가상공간 환경음 매칭 데이터
- 분야영상이미지
- 유형 오디오
-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.1 2024-01-05 데이터 최종 개방 1.0 2023-04-30 데이터 개방(Beta Version) 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2024-01-26 산출물 전체 공개 소개
가상 공간 및 구체적인 청각 장면 등이 필요한 다양한 미디어 콘텐츠(메타버스, 게임, 영화 등) 창제작 분야에 다양하게 응용 가능한 2종의 대분류(공간/환경, 시나리오), 3종의 중분류(현실 공간/환경, 가상 공간/환경, 인공적 시나리오), 121종 소분류로 구성된 본 데이터는 필드레코딩, 폴리/합성 등의 방식을 통해 총 39,130개, 797.3시간 분량의 인공지능 학습용 데이터를 구축함. * 폴리/합성: 폴리 사운드, 아날로그/디지털 신디사이저(VSTi), FX 사운드 등의 오디오 파일을 녹음 또는 조합하여 가상 및 인공 시나리오의 음향 장면을 제작하는 방식 및 그에 대한 결과물을 의미함
구축목적
메타버스, 컴퓨터 게임 내에서의 공간음향 자동 생성 및 1인 미디어 콘텐츠 제작시 사용되는 음향 장면 자동 생성 등 여러 상황, 맥락, 시나리오에 따라 매칭 가능한 다양한 음색을 가진 공간 환경 음원 데이터 구축
-
메타데이터 구조표 데이터 영역 영상이미지 데이터 유형 오디오 데이터 형식 mp3, wav 데이터 출처 자체 수집 라벨링 유형 클래스 분류 라벨링 형식 json 데이터 활용 서비스 가상공간 및 미디어 콘텐츠 음향 장면 검색 및 매칭 데이터 구축년도/
데이터 구축량2022년/39,130건 -
1. 데이터 구축 규모 및 종류별 분포
데이터 구축 규모 및 종류별 분포 기준 현실 공간/환경 가상 공간/환경 인공적 시나리오 총계 데이터 종류별 비율 (%) 39.67% 19.01% 41.32% 100.00% 소분류별 샘플 개수 (개) 400개 이상 250개 이상 250개 이상 평균 300개 총 샘플 개수 (개) 20,169 6,063 12,898 37,450 데이터 종류별 평균 길이 (초) 100 45 45 평균 63초 데이터 종류별 총 길이 (분) 33,618 4,542 9,654 47,814 데이터 종류별 총 길이 (시간) 560.3 75.7 160.9 796.9 2. 분류별 구축 데이터 수량 및 시간
분류별 구축 데이터 수량 및 시간 대분류 중분류 소분류 수량 시간 1.공간/환경 1. 현실 공간/환경 001.호텔 416 11.6 002.병원 416 11.6 003.놀이공원 413 11.5 004.상업몰 417 11.6 005.공항 434 12.1 006.전시장 402 11.2 007.백화점 400 11.1 008.마트 400 11.1 009.재래시장 413 11.5 010.지하상가 404 11.2 011.주차장 400 11.1 012.버스 정류장 408 11.3 013.버스 터미널 400 11.1 014. 지하철역 400 11.1 015. 기차역 405 11.3 016. 레스토랑/음식점 400 11.1 017. 카페 400 11.1 018. 술집 400 11.1 019. 영화관 407 11.3 020. 헬스장 400 11.1 021. 상업지역 400 11.1 022. 도서관 401 11.1 023. 공원 401 11.1 024. 관공서 437 12.1 025. 사무실 435 12.1 026. 