-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.1 2023-10-06 원천데이터 재개방 1.0 2022-07-28 데이터 최초 개방 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2022-10-13 신규 샘플데이터 개방 2022-07-28 콘텐츠 최초 등록 소개
컬러 변환, 편집 대상, 모양 변환의 다양한 편집 기능을 고려한 원본 이미지 파일을 수집하고 편집 명령어에 따른 편집 이미지를 획득하여 언어(텍스트) 명령어를 통한 사진 편집 기술에 활용될 수 있는 학습 데이터셋 구축. 해당 데이터를 통해 인공지능 이미지 편집모델을 구현하고 실제 서비스를 개발하여 활용될 수 있도록 함.
구축목적
– 모바일 어플리케이션, 방송, 영화, 영상 콘텐츠, 디자인 등 다양한 이미지 편집 활용 산업에 적용 가능한 언어 기반 이미지 편집 기술 개발용 대규모 공공 데이터 구축 – 한국어 명령어와 한국 실정에 맞는 이미지를 수집함으로써 국내 인공지능 기반 서 비스의 품질을 높일 수 있는 데이터 구축 – 언어 기반 이미지 편집 인공지능 개발에 핵심인 인공지능 학습용 데이터를 구축
-
메타데이터 구조표 데이터 영역 영상이미지 데이터 유형 텍스트 , 이미지 데이터 형식 txt, jpg 데이터 출처 크라우드소싱 라벨링 유형 폴리곤 세그멘테이션(이미지) / 편집 명령어(자연어) 라벨링 형식 JSON 데이터 활용 서비스 이미지 자동 편집 서비스 데이터 구축년도/
데이터 구축량2021년/원천이미지 5,087장, 편집이미지 146,518장 -
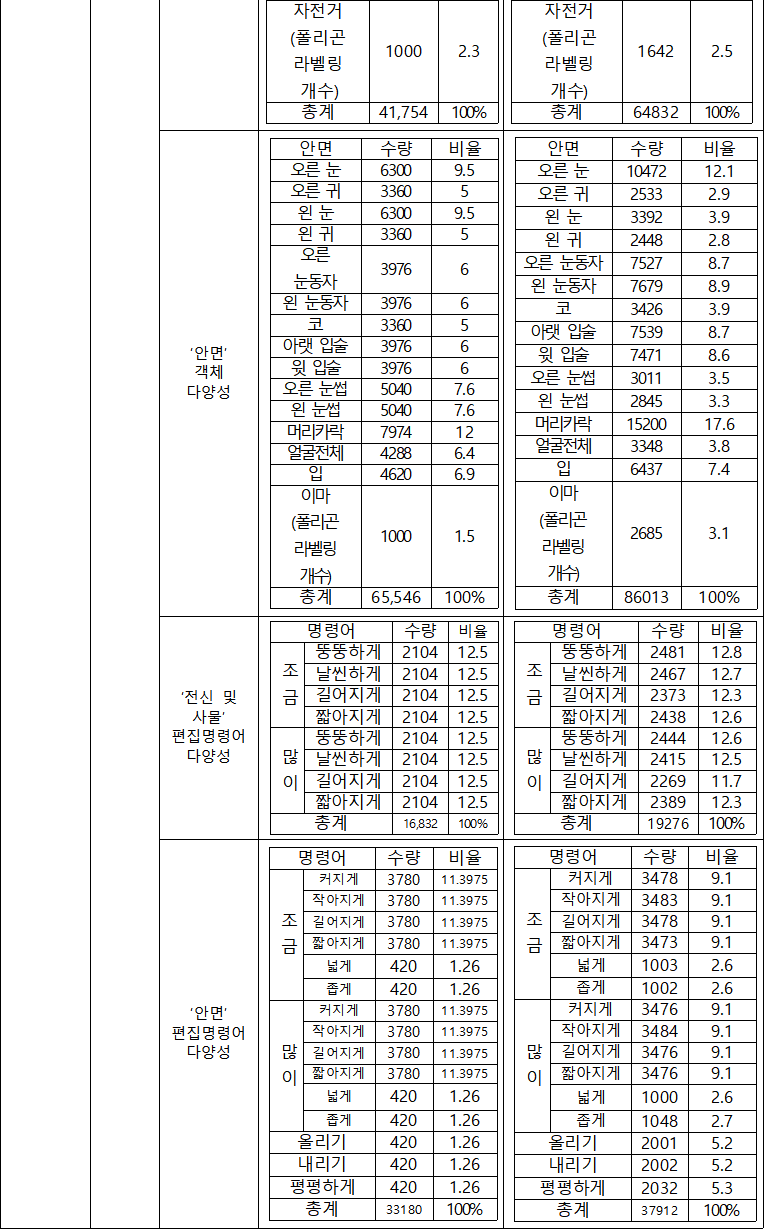
세부과제 산출물 성과 기준 결과 텍스트 기반 이미지 편집 데이터셋 (데이터 41) 데이터셋 총 원천이미지 수량 5,000장 5,087장 총 편집이미지 수량 10만 장 이상 146,518장 전신 및 안면 편집이미지 수량 전신 : 안면 = 4:6 비율 (각 40,000장, 60,000장 이상) 전신 편집이미지: 63,190장 / 안면 편집이미지: 83,328장 색상변환 및 모양변환 편집이미지 수량 별도로 없음 색상변환 편집이미지: 89,330장 / 모양변환 편집이미지: 57,188장 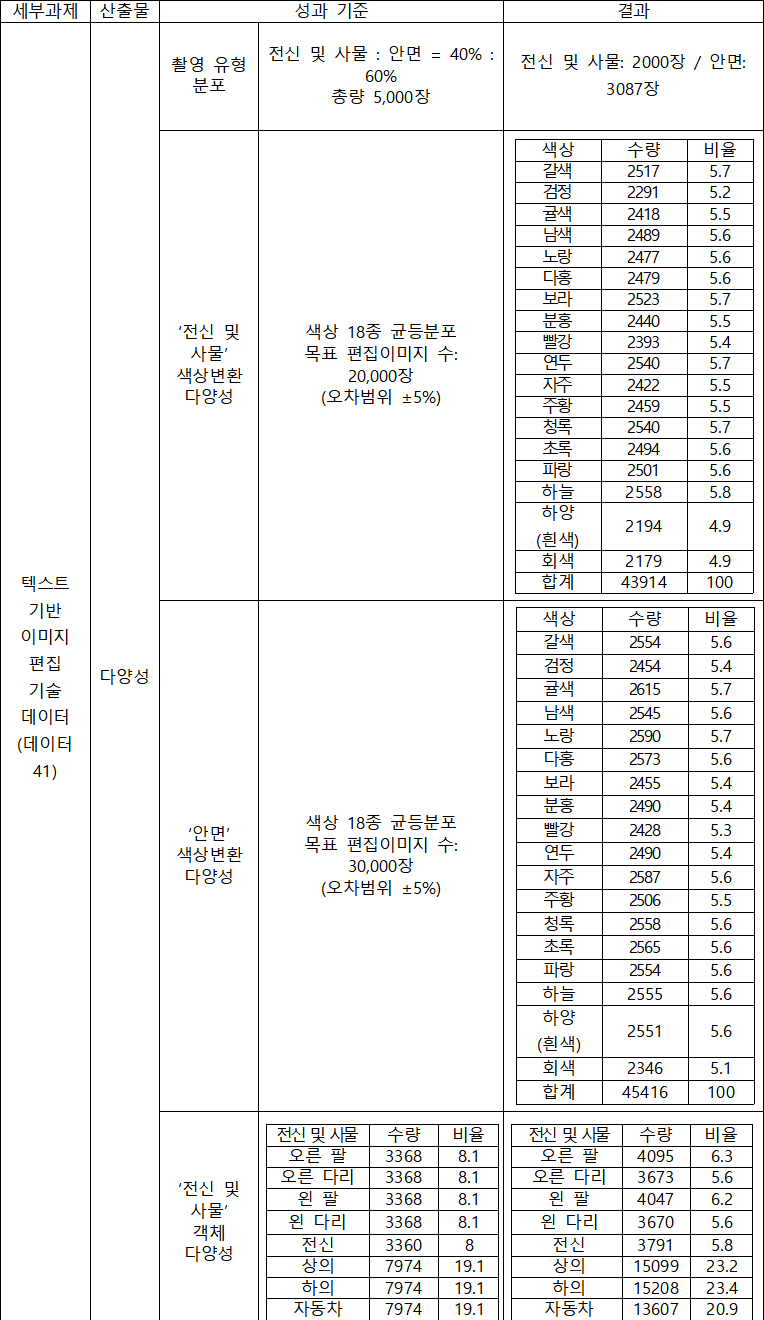
-
-
AI 모델 상세 설명서 다운로드
AI 모델 상세 설명서 다운로드 AI 모델 다운로드1. 사용 데이터
