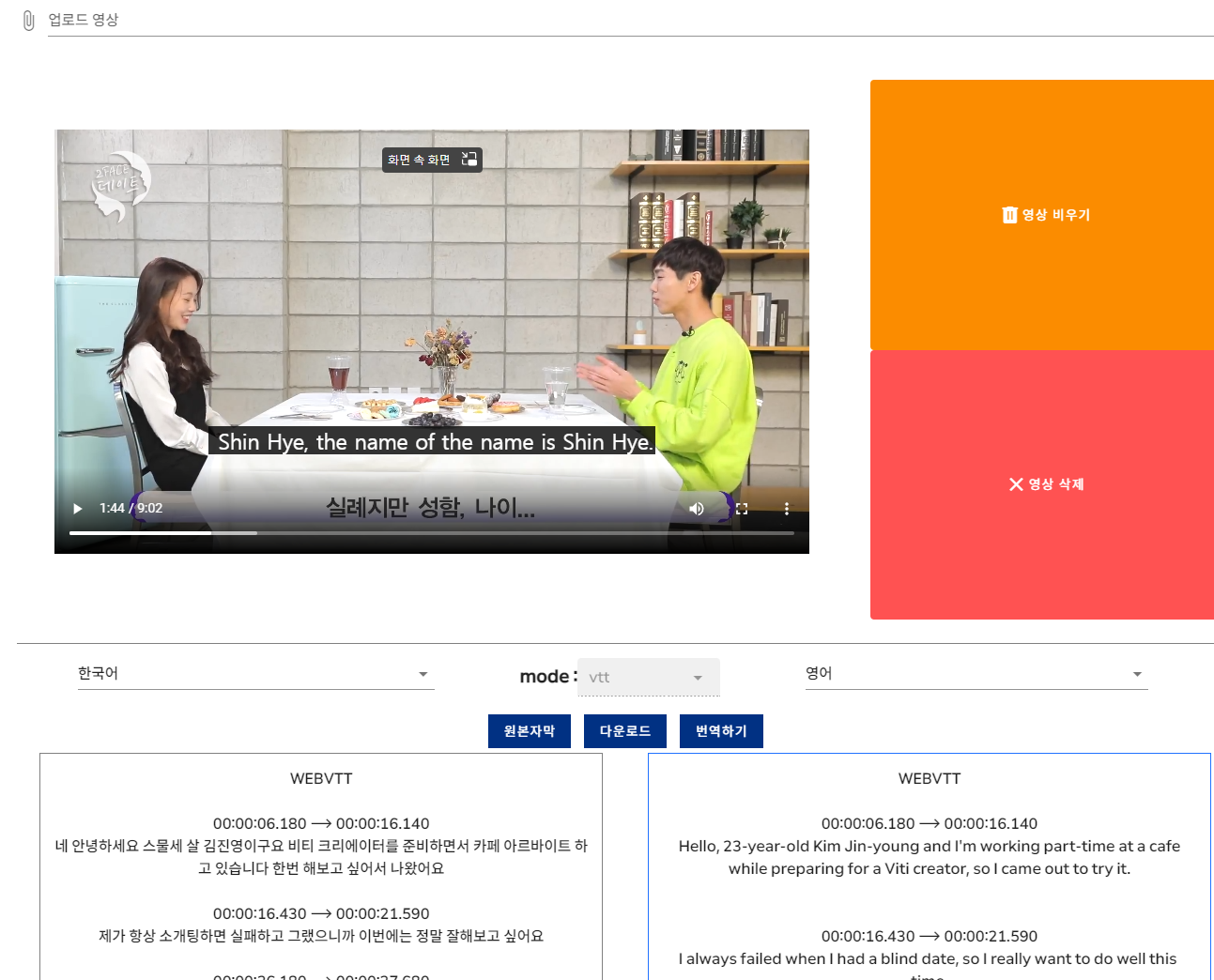
-
데이터 성능 점수
측정값 (%)기준값 (%)데이터 성능 지표
데이터 성능 지표 번호 측정항목 AI TASK 학습모델 지표명 기준값 점수 측정값 점수 1 방송콘텐츠 자동 번역(한>독) Machine Translation transformer (Attension 기반) BLEU 0.38 점 0.4073 점 2 방송콘텐츠 자동 번역(한>불) Machine Translation transformer (Attension 기반) BLEU 0.38 점 0.4306 점 3 방송콘텐츠 자동 번역(한>이) Machine Translation transformer (Attension 기반) BLEU 0.32 점 0.3936 점 4 음성인식 Speech Recognition CTC + transformer 음성인식 알고리즘 CER 15 % 8.87 %
※ 데이터 성능 지표가 여러 개일 경우 각 항목을 클릭하면 해당 지표의 값이 그래프에 표기됩니다.
