-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.1 2023-12-29 데이터 최종 개방 1.0 2023-04-30 데이터 개방(Beta Version) 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2023-12-29 산출물 전체 공개 소개
1) 국내 자생식물의 유전자 염기서열 및 아미노산 서열 데이터 2) 국내 자생식물 유래 대사체의 SMILES 데이터
구축목적
1) 유전체 데이터 학습용 데이터 1-1) 조직별 유전자 발현 여부 분류를 수행하도록 인공지능을 학습시키기 위한 데이터셋 구축 1-2) 유전자의 효소 기능 분류를 수행하도록 인공지능을 학습시키기 위한 데이터셋 구축 2) 식물의 대사체로부터 생리활성 분류를 수행하도록 인공지능을 학습시키기 위한 데이터셋 구축
-
메타데이터 구조표 데이터 영역 농축수산 데이터 유형 텍스트 데이터 형식 csv 데이터 출처 식물 유전체, 문헌 정보 등 라벨링 유형 분류 라벨링 형식 JSON 데이터 활용 서비스 식물자원 발굴 서비스, 화합물 발굴 서비스 데이터 구축년도/
데이터 구축량2022년/554,569,672건 -
1. 데이터 구축 규모
데이터 종류 데이터 형태 모델명 원천 데이터 규모 어노테이션 규모 유전자 발현여부 분류를 위한 학습 데이터 식물 유전체 텍스트 sEEPP 353,452,500 6,806,493 유전자 EC number 분류를 위한 학습 데이터 식물 유전체 텍스트 ENC 7,690,892 7,690,892 대사체의 생리활성 분류를 위한 학습 데이터 실험 문헌정보 텍스트 PBA 360 360 총 계 361,143,752 14,497,745 2. 데이터 분포
가. 유전자 발현 여부 분류를 위한 학습 데이터데이터 구분 수량 구성비 유전자 발현 1,330,164 15.63% 유전자 미발현 7,178,016 84.37% 나. 유전자 EC number 분류를 위한 학습 데이터
- 효소 분포:
데이터 구분 수량 구성비 비효소 5,760,151 74.90% 효소 1,930,741 25.10% 다. 대사체의 생리활성 분류를 위한 학습 데이터
데이터 구분 positive 수량 구성비 항산화능 169 28.84% 신경세포 독성 197 33.62% 항염증 및 면역 160 27.30% 지질대사 60 10.24% 합계 586 100 -
-
AI 모델 상세 설명서 다운로드
AI 모델 상세 설명서 다운로드 AI 모델 다운로드1. sEEPP
가. Model description
sEEPP (simplified Enzyme Expression Profile Predictor)는 자생 식물 82종의 유전자 및 유전자 조절인자 염기서열 데이터로부터 각 종의 1~5개 부위에서의 유전자 발현 여부를 분류하는 모델이다.나. Model architecture
