※온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.0 2022-07-13 데이터 최초 개방 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2023-01-09 안심존 온라인으로 수정 2022-07-13 콘텐츠 최초 등록 소개
당뇨병의 임상정보, 추적관찰 데이터와 라이프로그 데이터, 경동맥 초음파 영상 이미지를 포함한 인공지능 학습용 데이터셋 (의료 지식 베이스)
구축목적
인공지능을 탑재 또는 응용한 의료 융합 서비스에서 해당 인공지능이 “당뇨병 진료 기록 추적을 통한 효과적인 진료 및 지속적인 당뇨병 환자의 관리”에서 효과적으로 그 기능을 갖고 의사의 치료 활동에 적절한 서포트 및 지원을 할 수 있는 기능을 범용적인 수준에서 일정 수준 이상을 확보할 수 있도록 의미 있는 인공지능 학습 데이터가 될 수 있도록 함.
-
메타데이터 구조표 데이터 영역 헬스케어 데이터 유형 텍스트 , 이미지 데이터 형식 txt, png 데이터 출처 경희대학교병원 / 강동경희대학교병원 / 가천대학교 길병원 / 닥터다이어리 라벨링 유형 바운딩 박스, 폴리라인, 폴리곤 라벨링 형식 json 데이터 활용 서비스 수요기관 연계 학술 연구, 수요기관 연계 디지털 헬스 솔루션 개발 데이터 구축년도/
데이터 구축량2021년/50,000 -
1. 데이터 구축 규모
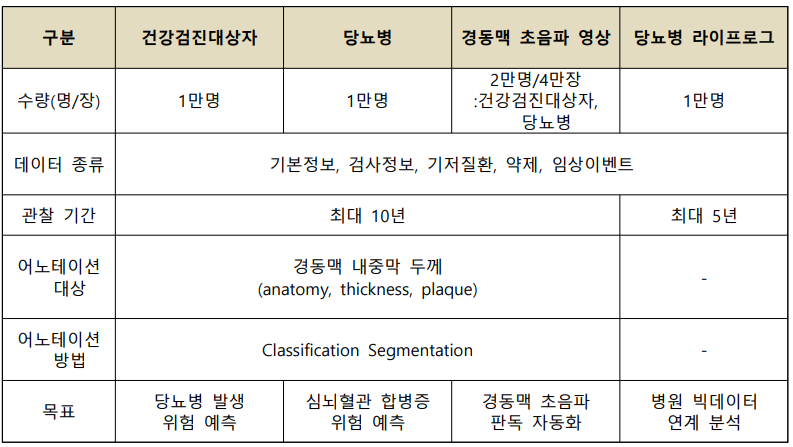
2. 데이터 분포
1. 데이터 구축 규모 데이터 종류 수량 출처 건강검진대상자/당뇨병 20,000건 경희대학교병원
강동경희대학교병원
가천대학교 길병원경동맥 초음파 영상 20,000건 경희대학교병원
강동경희대학교병원
가천대학교 길병원당뇨병 라이프 로그 10,000건 닥터다이어리 -
-
AI 모델 상세 설명서 다운로드
AI 모델 상세 설명서 다운로드 AI 모델 다운로드1. 초음파 경동맥 이미지 분할(Segmentation) 모델 개발
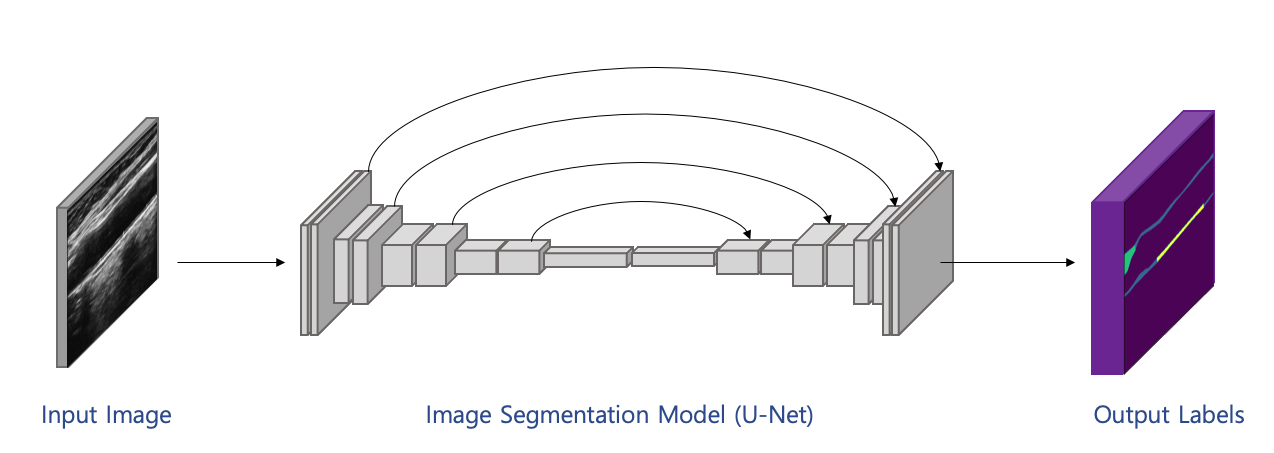
- 모델 개요: 초음파 경동맥 이미지(흑백)를 입력으로 받아 혈관, 내중막 두께 측정 부위, Plaque 영역 및 기타 영역으로 이미지를 분할(Segment)하는 모델
- 모델 알고리즘 및 구조:
- U-Net
구조를 기본으로 본 과제의 평가 지표에 맞게끔 Loss를 재설계하고 학습 스케쥴링 알고리즘 적용 - 입력 이미지:
각 픽셀이 [0, 255] 사이의 정수 값을 갖는 png 포맷의 흑백 이미지
데이터셋 내 모든 이미지의 크기가 제각각이므로 본 모델은 입력 이미지의 스케일 조정과 Center Crop을 이용하여 224x224 영역을 추출하여 입력으로 사용 - 출력 라벨:
입력 이미지와 동일하게 스케일 조정 및 Crop된 영역에 대해 아래와 같이 클래스별 라벨 부여
1) 배경 영역: 0
2) 혈관벽 영역: 1
3) Plaque 영역: 2
4) 내중막 두께 측정 영역: 3 - 모델 구조 세부 내용:
