대규모 웹데이터 기반 한국어 말뭉치 데이터
- 분야한국어
- 유형 텍스트
-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.0 2022-07-12 데이터 최초 개방 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2025-06-16 구축업체 정보수정 2024-06-21 산출물 추가 등록 저작도구 2023-12-04 AI 모델 등록 2022-07-12 콘텐츠 최초 등록 소개
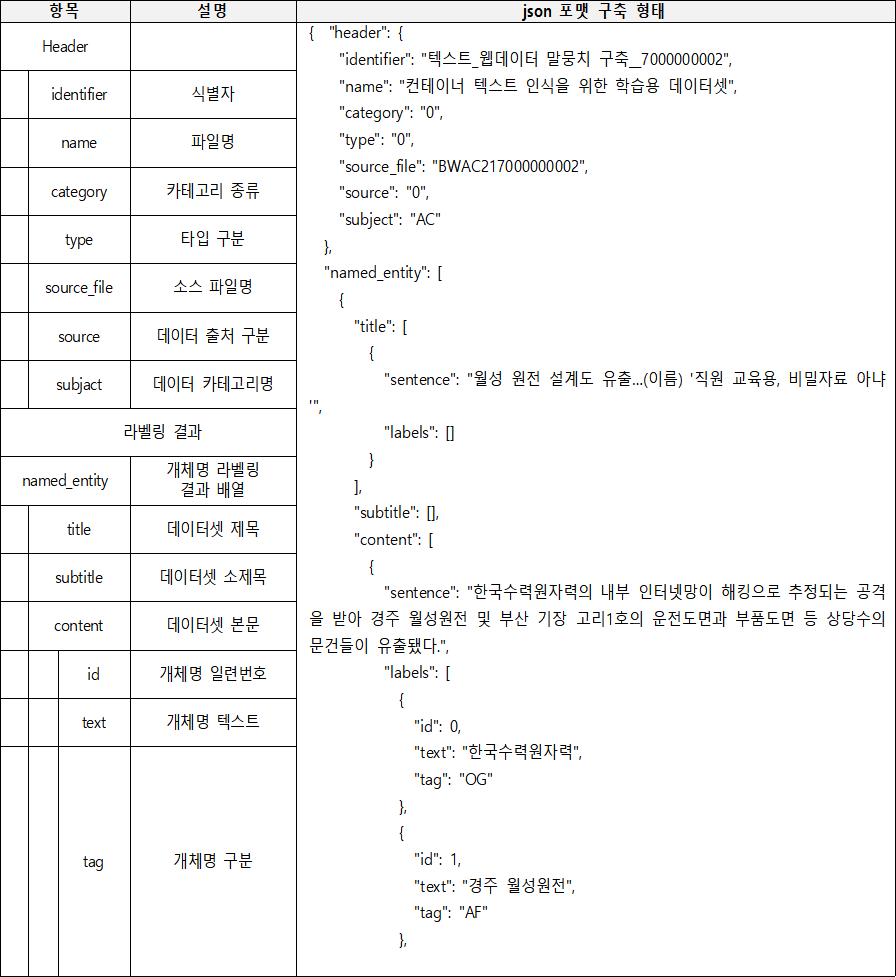
웹사이트 기반 (메가뉴스) 대용량의 텍스트 데이터를 수집 후 전사 도구를 활용하여 타이틀, 단락 제목, 본문 텍스트가 구조화된 10억 어절의 말뭉치 요소별(범용용어 및 고유명사) AI 학습 데이터셋
구축목적
AI 학습용 데이터로서의 대용량 텍스트 데이터가 필요하나, 현재 웹 기반의 다양한 한국어 말뭉치 데이터가 부족하여 10억 어절 이상의 웹 데이터 기반 한국어 말뭉치 데이터를 구축
-
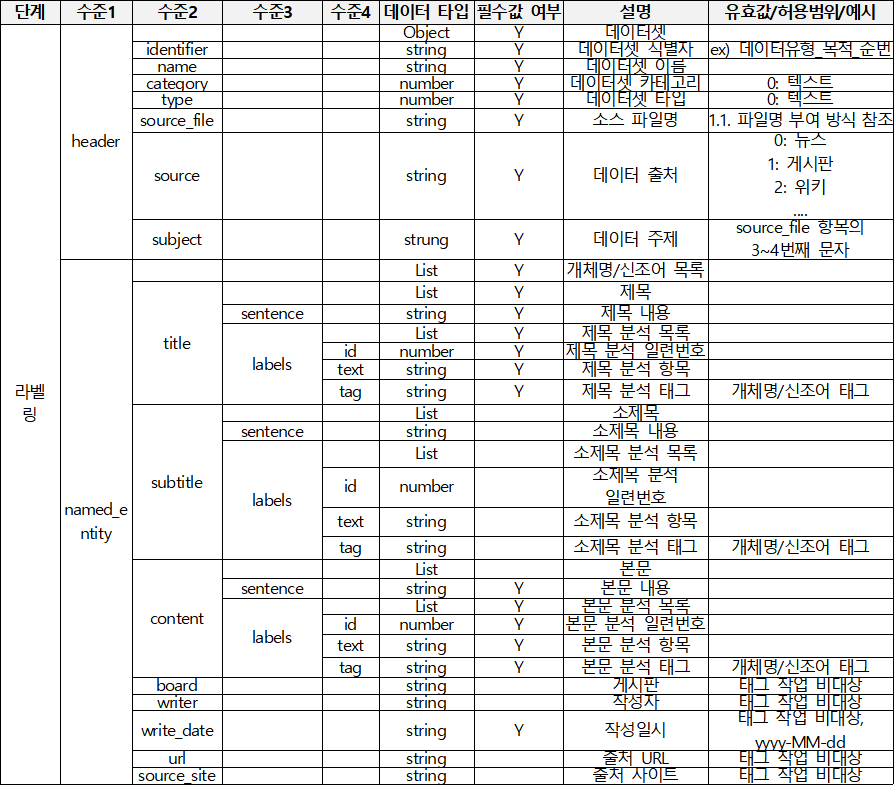