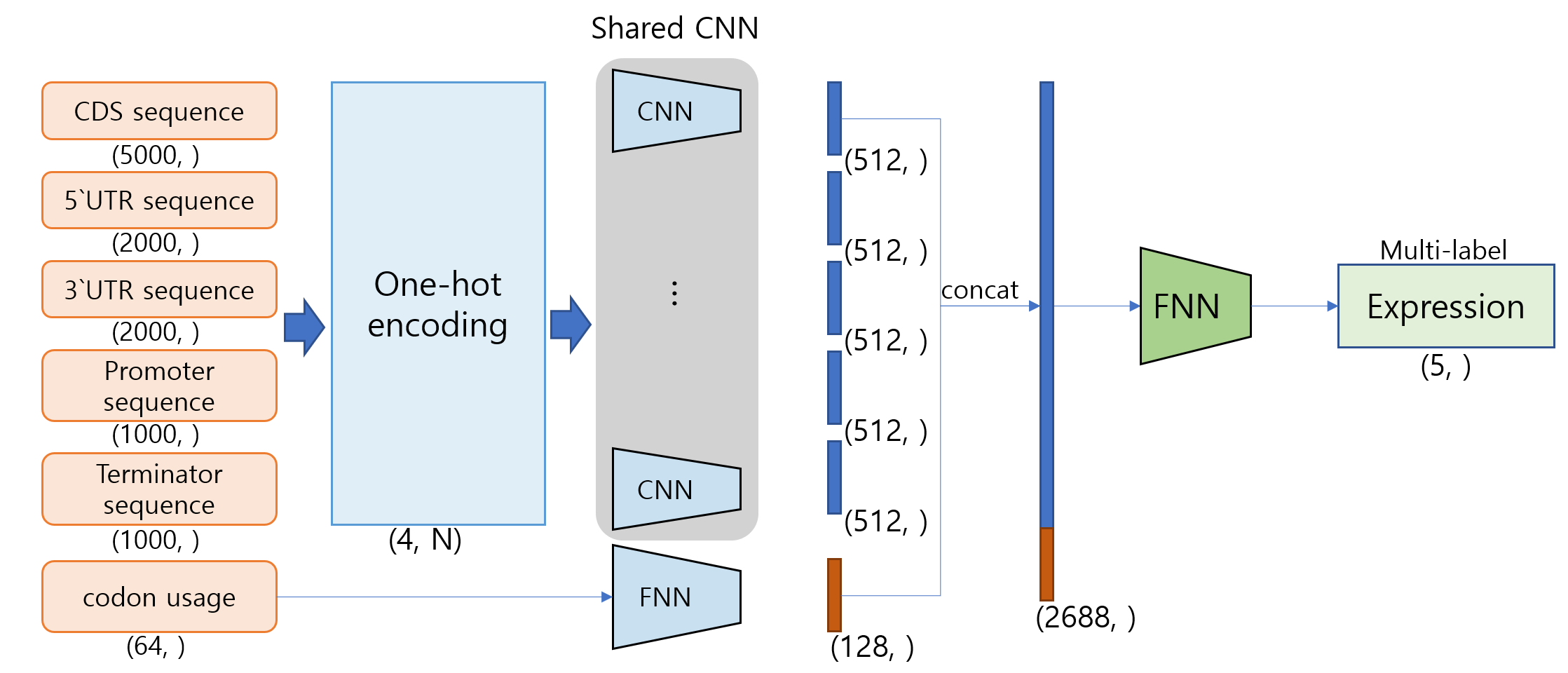
5가지 종류의 염기서열은 각각 one-hot encoding을 거쳐 matrix로 변환된다. 5가지 matrix는 shared-CNN을 통과하여 각각 512-dim vector가 된다. codon usage는 FNN을 통과하여 128-dim vector가 되며, shared-CNN의 output layer와 concat되어 2688-dim vector가 만들어진다. 이후 FNN을 거쳐 model output은 5-dim vector가 된다.
다. Input
5가지 종류의 염기서열은 one-hot encoding을 거친 후 사용되며, input shape는 위 설명과 같다.라. Output
output은 5-dim vector (binary)이다.마. Task
5개 부위에서의 발현 여부를 분류하는 multi-label classification 모델이다.바. Training factors
training factors value max epoch 1000 batch size 256 optimizer Adam learning rate 1.00E-03 weight decay 1.00E-06 learning rate scheduler ReduceLROnPlateau mode min factor 0.5 patience 5 loss function BCEWithLogitsLoss early stopping patience 10 2. ENC
가. Model description
ENC (Enzyme commission Number Classifier)는 자생식물 120종의 유전자 아미노산 서열 데이터로부터 유전자의 기능을 EC number 형태로 분류하는 모델이다.나. Model architecture
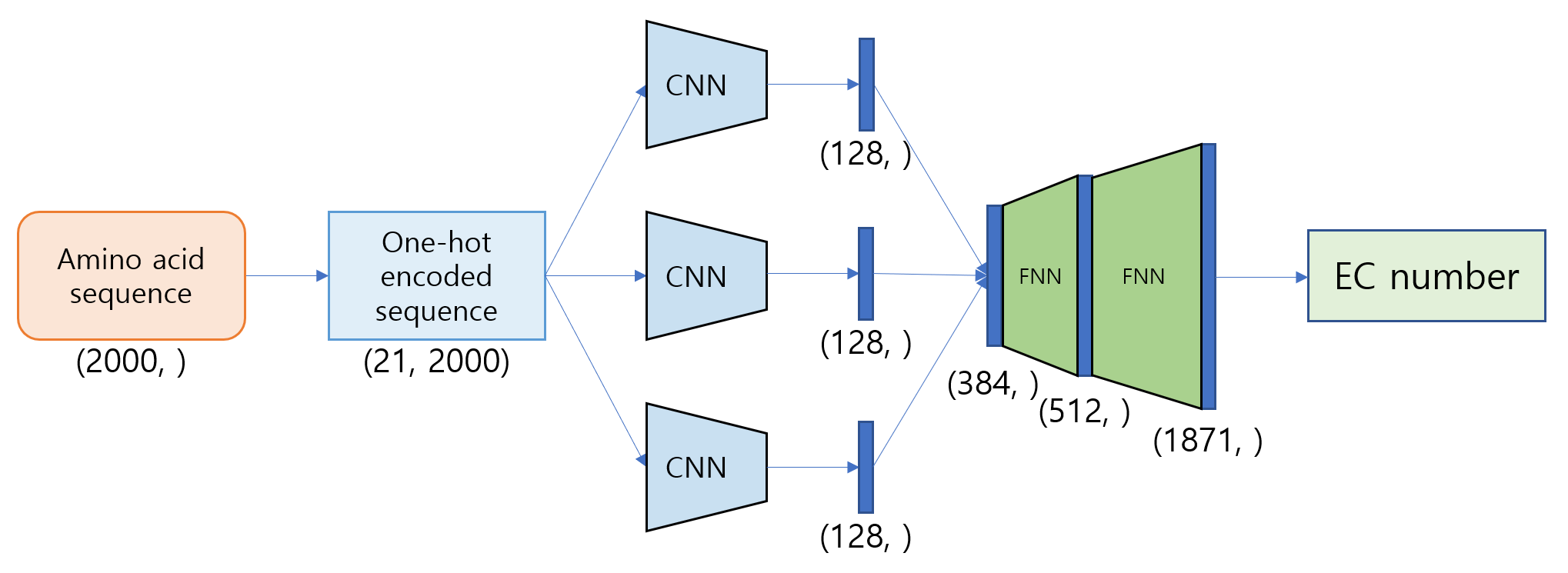
아미노산 서열은 one-hot encoding을 거쳐 21*2000 크기의 matrix로 변환된다. matrix는 kernel size가 다른 3개의 CNN을 통과하여 각각 128-dim vector가 된다. 3개의 CNN의 output은 concat되어 384-dim vector가 되며, 두 번의 FNN을 거쳐 model output은 1871-dim vector가 된다.
다. Input
아미노산 서열은 one-hot encoding을 거친 후 사용되며, input shape는 위 설명과 같다.라. Output
output은 1871-dim vector로, decoder (argmax)를 통해 EC number로 변환된다.마. Task
1871개 EC number를 분류하는 multi-class classification 모델이다.바. Training factors