U-Net의 기본 구조는 입력 이미지 이후 병목 구조에 도달할 때까지 layer 별 feature의 숫자를 2배씩 늘리고, 대신 layer 출력 영역 넓이를 줄이는 방식으로 구성
본 과제에서는 초도 layer의 feature 개수를 64로 고정한 후 병목 지점까지 총 4개의 down sampling component를 사용하고, 이 후 총 4개의 Up-sampling component를 사용
단, 코드 내 초도 layer의 feature 개수를 변경할 수 있도록 입력 변수를 별도로 제공 (‘-nf’ 인자) - 입/출력 이미지 Transformation:
부족한 데이터를 보강하고, 제각기 다른 입력 이미지 사이즈에 대응하기 위해 학습과 평가(test)에서 각각 아래와 같은 data augmentation 수행
1) 학습: 임의의 한 이미지를 단축 기준 300픽셀로 rescaling하고 상하좌우 및 중앙 등 총 5개의 224x224 이미지를 Crop, 이 후 이를 좌우 반전하여 총 10장의 입력 이미지 생성
2) 평가: 학습과 동일한 Transformation을 진행하되 좌우 반전을 취하지 않고 5장만 생성
(* 모델 평가 시에는 생성된 5장의 이미지 각각에 대해 f1-score 측정하여 전체 성능 수치에 반영) - Loss 설계:
본 과제에서는 U-Net에서 통상적으로 많이 사용되는 Dice score를 사용하지 않고 다음 두 가지 loss를 사용
1) f1-score approximation의 inverse: 본 과제 평가 목표가 f1-score인 것을 반영. 정확한 f1-score의 산식은 미분가능하지 않기 때문에, 이를 relax한 loss를 별도로 정의하여 사용하였으며, 아래의 cross-entorpy loss와 병행하여 사용하기 위해 1에서 f1-score를 차감한 값을 loss로 사용하였음
2) Cross-entropy loss: f1-score loss만으로는 모델 학습 파라미터의 수렴이 느린점을 보완하기위해 multi-class classification 문제에서 많이 사용되는 Cross-entropy loss를 사용하였음
학습이 어느 정도 진행된 이후에는 두 loss 간 scale의 차이가 크지 않으므로 단순 합산하여 최종 loss로 사용함
클래스 간 데이터 불균형을 해소하기 위해 아래와 같이 클래스별 가중치 부여
1) 배경 영역: 0.3
2) 혈관벽 영역: 1.0
3) Plaque 영역: 2.0
4) 내중막 두께 측정 영역: 1.0
- U-Net
- 권장 학습 분배량: 학습 : 검증 : 평가 = 8 : 1: 1
- 데이터 분배 및 학습 적용 방법:
- 학습/검증/평가 데이터셋 내 plaque 존재 이미지 비율을 일정하게 유지할 수 있도록 발병 여부를 기준으로 stratified random split을 적용
- 본 모델과 함께 사용될 내중막 두께 예측 모델을 위해 구축 데이터 중 IMT(내중막 두께) 값이 어노테이션 된 데이터만을 학습/검증/평가에 활용