종교시설 400 11.1 027. 수영장 400 11.1 028. 경기장(실내) 403 11.2 029. 경기장(실외) 400 11.1 030. 교외 거주지역 454 12.6 031. 아파트 단지 438 12.2 032. 가정 실내 402 11.2 033. 룸톤 488 13.6 034. 도심 지역 417 11.6 035. 교통 소리 465 12.9 036. 군중 소리 400 11.1 037. 동물원 524 14.6 038. 학교 505 14 039. 창고 415 11.5 040. 공장 404 11.2 041. 항구 523 14.5 042. 숲 417 11.6 043. 드넓은 초원 400 11.1 044. 동굴 403 11.2 045. 바닷가 477 13.3 046. 강/계곡/하천/냇가 등 400 11.1 047. 호숫가 417 11.6 048. 폭포 408 11.3 2.가상 공간/환경 049.가상 업무 공간 283 3.5 050.고대 문명 도시 284 3.6 051.해저 도시 279 3.5 052.하늘 도시 287 3.6 053.판타지 중세 성 284 3.6 054.서부 총잡이 도시 294 3.7 055.공상과학_사이버펑크 미래도시 295 3.7 056.무한한 터널 250 3.1 057.타임머신 253 3.2 058. 워프 250 3.1 059. 레이싱 251 3.1 060. 기계 도시 250 3.1 061. 우주 도시 250 3.1 062. 화산지대 252 3.2 063. 실험실 262 3.3 064. 우주선 복도 253 3.2 065. 우주 정거장 251 3.1 066. 서버실 251 3.1 067. 상황실 251 3.1 068. 신전 258 3.2 069. 광산 259 3.2 070. 외계도시 257 3.2 071. 지하 도시 259 3.2 2. 시나리오 3. 인공적 시나리오 072.우주 공간 시나리오 250 3.1 073.우주선 탑승 시나리오 250 3.1 074.자연 재해 시나리오 253 3.2 075.인공 전쟁/전투 시나리오 264 3.3 076. 가상 전쟁/전투 시나리오 252 3.2 077. 위급 상황 관련 시나리오 254 3.2 078.건축 관련 소리 시나리오 289 3.6 079.음식 만드는 시나리오 251 3.1 080.실내 청소 시나리오 251 3.1 081. 샤워 관련 소리 시나리오 250 3.1 082. 자전거 탑승 시나리오 250 3.1 083. 버스 탑승 시나리오 258 3.2 084. 차량 탑승 시나리오 258 3.2 085. 오토바이 탑승 시나리오 251 3.1 086.비행기 탑승 시나리오 292 3.7 087.헬리콥터 탑승 시나리오 293 3.7 088. 보트 탑승 시나리오 250 3.1 089. 유람선 탑승 시나리오 256 3.2 090. 기차 탑승 시나리오 256 3.2 091. 폭발 관련 시나리오 253 3.2 092.구강 발생 소리 시나리오 252 3.2 093. 손을 이용한 소리 시나리오 255 3.2 094. 발을 이용한 소리 시나리오 255 3.2 095. 그 외 신체 소리 시나리오 250 3.1 096. 동물/곤충 소리 시나리오 254 3.2 097. 바람 관련 소리 시나리오 251 3.1 098. 비 관련 소리 시나리오 264 3.3 099. 눈 관련 소리 시나리오 265 3.3 100. 천둥번개/우뢰 관련 소리 시나리오 267 3.3 101. 유리 관련 소리 시나리오 273 3.4 102. 호러/SF 장르 관련 소리 1 – 자르는 소리 268 3.4 103. 