training factors value max epoch 1000 batch size 256 optimizer Adam learning rate 1.00E-03 weight decay 1.00E-08 learning rate scheduler ReduceLROnPlateau mode min factor 0.5 patience 5 loss function CrossEntropyLoss early stopping patience 10 3. PBA
가. Model description
PBA (Predictor of Biological Activities)는 대사체 구조 정보로부터 대사체의 4가지 생리활성 여부를 분류하는 모델이다.나. Model architecture

SMILES code를 2048-dim vector인 extended-connectivity fingerprint로 변환한다. 변환된 fingerprint가 FNN을 거쳐 model output인 4-dim vector가 된다.다. Input
SMILES code는 2048-dim vector인 extended-connectivity fingerprint로 변환되어 사용된다.라. Output
output은 4-dim vector (binary)이다.마. Task
4가지 종류의 생리활성 여부를 분류하는 multi-label classification 모델이다.바. Training factors
training factors value max epoch 1000 batch size 16 optimizer Adam learning rate 1.00E-03 weight decay 1.00E-08 learning rate scheduler ReduceLROnPlateau mode min factor 0.1 patience 20 loss function BCEWithLogitsLoss early stopping patience 50 -
데이터 성능 점수
측정값 (%)기준값 (%)데이터 성능 지표
데이터 성능 지표 번호 측정항목 AI TASK 학습모델 지표명 기준값 점수 측정값 점수 1 화합물별 생리활성 분류 성능 Text Classification FingerPrint Module + MLP AUC-ROC 0.7 단위없음 0.7419 단위없음 2 유전자 발현 여부 분류 성능 Text Classification 1D CNN + MLP F1-Score 0.6 점 0.6096 점 3 EC Number 분류 성능 Text Classification 1D CNN + MLP F1-Score 0.6 점 0.8519 점
※ 데이터 성능 지표가 여러 개일 경우 각 항목을 클릭하면 해당 지표의 값이 그래프에 표기됩니다.