메타데이터 구조표 데이터 영역 한국어 데이터 유형 텍스트 데이터 형식 txt 데이터 출처 언론기사 라벨링 유형 텍스트 라벨링 형식 JSON 데이터 활용 서비스 대규모 한국어 서비스, 한국어 문법 교정기 고도화, 한국어 문서 핵심 요약 서비스, 신조어 이해 사전 서비스 고도화 등에 활용 데이터 구축년도/
데이터 구축량2021년/10억 어절 -
1. 데이터 구축 규모
- 원천 데이터
– 원시데이터(웹데이터)로부터 비문, 비속어, 편향성, 비식별화 등 정제된 JSON 구조의 텍스트 데이터 10억 어절 이상 - 라벨링 데이터
– 원천데이터로부터 JSON구조의 구문에 맞게 개체명과 신조어에 대하여 태깅된 텍스트 데이터 10억 어절 이상
2. 데이터 분포
- 출처별 분포
2. 데이터 분포 출처별 분포 No. 항목명 비율 1 뉴스1 34.8% 2 뉴시스 24.3% 3 머니투데이뉴스 18.6% 4 머니S 9.8% 5 스타뉴스 8.7% 6 지디넷 1.9% 7 더리더 1.3% 8 코스모폴리탄 0.2% 9 엘르 0.2% 10 디스이즈게임 0.2% 11 하퍼스 바자 0.1% 합계 100.0% 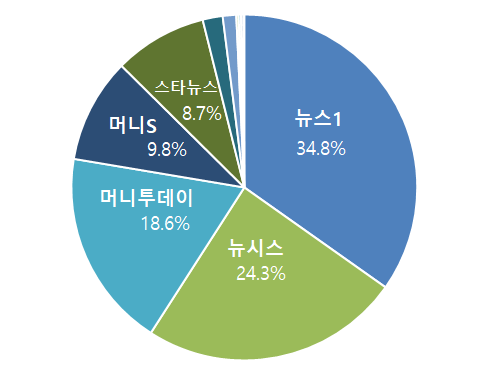
[출처별 분포 그래프]
- 카테고리별 분포