※ AI모델 평가 지표에 따라 측정값의 범위, 판단 기준이 달라질 수 있습니다. (ex. 오류율의 경우, 낮을수록 좋은 성능을 내는 것으로 평가됩니다)
-
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드1. 데이터 포맷
- 원천 음성 데이터No Field name Length Meaning a 대분류 2 rf(교양), dc(다큐), et(연예공연), md(영화드라마), vr(예능오락), iv(인터뷰) b 중분류 1 k(KBS), m(MBN), c(CJENM), p(KPSFF), t(tvN), s(ShowBox) c 소분류 3 프로그램명 관리 번호 d 프로그램 회차 3 프로그램별 회차 번호 e 씬정보 3 프로그램 해당 회차 내의 장면 순서 f 순서 4 프로그램 해당 회차 내의 분할 음성(문장) 순서 num file name 21 ex) rf_c_001_001_001_0001.wav - 라벨링 음성전사 데이터
No Field name Length Meaning a 대분류 2 rf(교양), dc(다큐), et(연예공연), md(영화드라마), vr(예능오락), iv(인터뷰) b 중분류 1 k(KBS), m(MBN), c(CJENM), p(KPSFF), t(tvN), s(ShowBox) c 소분류 3 프로그램명 관리 번호 d 프로그램 회차 3 프로그램 회차 번호 e 씬정보 3 프로그램 해당 회차 내의 장면 순서 f 순서 4 프로그램 해당 회차 내의 분할 음성(문장) 순서 num file name 21 ex) rf_c_001_001_001_0001.json - 라벨링 통번역 데이터
No Field name Length Meaning a 대분류 2 rf(교양), dc(다큐), et(연예공연), md(영화드라마), vr(예능오락), iv(인터뷰) b 중분류 1 k(KBS), m(MBN), c(CJENM), p(KPSFF), t(tvN), s(ShowBox) c 소분류 3 프로그램명 관리 번호 d 프로그램 회차 3 프로그램 회차 번호 e 씬정보 3 프로그램 해당 회차 내의 장면 순서 f 순서 4 프로그램 해당 회차 내의 분할 음성(문장) 순서 g 번역/발화 언어 2 en(미국영어), uk(영국영어), es(스페인어), ru(러시아어), de(독일어), fr(프랑스어), it(이탈리아어) num file name 24 ex) rf_c_001_001_001_0001_en.json - 라벨링 발화녹음 데이터
No Field name Length Meaning a 대분류 2 rf(교양), dc(다큐), et(연예공연), md(영화드라마), vr(예능오락), iv(인터뷰) b 중분류 1 k(KBS), m(MBN), c(CJENM), p(KPSFF), t(tvN), s(ShowBox) c 소분류 3 프로그램명 관리 번호 d 프로그램 회차 3 프로그램 회차 번호 e 씬정보 3 프로그램 해당 회차 내의 장면 순서 f 순서 4 프로그램 해당 회차 내의 분할 음성(문장) 순서 g 번역/발화 언어 2 en(미국영어), uk(영국영어), es(스페인어), ru(러시아어), de(독일어), fr(프랑스어), it(이탈리아어) num file name 24 ex) rf_c_001_001_001_0001_en.wav 2. 데이터 구성
분류 데이터 종류 언어 카테고리 구축시간 원천데이터 음성데이터 한국어 다큐 120시간 교양 120시간 연예, 공연 120시간 영화, 드라마 30시간 오락, 예능 120시간 인터뷰 90시간 라벨링데이터 음성전사데이터 한국어 다큐 120시간 교양 120시간 연예, 공연 120시간 영화, 드라마 30시간 오락, 예능 120시간 인터뷰 90시간 음성발화데이터 독일어 다큐 120시간 교양 120시간 연예, 공연 120시간 영화, 드라마 30시간 오락, 예능 120시간 인터뷰 90시간 프랑스어 다큐 120시간 교양 120시간 연예, 공연 120시간 영화, 드라마 30시간 오락, 예능 120시간 인터뷰 90시간 이탈리아어 다큐 120시간 교양 120시간 연예, 공연 120시간 영화, 드라마 30시간 오락, 예능 120시간 인터뷰 90시간 영국영어 연예, 공연 50시간 영화, 드라마 30시간 오락, 예능 120시간 인터뷰 90시간 통번역데이터 한국어-독일어 다큐 120시간 교양 120시간 연예, 공연 120시간 영화, 드라마 30시간 오락, 예능 120시간 인터뷰 90시간 한국어-프랑스어 다큐 120시간 교양 120시간 연예, 공연 120시간 영화, 드라마 30시간 오락, 예능 120시간 인터뷰 90시간 한국어-이탈리아어 다큐 120시간 교양 120시간 연예, 공연 120시간 영화, 드라마 30시간 오락, 예능 120시간 인터뷰 90시간 *영어의 경우 번역은 9번 과제에서 통합하여 진행하였고, 발화는 미국영어와 영국영어로 각각 진행하였음. 통번역데이터에 업로드한 한국어-영국영어 데이터는 한국어-미국영어 데이터와 거의 동일하나, 발화 관련 정보에 차이가 있음.