※ AI모델 평가 지표에 따라 측정값의 범위, 판단 기준이 달라질 수 있습니다. (ex. 오류율의 경우, 낮을수록 좋은 성능을 내는 것으로 평가됩니다)
-
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드1. 데이터 구성
가. 유전자 발현여부 분류를 위한 학습 데이터 (sEEPP)
- 원천 데이터:< 원천 데이터 >
원천 데이터 이름 원천 데이터 설명 원천 데이터 형식 cds 유전자 예측 기반으로 추출된 유전자의 염기서열 csv format promoter 유전자 예측 기반으로 추출된 promoter의 염기서열 csv format terminator 유전자 예측 기반으로 추출된 terminator의 염기서열 csv format utr5 유전자 예측 기반으로 추출된 5’UTR의 염기서열 csv format utr3 유전자 예측 기반으로 추출된 3’UTR의 염기서열 csv format codon_usage 유전체로부터 예측된 유전자의 codon에 대한 빈도 데이터 csv format < 원천 데이터 cds.csv 명세 >
항목 설명 데이터타입 예시 gene_id 유전자 고유번호 Number 1 cds 유전자 염기서열 String ATTGACCTA... < 원천 데이터 promoter.csv 명세 >
항목 설명 데이터타입 예시 gene_id 유전자 고유번호 Number 1 promoter promoter 염기서열 String AAATGATCC... < 원천 데이터 terminator.csv 명세 >
항목 설명 데이터타입 예시 gene_id 유전자 고유번호 Number 1 terminator terminator 염기서열 String AAATGATCC... < 원천 데이터 utr5.csv 명세 >
항목 설명 데이터타입 예시 gene_id 유전자 고유번호 Number 1 utr5 5’UTR 염기서열 String AAATGATCC... < 원천 데이터 utr3.csv 명세 >
항목 설명 데이터타입 예시 gene_id 유전자 고유번호 Number 1 utr3 3’UTR 염기서열 String AAATGATCC... < 원천 데이터 codon_usage.csv 명세 >
항목 설명 데이터타입 예시 gene_id 유전자 고유번호 Number 1 codon 코돈 고유번호 Number 1 count 코돈의 출현 빈도 수 Number 4 ratio 코돈의 출현 빈도 비율 Number 0.05 - not_labeled_sEEPP data의 구조는 원천 데이터와 동일함
나. 유전자 EC number 분류를 위한 학습 데이터 (ENC)
- 원천 데이터:< 원천 데이터 >
원천 데이터 이름 원천 데이터 설명 원천 데이터 형식 amino_acid 유전자 예측 기반으로 추출된 유전자의 아미노산 서열 csv format < 원천 데이터 amino_acid.csv 명세 >
항목 설명 데이터타입 예시 gene_id 유전자 고유번호 Number PA000001.1 amino_acid 유전자 아미노산 서열 String MDSKTDVVE... 다. 대사체의 생리활성 분류를 위한 학습 데이터 (PBA)
- 원천 데이터:< 원천 데이터 >
원천 데이터 이름 원천 데이터 설명 원천 데이터 형식 pba_data 실험 혹은 문헌을 통해 확보된 생리활성을 가지는 대사체 정보 csv format < 원천 데이터 pba_data.csv 명세 >
항목 설명 데이터타입 예시 compound_id 화합물 id Number 5281807 smiles_code 화합물 SMILES code String OC[C@H]1O[C@H]([C@H](O)[C@@H](O)[C@@H]1O)c1c(O)ccc2c1occ(-c1ccc(O)cc1)c2=O - 자생식물 대사체 데이터:
< 자생식물 대사체 데이터 compounds_data.csv 속성 >
속성명 속성 설명 데이터타입 필수여부 예시 plant_name 성분이 추출된 식물 학명 String Y Pueraria lobata part 성분이 추출된 식물 부위 String N 뿌리 compound_id 화합물 id Number Y 5281807 compound_name 성분 이름 String Y puerarin smiles 성분의 SMILES 문자열 String Y OC[C@H]1O[C@H]([C@H](O)[C@@H](O)[C@@H]1O)c1c(O)ccc2c1occ(-c1ccc(O)cc1)c2=O inchikey 성분의 InChIKey 값 String N HKEAFJYKMMKDOR-WQTKVTHMNA-N structure_file 성분의 구조식 그림 파일명 String Y 구조식 그림 파일명 (5281807.jpg) 
< 구조식 그림 파일 예시 >
2. 어노테이션 포맷
가. 유전자 발현여부 분류를 위한 학습 데이터 (sEEPP)구분 속성명 타입 필수여부 설명 범위 비고 1 plant_name String Y 식물 종명 2 csv_file[] Array Y 원천 csv 파일 3 organ_list[] Array Y 데이터가 존재하는 부위 최대 5개 (leaf, root, stem, bud, flower) 4 label_count Number Y 데이터 개수 5 label[] Array Y 라벨링 정보 5-1 gene_id Number Y 유전자 고유번호 5-2 organ String Y 유전자 발현 부위 명 5-3 expression_valid Number Y 유전자 발현 여부 0~1 0: 미발현 1: 발현 나. 유전자 EC number 분류를 위한 학습 데이터 (ENC)