호러/SF 장르 관련 소리 2 – 부러지는 소리 262 3.3 104. 호러/SF 장르 관련 소리 3 – 괴물소리 273 3.4 105. 호러/SF 장르 관련 소리 4 – 비명 소리 265 3.3 106. 호러/SF 장르 관련 소리 5 – 음산한 소리 275 3.4 107. 카메라 촬영 관련 소리 시나리오 273 3.4 108. 쇠사슬 행위 관련 소리 시나리오 251 3.1 109. 제품 켜는 소리 시나리오 250 3.1 110. 엘리베이터 탑승 관련 시나리오 251 3.1 111. 문 관련 소리 시나리오 251 3.1 112. 시계 관련 소리 시나리오 251 3.1 113. 액체 관련 소리 시나리오 251 3.1 114. 컴퓨터 관련 소리 시나리오 253 3.2 115. 오래된 전화기 관련 소리 시나리오 251 3.1 116. 스마트폰 관련 소리 시나리오 251 3.1 117. 라디오 관련 소리 시나리오 253 3.2 118. 텔레비전 관련 소리 시나리오 250 3.1 119. 타자기 관련 소리 시나리오 252 3.2 120. 로봇 관련 소리 시나리오 250 3.1 121. 레이저 관련 소리 시나리오 250 3.1 총 수량 39,130 797.3 -
-
AI 모델 상세 설명서 다운로드
AI 모델 상세 설명서 다운로드 AI 모델 다운로드1. 모델 설명 1. 모델 설명 본 알고리즘은 오디오 시퀀스를 작은 조각들로 분리하고 일부를 누락하여 학습 시키는 패치아웃 방법을 트랜스포머에 도입하여 연산과 메모리 복잡도를 낮추었고, 트랜스포머의 위치 인코딩을 시간/주파수 위치 인코딩으로 분리하여 다양한 시간 입력에 대해 효과적으로 대응할 수 있다는 장점이 있음. 본 알고리즘은 이러한 방법론으로 학습 시간과 리소스를 효과적으로 줄이고 Audioset 데이터셋에 대해 SOTA 성능을 얻어냄. 모델의 학습 및 평가를 위해 수집된 데이터셋을 Train Set, Valid Set, Test Set 총 3개로 분할하였고 각각의 비율은 8:1:1로 설정하였음. 정확한 학습 및 평가를 위해 각 레이블 별로 동일한 비율의 분할을 진행하였으며 이들은 모두 무작위로 섞여 있음. 전체 데이터 데이터 분할 Train Valid Test 개수 (개) 39,130 31,380 3,875 3,875 백분율 (%) 80.1942 9.9029 9.9029 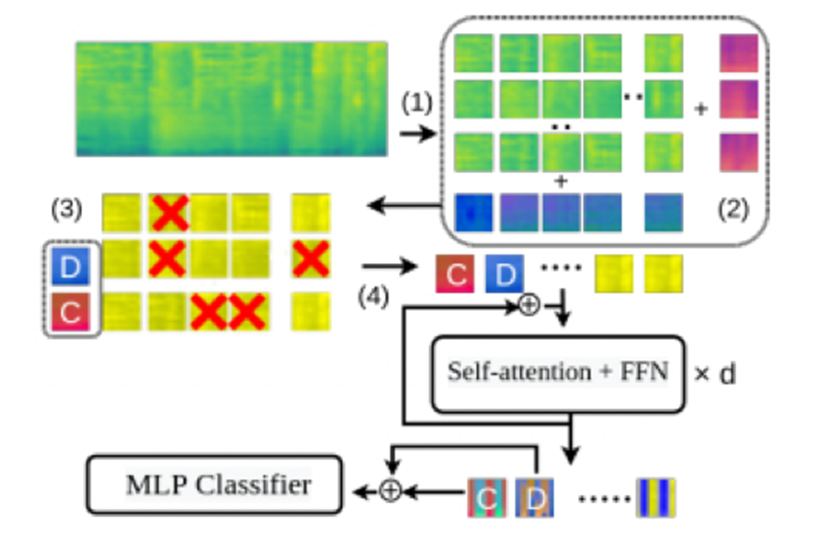
[그림 1] Patchout Fast Spectrogram Transformer (PaSST)
2. 데이터 전처리 1) 입력된 오디오 형식 길이 10초, 샘플링 레이트 32kHz의 오디오를 입력으로함. 기존 96kHz, 45초의 원본 오디오 파일을 32kHz로 다운샘플하고 앞의 10초를 잘라내어 사용함. 이는 참고 논문의 전처리 방식과 동일함. 입력 오디오는 멜스펙트로그램으로 변환되고 아래와 같이 여러 방식으로 데이터 증강이 이루어지는데, 모든 파라미터는 기존 논문의 구현 코드에서 Audioset 데이터셋에 대해 사용한 것과 동일한 값으로 설정됨. 멜스펙트로그램은 mel bin 128, window length 800, hop size 320, FFT number 1024의 파라미터로 변환됨. 2) 데이터 증강 아래와 같은 4가지 방식의 데이터 증강이 이루어짐. 2단계 믹스업 (Two-level Mix-up): 기존 논문들에서 믹스업 방법이 성능 향상에 효과적인 것이 검증되어, 본 논문에서는 최종 스펙트로그램 뿐 아니라 데이터 세트에서 원본 파형을 무작위로 섞어 데이터 증강함. Spec Augment: 최대 48개의 주파수 빈과 192개의 시간 프레임을 마스킹하여 새로운 데이터를 생성. Rollling: 시간이 지남에 따라 파형을 무작위로 롤링함. Random Gain: 오디오 파형을 곱하여 gain을 ±7 dB 변경. 3. 