- 자동차 또는 자전거를 포함하는 인물의 전신사진
1. 사용 데이터 Total set Training set Validation set Test set 2,000 1,598 201 201 - 신체부위, 의상, 탈것 등 정의된 클래스에 대한 Polygon 좌표를 라벨링 데이터의 json 파일로부터 로드하여 모델 학습에 필요한 형태로 변환
- 모델 알고리즘이 요구하는 데이터의 형태가 bounding box인 경우 polygon으로부터 간단하게 bounding box 형태를 추출할 수 있으며 object detection + segmentation 모델의 경우 polygon 좌표를 그대로 사용

[전신_자동차 원본 예시]

[전신_자동차 polygon, bounding box 예시]-
안면 사진
Total set Training set Validation set Test set 3,087 2,468 310 309 - Train 2468 케이스, Test 310 케이스, val 309 케이스
- 눈, 눈썹, 입술, 코 등 정의된 클래스에 대한 Polygon을 json 파일로부터 로드 및 모델 학습에 필요한 형태로 변환

[얼굴 원본 예시]

[얼굴 polygon, bounding box 예시]- 데이터 전처리
- 모델 알고리즘 별로 요구하는 annotation 형식에 맞추어 json파일의 라벨 정보를 변환 및 저장하여 학습 활용
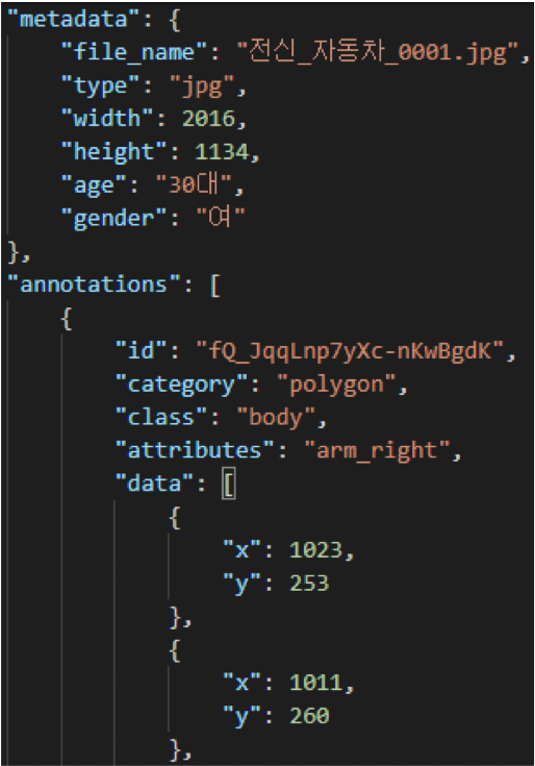
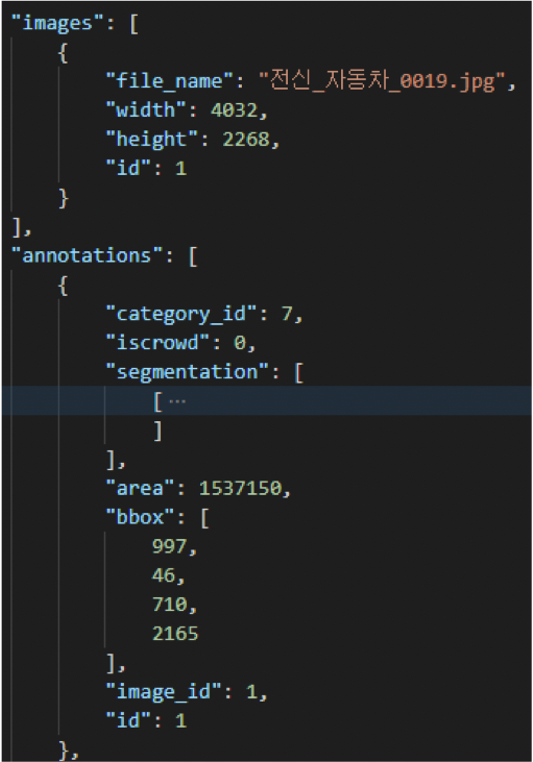
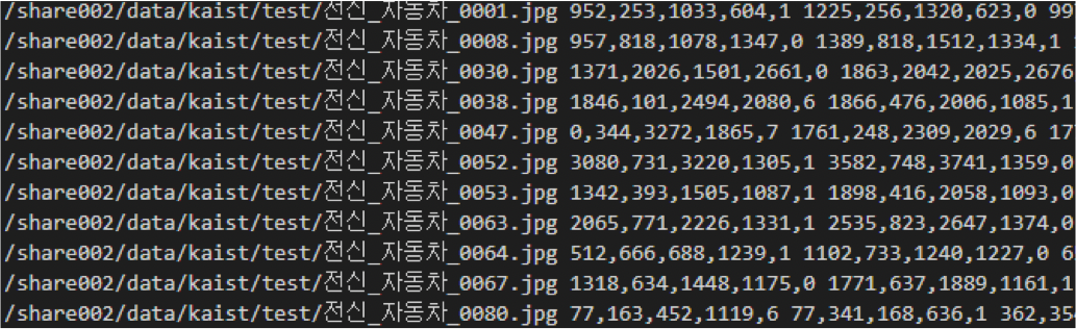
[라벨링 데이터 변환 예시(keras yolo)]
2. 모델학습
- Object detection model
- keras-yolo3
- 일정 수준의 정확도는 만족하지만 인식 속도가 떨어지는 기존 객체 인식 모델들의 문제점을 해결하기 위해 고안된 yolov3 사용.
- Adam Optimizer (LR=1e-3)
- Batch Size : 16
- EPochs : 200 (frozen layers 100 + unfreeze layer 100)
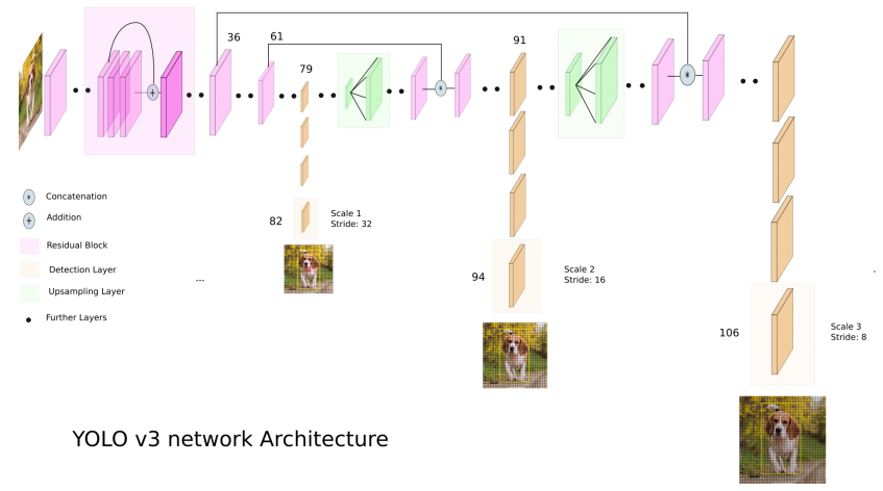
[ yolov3의 구조 ]
- Faster R-CNN
- 기존 Fast R-CNN의 구조를 계승하며 selective search 대신 Region Proposal Network를 사용해 GPU를 통한 RoI 계산 수행.