구분 속성명 타입 필수여부 설명 범위 비고 1 plant_name String Y 식물 종명 2 csv_file[] String Y 원천 csv 파일 3 label_count Number Y 데이터 개수 4 label[] Array Y 라벨링 정보 4-1 gene_id Number Y 유전자 고유번호 4-2 enzyme Number Y 효소 유전자 여부 0~1 0: 비효소 1: 효소 4-3 ec_class Number Y EC number 첫째 자리 0~7 0: 비효소 4-4 ec_subclass Number Y EC number 둘째 자리 0~99 0: 비효소 4-5 ec_subsubclass Number Y EC number 셋째 자리 0~99 0: 비효소 4-6 ec_serial Number Y EC number 넷째 자리 0~999 0: 비효소 4-7 score Number Y EC number 신뢰도 점수 [0, 15~400] 0: 비효소 다. 대사체의 생리활성 분류를 위한 학습 데이터 (PBA)
구분 속성명 타입 필수여부 설명 범위 비고 1 csv_file[] Array Y 원천 csv 파일 2 label_count Number Y 데이터 개수 3 label[] Array Y 라벨링 정보 3-1 compound_id Number Y 화합물 고유번호 3-2 antioxidant Number Y 항산화능 여부 0~1 0: 비활성 1: 활성 3-3 protection_toxicity Number Y 신경세포 독성 여부 0~1 0: 비활성 1: 활성 3-4 antiinflammation_ immunity Number Y 항염증 및 면역 여부 0~1 0: 비활성 1: 활성 3-5 lipid_metabolism Number Y 지질대사 여부 0~1 0: 비활성 1: 활성 3-6 reference[] Array N 참고문헌 PMID 3. 어노테이션 실제 예시
유전자 발현여부 분류를 위한
학습 데이터
(sEEPP){
"plant_name": "Acorus_gramineus",
"csv_file": [
"data/sEEPP/Acorus_gramineus/cds.csv",
"data/sEEPP/Acorus_gramineus/codon_usage.csv",
"data/sEEPP/Acorus_gramineus/promoter.csv",
"data/sEEPP/Acorus_gramineus/terminator.csv",
"data/sEEPP/Acorus_gramineus/utr3.csv",
"data/sEEPP/Acorus_gramineus/utr5.csv"
],
"organ_list": [
"leaf"
],
"label_count": 10000,
"label": [
{
"gene_id": 532408464,
"organ": "leaf",
"expression_valid": 0
},
{
"gene_id": 532417922,
"organ": "leaf",
"expression_valid": 0
},
⋮
]
}유전자 EC number 분류를 위한
학습 데이터
(ENC){
"plant_name": "Acorus_gramineus",
"csv_file": "/data/ENC/Acorus_gramineus/amino_acid.csv",
"label_count": 10000,
"label": [
{
"gene_id": 532376212,
"enzyme": 0,
"ec_class": 0,
"ec_subclass": 0,
"ec_subsubclass": 0,
"ec_serial": 0,
"score": 0.0
},
{
"gene_id": 532376217,
"enzyme": 0,
"ec_class": 0,
"ec_subclass": 0,
"ec_subsubclass": 0,
"ec_serial": 0,
"score": 0.0
},
⋮
]
}대사체 생리활성 분류를 위한
학습 데이터
(PBA){
"csv_file": [
"/data/PBA/pba_data.csv"
],
"label_count": 37,
"label": [
{
"compound_id": 10922465,
"antioxidant": 0,
"protection_toxicity": 1,
"antiinflammation_immunity": 0,
"lipid_metabolism": 0,
"reference": [
"8134418"
]
},
{
"compound_id": 60063,
"antioxidant": 0,
"protection_toxicity": 1,
"antiinflammation_immunity": 0,
"lipid_metabolism": 0,
"reference": [
"8134418"
]
},
⋮
]
} -
데이터셋 구축 담당자
수행기관(주관) : 인포보스 주식회사
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 박종선 02-2698-1188 starflr@infoboss.co.kr 총괄책임 수행기관(참여)
수행기관(참여) 기관명 담당업무 한국한의학연구원 데이터 수집, 데이터 정제, 데이터 가공 서울대학교 산학협력단 데이터 수집 성균관대학교 산학협력단 데이터 검수 데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 박종선 02-2698-1188 starflr@infoboss.co.kr
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 safezone1@aihub.kr 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.