- 단, 위 과정을 거치면서 아래 두 가지 사유로 전체적인 데이터 비율이 손상되므로 이를 수동으로 보정
1) (모든 환자에 대해 좌/우 이미지 pair가 존재하는 데이터 특성 상) 한쪽 이미지에는 plaque가 존재하나 반대쪽 이미지에는 plaque가 존재하지 않는 경우
2) 한쪽 이미지에는 IMT 값이 어노테이션 되어 있으나 반대쪽에는 어노테이션 되지 않은 경우 - 보정된 데이터셋에 대해 각각의 환자 ID(=CDMID) 리스트를 아래 파일로 제공
1) cdmid_train.csv: 학습에 사용되는 환자 CDMID 리스트
2) cdmid_validation.csv: 검증에 사용되는 환자 CDMID 리스트
3) cdmid_test.csv: 평가에 사용되는 환자 CDMID 리스트
- 모델 학습 환경:
- 운영체제: Ubuntu 20.04.3 LTS
- CPU: Intel(R) Xeon(R) Gold 6326 CPU @ 2.90GHz x 64ea (총 64 core)
- Memory: DDR4 2TB RAM
- GPU: NVIDIA A100 x 1개
- 개발 언어: Python 3.8.12
- 사용 프레임워크: CUDA 11.5, PyTorch 1.11.0, OpenCV-python 4.5.4.60
- 라이브러리 상세 정보: 코드 내 ‘environment.yaml’ 파일 참고
- 모델 학습 파라미터:
- epoch: 10
- batch-size: 24
- learning-rate: 1.0e-5
- num-features: 64
- 모델 성능 목표 및 결과:
- 목표: f1-score 0.8 이상
- 결과: f1-score 0.826
2. 경동맥 내중막 두께 예측 모델 개발
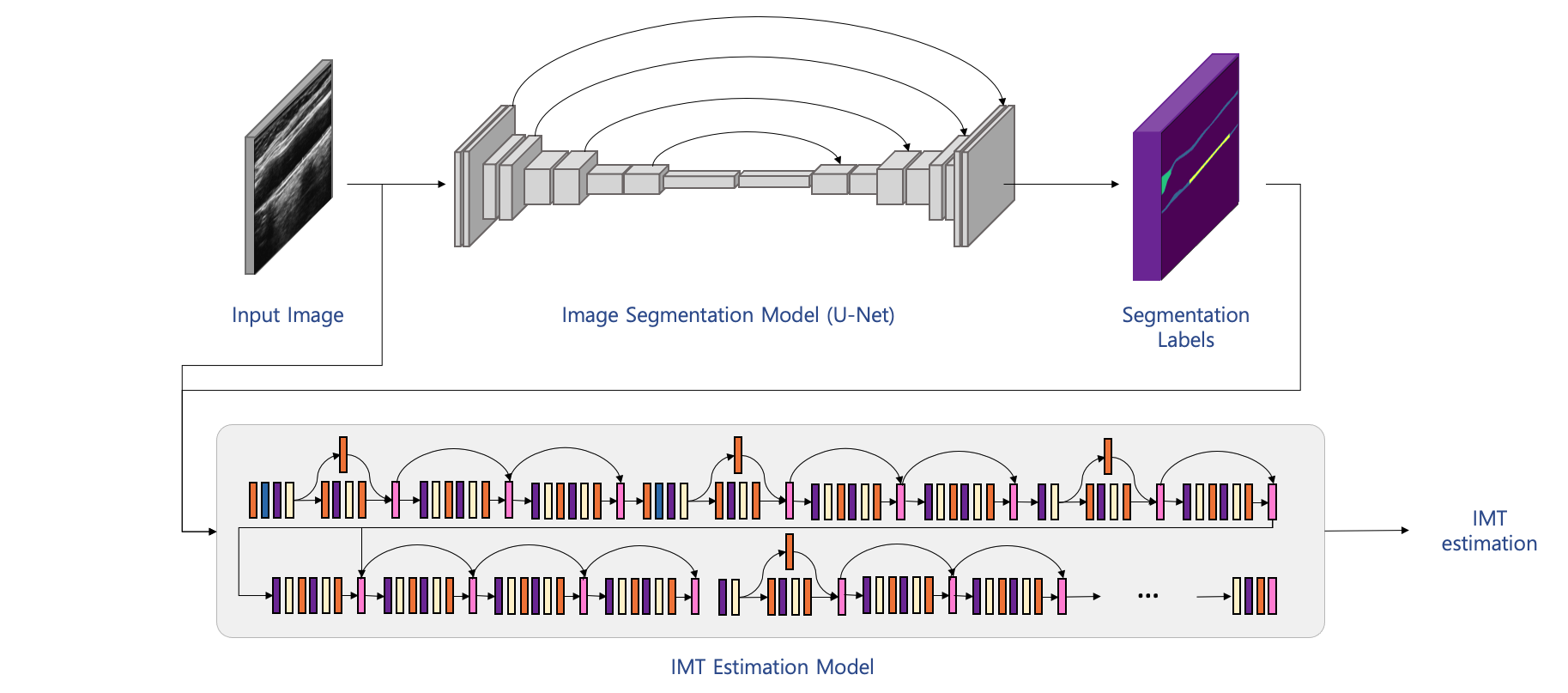
- 모델 개요: 초음파 경동맥 이미지를 입력으로 받아 내중막 두께(단위: mm)를 예측하는 모델
- 모델 알고리즘 및 구조:
- 초음파 경동맥 이미지와 더불어 ‘초음파 경동맥 이미지 분할 모델’을 이용하여 생성한 영역 라벨을 입력으로 받는 Wide Residual Net를 통해 내중막 두께(IMT) 예측
- 입력 이미지:
각 픽셀이 [0, 255] 사이의 정수 값을 갖는 png 포맷의 흑백 이미지
데이터셋 내 모든 이미지의 크기가 제각각이므로 본 모델은 입력 이미지의 스케일 조정과 Center Crop을 이용하여 224x224 영역을 추출하여 입력으로 사용 - 입력 라벨:
입력 이미지와 동일하게 스케일 조정 및 Crop된 영역에 대해 아래와 같이 클래스별 라벨 보유
1) 배경 영역: 0
2) 혈관벽 영역: 1
3) Plaque 영역: 2
4) 내중막 두께 측정 영역: 3 - 출력값:
내중막 두께에 대해 아래 값 예측 (단위: mm)
1) 내중막 두께 중 최대값
2) 내중막 두께 평균값 - 모델 구조 세부 내용:
전체 모델은 U-Net -> Wide Residual Net 으로 이루어짐
U-Net: 경동맥 초음파 영역 분할 라벨을 얻기 위한 U-Net은 ‘경동맥 초음파 이미지 분할 모델’과 동일 구조