모델 학습 및 결과 1) 모델 학습 mAP 기준으로 최고의 성능을 보인 모델 구성은 다음과 같음. 총 1.7억개의 학습 파라미터를 가지며, 2개의 모델로 이루어져 있음. 스펙트로그램 상에서 2프레임 혹은 빈(bin)만큼의 중첩을 갖는 S14 모델과 중첩이 없는 S16 모델을 앙상블하여 결과 값을 얻음. 제공되는 모델 중 가장 큰 앙상블 모델은 총 9개의 모델을 활용하나, 이 경우 약 30GB 정도의 GPU 메모리를 필요로 함. 현재 서버의 GPU로는 3개 이상의 모델을 동시에 구동할 수 없어 2개의 모델을 활용한 ensemble_s16_14 모델을 채택하여 실험하였음. Audioset에 대하여 오디오 태깅 학습이 된 모델을 사전학습 모델로 사용함. 이는 참고 문헌에서 다른 데이터셋과 과제에 대해 추가 학습을 진행한 것과 같은 방식임. 2) 학습결과 mAP 0.6045 안정적으로 학습이 진행되었고, 목표 mAP 0.40을 상회하는 결과 성능을 기록함. 지난 실험의 mAP 결과와 비교하면 0.5531에서 0.6045로 약 0.0514 정도 상승하였음. 이러한 mAP의 상승은 레이블이 늘어나고 데이터셋 규모가 커지면서 보편적인 학습이 이루어진 결과로 보임. 그 근거로 혼동된 레이블의 비중이 줄어들어 혼동 행렬 상에서 대각선이 더 뚜렷하게 나타나는 것을 확인할 수 있음. 혼동된 레이블들은 가상 업무 공간 (49), 판타지 중세 성 (53), 우주 도시 (61), 우주선 복도 (63) 등 주로 추상적인 경우들임. 이러한 결과는 해당 레이블들이 가상적이거나 비일상적인 공간으로, 다른 레이블과 비교했을 때 배경음의 경우가 보다 더 다양할 수 있기 때문인 것으로 보임. 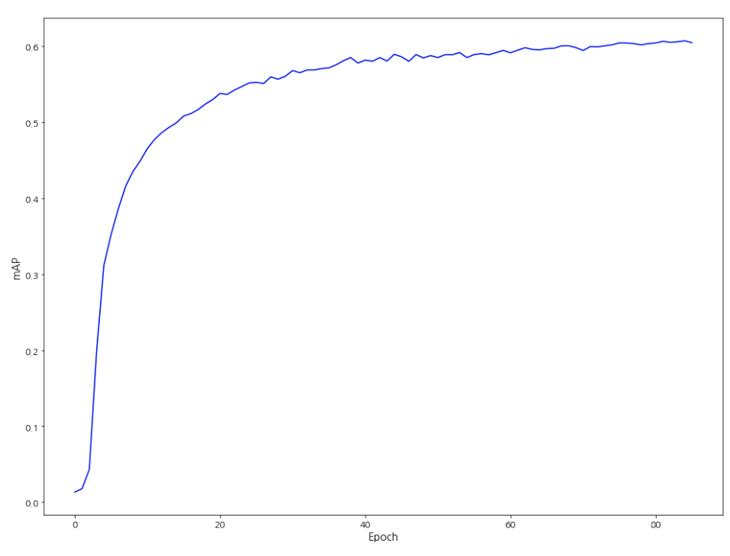
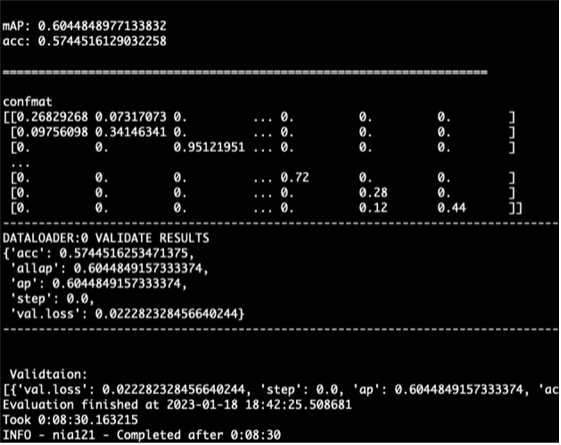
[그림 2] PaSST ensemble_s16_14 모델 학습 과정에 따른 mAP 값 [그림 3] 최종 mAP 60.4% 기록 -
데이터 성능 점수
측정값 (%)기준값 (%)데이터 성능 지표
데이터 성능 지표 번호 측정항목 AI TASK 학습모델 지표명 기준값 점수 측정값 점수 1 음향 분류 성능 Audio Classification PaSST mAP 50 % 60.45 %
※ 데이터 성능 지표가 여러 개일 경우 각 항목을 클릭하면 해당 지표의 값이 그래프에 표기됩니다.
※ AI모델 평가 지표에 따라 측정값의 범위, 판단 기준이 달라질 수 있습니다. (ex. 오류율의 경우, 낮을수록 좋은 성능을 내는 것으로 평가됩니다)
-
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드1. 데이터 기본 구성
1. 데이터 기본 구성 대분류 2. 시나리오 중분류 3. 인공적 시나리오 소분류 78. 건축 관련 소리 시나리오 원시데이터 
원천데이터 
*필드레코딩 방식 데이터의 경우 100초, 폴리/합성 방식 데이터의 경우 45초에 알맞게 적합한 구간 추출 2. 라벨링 데이터 구성