2. 데이터 분포 카테고리별 분포 No. 분류코드 분류명 파일수 어절 수 비율 1 SC IT/과학 1,535 41,970,255 3.6% 2 CU 문화/패션/뷰티 2,280 44,853,911 3.8% 3 IN 국제 2,752 49,390,134 4.2% 4 WO 여성복지 3,420 49,970,850 4.3% 5 ED 교육 3,371 57,060,422 4.9% 6 LC 지역 3,962 57,954,012 4.9% 7 LI 라이프스타일 3,732 62,600,032 5.3% 8 SP 스포츠 3,178 62,942,643 5.4% 9 AC 사건사고 3,562 65,350,073 5.6% 10 HE 건강 4,403 68,648,804 5.8% 11 HB 취미 3,672 70,524,485 6.0% 12 SG 사회일반 4,501 74,946,093 6.4% 13 TL 여행레저 4,063 79,220,922 6.7% 14 PO 정치 4,153 93,955,104 8.0% 15 EC 경제 6,140 97,426,330 8.3% 16 EN 연예 5,996 98,190,180 8.4% 17 ID 산업 5,031 100,459,770 8.5% 합계 65,751 1,175,464,020 100.0% 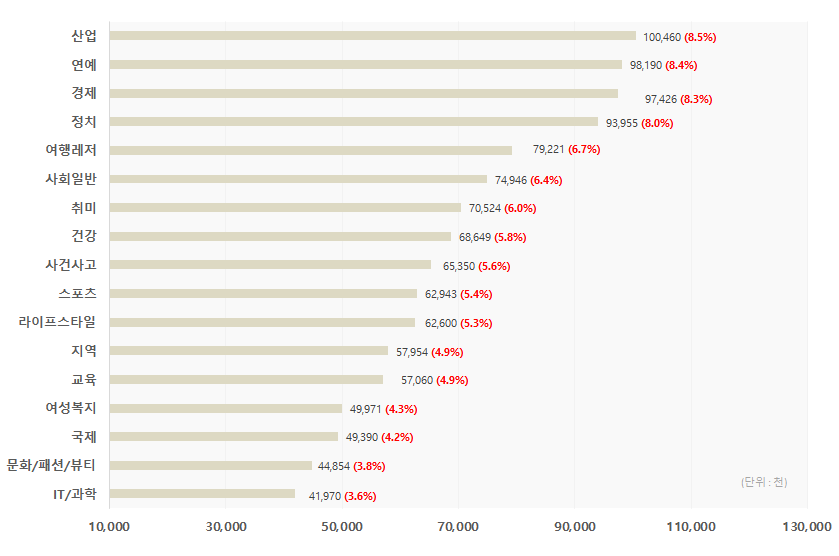