*또한, 영국영어 발화는 9번 과제에서 310시간, 10번 과제에서 290시간 구축함3. 어노테이션 포맷
- 음성전사 라벨 구성요소구분 속성명 타입 필수여부 설명 범위 비고 1 음성파일명 string Y 음성파일명 2 순서 string Y 전사순서 3 원시시작 string Y 원본 해당 음성 새그먼트 시작 4 원시끝 string Y 원본 해당 음성 새그먼트 끝 5 시작시간 string Y 음성 청크 시간 6 끝시간 string Y 음성 청크 끝 7 씬정보 string Y 씬 정보 8 전사작업본 string Y 전사 작업 내용 9 번역본 string Y 번역될 텍스트 10 발음전사 string Y 발음전사 11 철자전사 string Y 철자전사 12 발화자성별 string Y 발화자 성별 F/M, f/m 13 발화자연령대 number Y 발화자 연령대 10,20,30,40,50,60,70,80,90,100 14 신조어 string N 신조어 15 비속어 string N 비속어 16 배경음 string N 배경음 유무 O or null 17 잡음 string N 잡음 유무 O or null 18 비식별화 string N 비식별화 유무 - - 통번역용 라벨 데이터
구분 속성명 타입 필수여부 설명 범위 비고 1 대분류 string Y 다큐, 교양 등 2 중분류 string Y 방송사 3 소분류 string N 프로그램명 4 tsNum string Y 순서 5 SegNum string Y 청크 순서 6 S-Code string Y 출발음성 코드 fr-FR, ko-KR, it-IT, es-ES, en-US, en-GB 7 T-Code string Y 도착음성 코드 fr-FR, ko-KR, it-IT, es-ES, en-US, en-GB 8 S-Fname string Y 출발음성 파일명 9 T-Fname string Y 도착음성 파일명 10 S-ULength number Y 출발음성 길이 11 T-ULength number Y 도착음성 파일명 12 S-TLength number Y 출발음성 전사 길이 13 T-TLength number Y 도착음성 전사 길이 14 Ratio number Y 비율 15 특수표현 string Y 특수표현 16 S-USex string N 출발음성 발화자 성별 17 T-Usex string Y 도착음성 발화자 성별 18 S-UAge number N 출발음성 발화자 연령대 - 19 T-UAge number Y 도착음성 발화자 연령대 20 T-Nationality string Y 도착음성 발화자 출신지역 21 원문 string Y 22 수정원문 string N 23 MT string Y 24 1차수정 string N 25 2차수정 string N 26 최종번역문 string Y 27 수정번역문 string N 28 발화자ID string N 29 번역가ID string N 4. 데이터 예시
구분 JSON 구조 음성전사
"음성파일명": "md_c_003_014_006_0019.wav",
"순서": ”0013“,
"원시시작": 00:00:18,395
"원시끝": 00:00:22,910
"시작시간": 00:00.0
”끝시간“: 00:04.5
"씬정보": "006"
"전사작업본": "## 한강 근처 마포대교에서 막걸리 어때요?“
"번역본": "한강 근처 마포대교에서 막걸리 어때요?"
"발음전사": "한강 근처 마포대교에서 막걸리 어때요?"
"철자전사": "한강 근처 마포대교에서 막걸리 어때요?"