Wide ResNet: 입력단부터 시작하여 아래와 같은 component 및 layer 구조를 가짐 (각 Block에 대한 상세 내용은 코드 참고)
1) Block 1:
- Convolutional layer: 커널크기=3x3, feature개수=64, Stride=1
2) Block 2:
- Residual Block: feature개수=8, 출력채널수=16, Max Pooling
- Residual Block: feature개수=16, 출력채널수=16
- Residual Block: feature개수=16, 출력채널수=16
3) Block 3:
- Residual Block: feature개수=16, 출력채널수=32, Max Pooling
- Residual Block: feature개수=32, 출력채널수=32
- Residual Block: feature개수=32, 출력채널수=32
4) Block 4:
- Residual Block: feature개수=32, 출력채널수=64, Down Sampling
- Residual Block: feature개수=64, 출력채널수=64
- Residual Block: feature개수=64, 출력채널수=64
- Residual Block: feature개수=64, 출력채널수=64
- Residual Block: feature개수=64, 출력채널수=64
5) Block 5:
- Residual Block: feature개수=64, 출력채널수=128, Down Sampling
- Residual Block: feature개수=128, 출력채널수=128
- Residual Block: feature개수=128, 출력채널수=128
6) Block 6:
- Bottleneck Block: feature개수=128, 출력채널수=256, Down Sampling
7) Block 7:
- Bottleneck Block: feature개수=256, 출력채널수=512
8) 출력 Block:
Batch Normalize -> ReLu Activation -> Average Pooling
-> Fully-connected Layer - 입/출력 이미지 Transformation:
부족한 데이터를 보강하고, 제각기 다른 입력 이미지 사이즈에 대응하기 위해 학습과 평가(test)에서 각각 아래와 같은 data augmentation 수행. - Loss 설계:
개발 목표 평가 지표인 Root-Mean-Square Error (RMSE)에 최적화하기 하면서 PyTorch의 기본 loss를 이용하기 위해 MSELoss 사용
해당 loss는 ‘내중막 두께 중 최대값’과 ‘내중막 두께 평균값’ 각각에 대한 MSE 값을 더한 값
- 권장 학습 분배량: 학습 : 검증 : 평가 = 8 : 1: 1
- 데이터 분배 및 학습 적용 방법: (경동맥 초음파 이미지 영역 분할 모델과 동일)
- 학습/검증/평가 데이터셋 내 plaque 존재 이미지 비율을 일정하게 유지할 수 있도록 발병 여부를 기준으로 stratified random split을 적용