[카테고리별 어절 분포 그래프]
- 원천 데이터
-
-
AI 모델 상세 설명서 다운로드
AI 모델 다운로드1. 모델학습
- 한국어 언어모델 생성 AI 모델링
- ELECTRA 언어모델 학습 방법을 이용한 언어모델 구축
- Masked Language Model(MLM)과 Replaced Token Prediction(RTP)을 학습 목표를 향한 언어 모델 학습
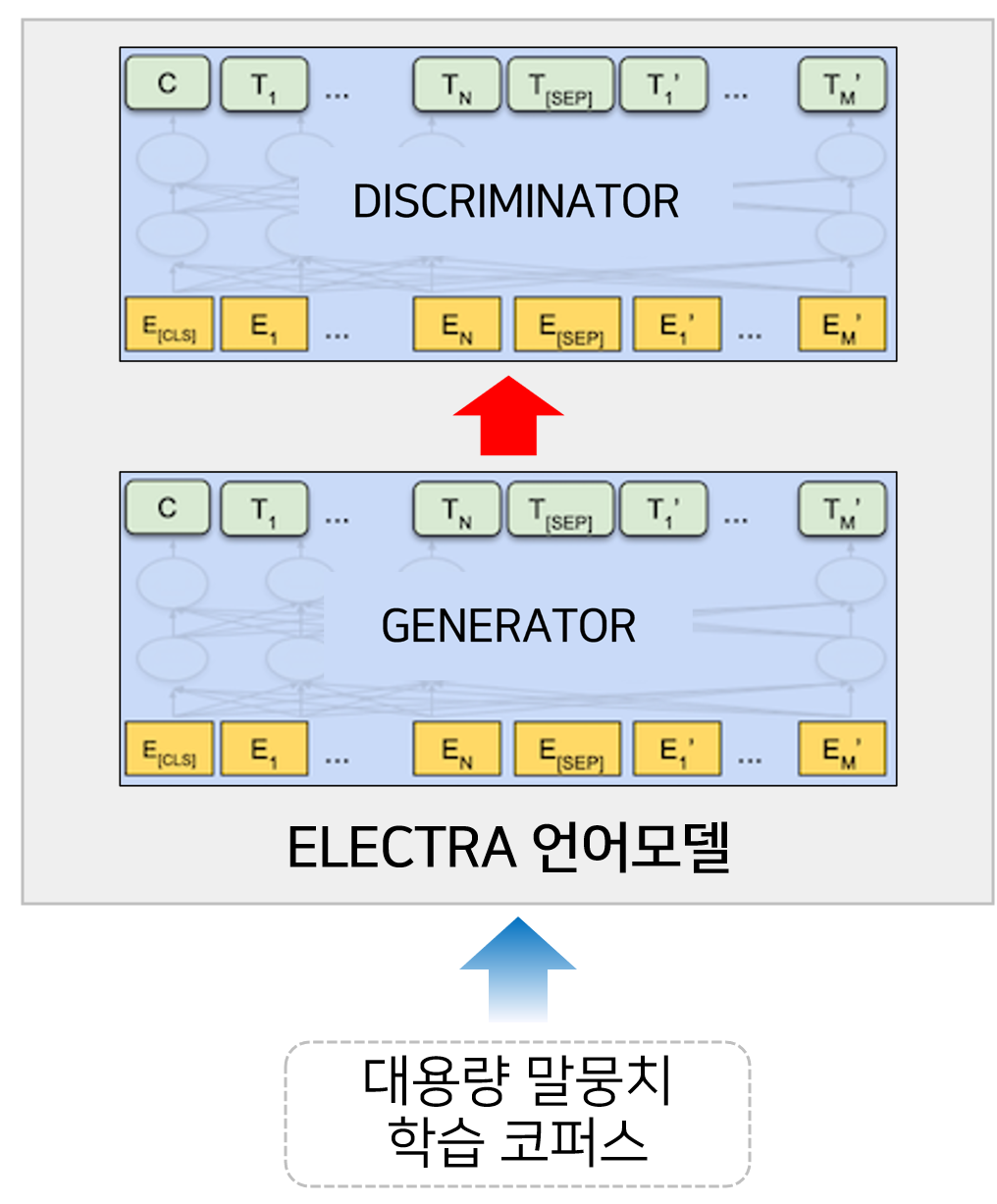
- 한국어 파인튜닝 모델 생성 AI 모델링
- 생성된 언어모델을 활용한 한국어 Downstream Task에 대한 파인튜닝학습 모델 생성
- 한국어 파인튜닝학습모델을 만들기 위해서 KLUEBenchmark의 NER, NLI, RE, STS와 KorQuad1.0에서 테스트
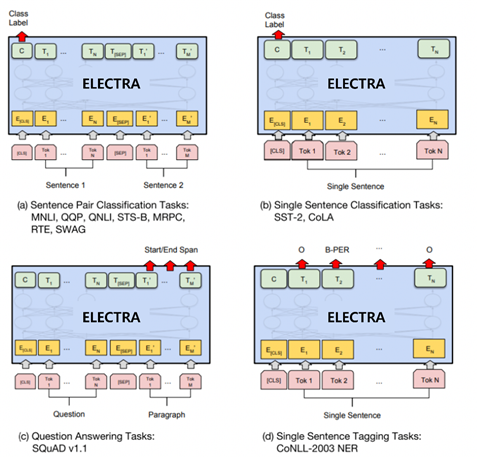
2. 서비스 시나리오
- 학습을 완료한 모델은 기계 독해, 문장 분류, 감성 분석, 개체명 인식, 자연어 추론 등의 다양한 자연어 이해 문제를 해결할 수 있음.