- Adam Optimizer (LR=1e-5)
- EPochs : 200
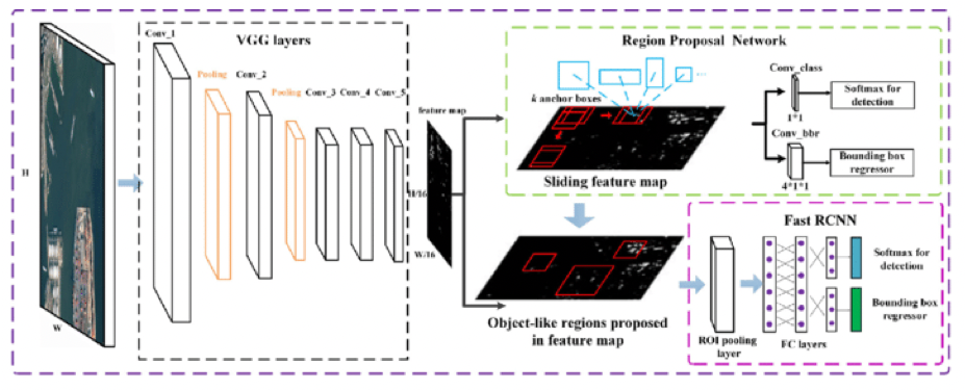
[ Faster-RCNN의 구조 ]
- SSD
- 속도 측면에서 많은 발전을 이루었지만 정확도가 부족하고 작은 물체 인식이 어려운 Yolo의 한계를 해결하기 위해 고안된 SSD(Single Shot Multibox Detector) 사용.
- Learning Rate : 1e-3
- Batch Size : 24
- iteration : 150000

[ SSD의 구조 ]
- keras-yolo3
- Object detection + Segmentation model
- Mask R-CNN
- Faster R-CNN의 RPN에서 얻은 RoI에 대해 객체의 class와 bbox regression을 수행하는 것과 평행하게 segmentation mask를 예측하는 mask branch를 추가한 구조
- learning rate : 1e-3
- Batch Size : 2
- EPochs : 160 (network heads – 40 / fine tune resnet stage – 80 / fine tune all – 40)
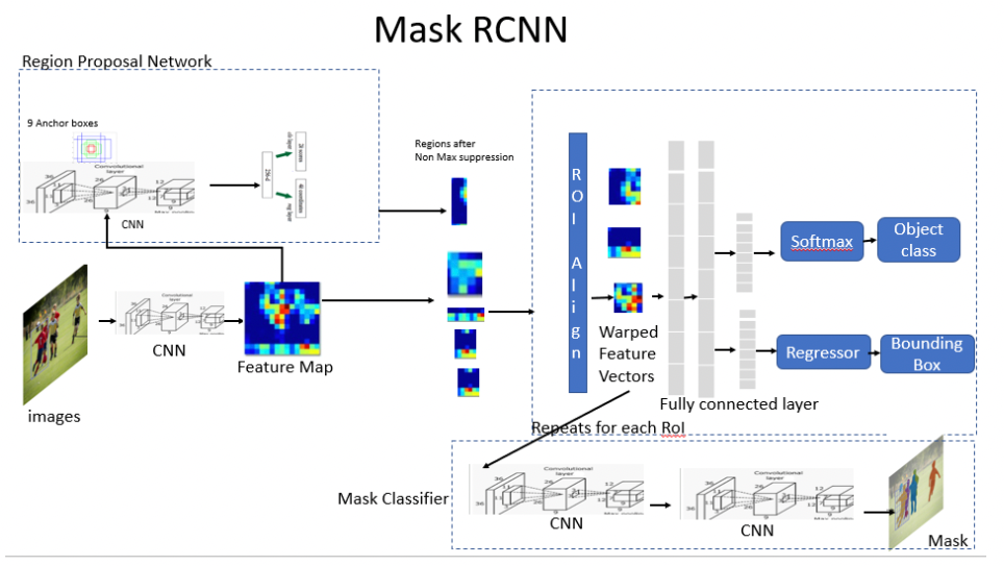
[ Mask RCNN의 구조 ]
- yolact
- Instance segmentation 문제를 실시간으로 해결하기 위해 object detection의 SSD와 YOLO에서 영감을 얻어 Resnet-101을 기반으로 고안된 모델.