2. 라벨링 데이터 구성 구분 속성명 타입 필수여부 설명 범위 비고 1 분류 정보 파일 분류 정보 1-1 소분류 string y 소분류 이름 1-2 중분류 string y 중분류 이름 1-3 대분류 string y 대분류 이름 1-4 소분류 번호 number y 소분류 번호 1~121 1-5 중분류 번호 number y 중분류 번호 1~4 1-6 대분류 번호 number y 대분류 번호 1~2 1-7 녹음 방법 string y 녹음 방법 분류 폴리 + 합성 or 폴리 사운드 레코딩 or 필드 레코딩 or 합성 음향 2 파일 정보 오디오 파일 기본 정보 2-1 파일 이름 string y 파일 이름 2-2 샘플링 레이트 number y 오디오 녹음 샘플링 레이트 96000 2-3 채널 수 number y 오디오 채널 수 2ch 2-4 Bit Depth number y 오디오 녹음 Bit Depth 24bit 2-5 길이 number y 오디오 녹음 길이 100초 or 45초 3 오디오 이벤트 태그 list of string y 오디오 이벤트 태그 정보 태그 리스트 참조 4 오디오 음향 특성 원시 데이터 라벨 정보 4-1 spectral centroid mean number y Spectral centroid 평균 4-2 spectral centroid std number y Spectral centroid 표준편차 4-3 spectral bandwidth mean number y Spectral bandwidth 평균 4-4 spectral bandwidth std number y Spectral bandwidth 표준편차 4-5 spectral constrast mean number y Spectral contrast 평균 4-6 spectral constrast std number y Spectral contrast 표준편차 4-7 spectral roll off mean number y Spectral roll off 평균 4-8 spectral roll off std number y Spectral roll off 표준편차 4-9 spectral flatness mean number y Spectral flatness 평균 4-10 spectral flatness std number y Spectral flatness 표준편차 4-11 zero crossing rate mean number y Zero crossing rate 평균 4-12 zero crossing rate std number y Zero crossing rate 표준편차 4-13 rms mean number y RMS 게인 평균 4-14 rms std number y RMS 게인 표준편차 5 녹음 상세 정보 5-1 제목 string y 녹음 상황 묘사 5-2 녹음/제작 연/월/일 string y 녹음 시간 5-3 사용 기자재 string y 사용 기자재 5-4 녹음 장소 string n 필드 레코딩 녹음 장소 5-5 녹음 지점 string n 필드 레코딩 녹음 위도 경도 5-6 기후 등 환경 조건 string n 필드 레코딩 기후 환경 조건 5-7 기타 특이사항 string n 필드 레코딩 특이사항 3. 라벨링 데이터 예시
3. 라벨링 데이터 예시 {
"분류 정보": {
"소분류": "건축 관련 소리 시나리오",
"중분류": "인공적 시나리오",
"대분류": "시나리오",
"소분류 번호": 78,
"중분류 번호": 3,
"대분류 번호": 2,
"녹음 방식": "폴리 + 합성"
},
"파일 정보": {