"발화자성별": "남"
"발화자연령대": 20
"신조어": "X"
"비속어": "X"
"배경음": "X“
"잡음": "X“
"비식별화": "X“
}번역
(한독){
"대분류": "영화드라마“
"중분류": "CJENM“
"소분류": "오늘의 타로맨스“
"tsNum": "004“
"SegNum": "014“
"S-Code": "ko-KR“
"T-Code": "de-DE“
"S-FName": "md_c_003_014_006_0019.wav“
"T-FName": "md_c_003_014_006_0019_de.wav“
"S-ULength": 4.52
"T-ULength": 5.12
"S-TLength": 21
"T-TLength": 72
"Ratio": 0.291667
"특수표현": ""
"S-USex": "f"
"T-USex": “f”
"S-UAge": 20
"T-UAge": 40
"T-Nationality": “독일”
"원문": "한강 근처 마포대교에서 막걸리 어때요?“
”수정원문“: ”N/A“
"MT": "Che ne dici di arrivare al ponte Marpo vicino al fiume Han?"
"1차수정": "Che ne dici di arrivare al ponte Marpo vicino al fiume Han?"
"2차수정": "Che ne dici di andare a bere Makeolli al ponte Mapo vicino al fiume Han?“
"최종번역문": "Che ne dici di andare a bere Makeolli al ponte Mapo vicino al fiume Han?“
”수정번역문“: ”N/A“
"발화자ID": "GMS-13",
"번역가ID": "SI_T_HSY"
}번역
(한불){
"대분류": "영화드라마“
"중분류": "CJENM“
"소분류": "오늘의 타로맨스“
"tsNum": "004“
"SegNum": "014“
"S-Code": "ko-KR“
"T-Code": "fr-FR“
"S-FName": "md_c_003_014_006_0019.wav“
"T-FName": "md_c_003_014_006_0019_fr.wav“
"S-ULength": 4.52
"T-ULength": 5.12
"S-TLength": 21
"T-TLength": 91
"Ratio": 0.291667
"특수표현": ""
"S-USex": "f"
"T-USex": “f”
"S-UAge": 20
"T-UAge": 40
"T-Nationality": “프랑스”
"원문": "한강 근처 마포대교에서 막걸리 어때요?“
”수정원문“: ”N/A“
"MT": "Que diriez-vous de makgeolli au pont Mapo près de la rivière Han ?"
"1차수정": "Que diriez-vous de makgeolli au pont Mapo près (Mapo Bridge) de la rivière Han (Han River)?"
"2차수정": "N/A“
"최종번역문": "Que diriez-vous de makgeolli au pont Mapo près (Mapo Bridge) de la rivière Han (Han River)?“
”수정번역문“: ”N/A“
"발화자ID": "FMS-01",
"번역가ID": "SI_T_PYJ"
}번역
(한이){
"대분류": "영화드라마“
"중분류": "CJENM“
"소분류": "오늘의 타로맨스“
"tsNum": "004“
"SegNum": "014“
"S-Code": "ko-KR“
"T-Code": "it-IT“
"S-FName": "md_c_003_014_006_0019.wav“
"T-FName": "md_c_003_014_006_0019_it.wav“
"S-ULength": 4.52
"T-ULength": 5.12
"S-TLength": 21
"T-TLength": 91
"Ratio": 0.291667
"특수표현": ""
"S-USex": "f"
"T-USex": “f”
"S-UAge": 20
"T-UAge": 40
"T-Nationality": “이탈리아”
"원문": "한강 근처 마포대교에서 막걸리 어때요?“
”수정원문“: ”N/A“
"MT": "Que diriez-vous de makgeolli au pont Mapo près de la rivière Han ?"
"1차수정": "Que diriez-vous de makgeolli au pont Mapo près (Mapo Bridge) de la rivière Han (Han River)?"
"2차수정": "N/A“
"최종번역문": "Que diriez-vous de makgeolli au pont Mapo près (Mapo Bridge) de la rivière Han (Han River)?“
”수정번역문“: ”N/A“
"발화자ID": "IC_T_ELISA!",
"번역가ID": "IC_T_WILL"
} -
데이터셋 구축 담당자
수행기관(주관) : ㈜디엠티랩스
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 김운 02-794-5333 yunjin@dmtlabs.co.kr 데이터구축 총괄PM 수행기관(참여)
수행기관(참여) 기관명 담당업무 사이버한국외국어대학교 산학협력단 데이터 가공, 검수 ㈜솔트룩스이노베이션 데이터 가공, 검수 ㈜시스트란 데이터 가공, 검수 ㈜아이시글로벌 데이터 가공, 검수 ㈜에버트란 데이터 정제, 가공, 검수 ㈜윤즈정보개발 데이터 정제, 가공, 검수 데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 김운 02-794-5333 yunjin@dmtlabs.co.kr
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 safezone1@aihub.kr 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.