- Adam Optimizer (LR=1e-4)
- Batch Size : 8
- iteration : 200000
[ yolact의 구조 ]
- Mask R-CNN
- 자동차 또는 자전거를 포함하는 인물의 전신사진
-
데이터 성능 점수
측정값 (%)기준값 (%)데이터 성능 지표
데이터 성능 지표 번호 측정항목 AI TASK 학습모델 지표명 기준값 점수 측정값 점수 1 객체 인식 정확도 Object Detection Faster R-CNN mAP 45 % 72.33 %
※ 데이터 성능 지표가 여러 개일 경우 각 항목을 클릭하면 해당 지표의 값이 그래프에 표기됩니다.
※ AI모델 평가 지표에 따라 측정값의 범위, 판단 기준이 달라질 수 있습니다. (ex. 오류율의 경우, 낮을수록 좋은 성능을 내는 것으로 평가됩니다)
-
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드



편집 대상 객체 폴리곤 어노테이션 포맷
편집 대상 객체 폴리곤 어노테이션 포맷 구분 항목명 타입 필수여부 설명 범위 비고 1 metadata Object Y 이미지 메타데이터 01월 01일 file_name string Y 파일명 0001.JPG 01월 02일 type string Y 데이터 형식 PNG, JPG 01월 03일 width number Y 이미지 너비 01월 04일 height number Y 이미지 높이 01월 05일 gender string Y 이미지 내 대상 객체의 성별 01월 06일 age number Y 이미지 내 대상 객체의 연령대 2 annotations Arr[Object]] Y 어노테이션 리스트 02월 01일 id string Y 어노테이션 식별자 02월 02일 category string Y 카테고리 polygon (BBox, Polygon 등) 02월 03일 class string Y 객체 대분류 얼굴, 신체, 의류, 배경 등 02월 04일 attributes string Y 객체 소분류 눈, 코, 입, 오른쪽 팔, 자동차 등 02월 05일 data Arr[Object] Y 객체 정보(x, y) [ {“x”: 15, “y”: 20},
{“x”: 25, “y”: 40...]편집 이미지 어노테이션 포맷
구분 항목명 타입 필수여부 설명 범위 비고 1 metadata Object Y 이미지 메타데이터 01월 01일 file_name string Y 파일명 0001.JPG 01월 02일 type string Y 데이터 형식 PNG, JPG 01월 03일 width number Y 이미지 너비 01월 04일 height number Y 이미지 높이 01월 05일 gender string Y 이미지 내 대상 객체의 성별 01월 06일 age number Y 이미지 내 대상 객체의 연령대 2 annotations Arr[Object]] Y 어노테이션 리스트 02월 01일 modified_file_name string Y 수정된 이미지 파일명 전신_자동차_0017_전신_조금길어지게.jpg 02월 02일 command string Y 이미지 수정 명령어 색상_검정, 모양_넓히기 등 02월 03일 command_object string Y 편집 대상 객체 {id: 1, name: ‘eye’} 02월 04일 command_color string Y 편집 색상 {id: 1, name: ‘blue’} 02월 05일 command_shape string Y 편집 모양 {id: 1, name: ‘rotate’} 02월 06일 command_verb string N 수정 명령어 문장 내 동사 형태 해주세요, 해줘, 바꿔 02월 07일 similar_command_1 string Y 이미지 수정 유사명령어 1 02월 08일 similar_command_2 string Y 이미지 수정 유사명령어 2 02월 09일 similar_command_3 string Y 이미지 수정 유사명령어 3 02월 10일 similar_command_4 string Y 이미지 수정 유사명령어 4 -
데이터셋 구축 담당자
수행기관(주관) : 한국과학기술원
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 박주용 042-350-2924 juyongp@kaist.ac.kr · 데이터 구축 총괄 및 설계 수행기관(참여)
수행기관(참여) 기관명 담당업무 메트릭스리서치 · 데이터 수집 및 정제 소리자바 · 데이터 수집 및 정제 KBS · 데이터 수집 및 정제 데이터메이커 · 데이터 가공 및 검수 액션파워 · 데이터 학습모델 개발 미소정보기술 · 데이터 학습모델 개발 인터마인즈 · 데이터 검수 및 품질검증 데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 박주용 042-350-2924 juyongp@kaist.ac.kr
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 safezone1@aihub.kr 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.