"파일 이름": "fs-2-3-078-025.wav",
"샘플링 레이트": 96000,
"채널 수": 2,
"Bit Depth": 24,
"길이": 45.0
},
"오디오 이벤트 태그": ["공회전", "기계장치", "드릴","망치", "버스", "윙윙(기계)", "자동차", "전동 공구", "차량", "파열", "후진 경고음"
],
"오디오 음향 특성": {
"spectral centroid mean": 3203.9063659473436,
"spectral centroid std": 1082.3263759196393,
"spectral bandwidth mean": 3388.9515045478106,
"spectral bandwidth std": 424.7942201832163,
"spectral contrast mean": 17.771037737945232,
"spectral contrast std": 19.788107633977933,
"spectral roll off mean": 6705.4415293908505,
"spectral roll off std": 1594.8464852784773,
"spectral flatness mean": 0.002538747154176235,
"spectral flatness std": 0.04953843727707863,
"zero crossing rate mean": 0.04103165414271747,
"zero crossing rate std": 0.024747950363958392,
"rms mean": 0.06677260830804682,
"rms std": 0.02152401705274489
},
"녹음 상세 정보": {
"제목": "건설 현장 외부음",
"녹음/제작 연/월/일": "2022.07.14",
"사용 기자재": "Cubase DAW",
}
} -
데이터셋 구축 담당자
수행기관(주관) : 뉴튠(주)
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 박승순 0507-1328-0610 seungsoonpark@neutune.com 사업 운영 및 관리(데이터 수집, 정제, 검사) 등 수행기관(참여)
수행기관(참여) 기관명 담당업무 서강대학교 산학협력단 데이터 라벨링, 저작도구 개발 등 한국과학기술원 AI 학습모델, 활용 서비스 프로토타입 개발 등 데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 박승순 0507-1328-0610 seungsoonpark@neutune.com
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기] [공용IRB 심의신청 가이드라인]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 safezone1@aihub.kr 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.
오프라인 데이터 이용 안내
본 데이터는 K-ICT 빅데이터센터에서도 이용하실 수 있습니다.
다양한 데이터(미개방 데이터 포함)를 분석할 수 있는 오프라인 분석공간을 제공하고 있습니다.
데이터 안심구역 이용절차 및 신청은 K-ICT빅데이터센터 홈페이지를 참고하시기 바랍니다.

국방데이터 개방 안내
본 데이터는 국방데이터로 군사 보안에 따라 AI허브에서 데이터를 제공하지 않으며,
군 담당자를 통한 별도의 사용 신청이 필요합니다.