- 이에 따라서 텍스트로 구성된 데이터가 주어진다면, 텍스트를 이용한 다양한 종류의 자연어 처리 서비스 만들 수 있음.
- 한국어 언어모델 생성 AI 모델링
-
데이터 성능 점수
측정값 (%)기준값 (%)데이터 성능 지표
데이터 성능 지표 번호 측정항목 AI TASK 학습모델 지표명 기준값 점수 측정값 점수 1 의미적 유사성 (KLUE-STS) Estimation Transformer 기반 (BERT, ELECTRA 등) F1-Score 점 0.8117 점 2 자연어 추론 (KLUE-NLI) Estimation Transformer 기반 (BERT, ELECTRA 등) F1-Score 점 0.7598 점 3 개체명 인식 (KLUE-NER) Text Classfication Transformer 기반 (BERT, ELECTRA 등) F1-Score 점 0.8985 점 4 관계 추출 (KLUE-RE) Information Extraction Transformer 기반 (BERT, ELECTRA 등) F1-Score 점 0.6258 점 5 기계 독해 (KoQuAD 1.0) Machine Translation Transformer 기반 (BERT, ELECTRA 등) F1-Score 점 0.8972 점 6 주제 분류 (KLUE-TC) Text Classification Transformer 기반 (BERT, ELECTRA 등) F1-Score 점 0.8254 점
※ 데이터 성능 지표가 여러 개일 경우 각 항목을 클릭하면 해당 지표의 값이 그래프에 표기됩니다.
※ AI모델 평가 지표에 따라 측정값의 범위, 판단 기준이 달라질 수 있습니다. (ex. 오류율의 경우, 낮을수록 좋은 성능을 내는 것으로 평가됩니다)
-
데이터셋 구축 담당자
수행기관(주관) : 솔트룩스
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 김영혁 02-2193-1600 alex.kim@saltlux.com · 컨소시엄 총괄 및 관리 · 데이터셋 설계 · 데이터 정제(비식별화) 및 검수 · 저작도구 개발 및 학습모델 구현 · 경진대회 개최 수행기관(참여)
수행기관(참여) 기관명 담당업무 알토비전 · 데이터 수집 및 정제
· 데이터 저작권 계약, 데이터 수집 및 표준 설계
· 비속어, 비방글, 비문 등 삭제, 원천데이터 파일 생성비플라이소프트 · 1차 데이터 검수 이노그루 · 데이터 가공
· 크라우드 워커 모집
· 저작도구 활용 데이터 가공오픈큐비트 · 데이터 가공
· 크라우드 워커 모집
· 저작도구 활용 데이터 가공알체라 · 데이터 교차 검수 소리자바 · 데이터 교차 검수 데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 김영혁 02-2193-1600 alex.kim@saltlux.com


-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기] [공용IRB 심의신청 가이드라인]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 safezone1@aihub.kr 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.
오프라인 데이터 이용 안내
본 데이터는 K-ICT 빅데이터센터에서도 이용하실 수 있습니다.
다양한 데이터(미개방 데이터 포함)를 분석할 수 있는 오프라인 분석공간을 제공하고 있습니다.
데이터 안심구역 이용절차 및 신청은 K-ICT빅데이터센터 홈페이지를 참고하시기 바랍니다.

국방데이터 개방 안내
본 데이터는 국방데이터로 군사 보안에 따라 AI허브에서 데이터를 제공하지 않으며,
군 담당자를 통한 별도의 사용 신청이 필요합니다.