- 본 모델과 함께 사용될 내중막 두께 예측 모델을 위해 구축 데이터 중 IMT(내중막 두께) 값이 어노테이션 된 데이터만을 학습/검증/평가에 활용
- 단, 위 과정을 거치면서 아래 두 가지 사유로 전체적인 데이터 비율이 손상되므로 이를 수동으로 보정
1) (모든 환자에 대해 좌/우 이미지 pair가 존재하는 데이터 특성 상) 한쪽 이미지에는 plaque가 존재하나 반대쪽 이미지에는 plaque가 존재하지 않는 경우
2) 한쪽 이미지에는 IMT 값이 어노테이션 되어 있으나 반대쪽에는 어노테이션 되지 않은 경우 - 보정된 데이터셋에 대해 각각의 환자 ID(=CDMID) 리스트를 아래 파일로 제공
1) cdmid_train.csv: 학습에 사용되는 환자 CDMID 리스트
2) cdmid_validation.csv: 검증에 사용되는 환자 CDMID 리스트
3) cdmid_test.csv: 평가에 사용되는 환자 CDMID 리스트 - 내중막 두께 예측 모델 학습 중 초음파 경동맥 이미지 영역 분할 모델의 파라미터들은 고정
- 모델 학습 환경:
- 운영체제: Ubuntu 20.04.3 LTS
- CPU: Intel(R) Xeon(R) Gold 6326 CPU @ 2.90GHz x 64ea (총 64 core)
- Memory: DDR4 2TB RAM
- GPU: NVIDIA A100 x 1개
- 개발 언어: Python 3.8.12
- 사용 프레임워크: CUDA 11.5, PyTorch 1.11.0, OpenCV-python 4.5.4.60
- 라이브러리 상세 정보: 코드 내 ‘environment.yaml’ 파일 참고
- 모델 학습 파라미터:
- epoch: 10
- batch-size: 60
- learning-rate: 1.0e-5
- num-features: 64
- 모델 성능 목표 및 결과:
- 목표: RMSE 0.15mm 이하
- 결과: IMT 최대값 RMSE = 0.139mm / IMT 평균값 RMSE = 0.088
3. 당뇨병 발병 예측 모델
- 모델 개요: Baseline 시점에서 당뇨병이 발병하지 않은 건강검진 수검자의 EHR 데이터를 활용하여 향후 당뇨병 발병 여부를 예측하는 모델
- 모델 알고리즘 및 구조: XGBoost Survival Embeddings (XGBSE) 모델 중 다음과 같은 구조로 구성된 XGBSEStackedWeibull 모델에 기반함
- XGBoost 부분: 전처리된 건강검진 EHR 데이터를 입력으로 하고, XGBoost 모델을 통해 당뇨병 발병 예측에 유용한 정보를 추출하여, 당뇨병 발병에 대한 위험 지표 출력
- Weibull AFT 부분: “XGBoost 부분”에서 산출된 위험 지표를 입력으로 하고, 생존분석 기반 Weibull AFT 통계 모델을 적용하여, 시점별 미발병(=‘생존’) 확률을 나타내는 생존곡선 출력
- Classification 부분: “Weibull AFT 부분”에서 얻은 미발병 확률을 이용하여 최종적으로 예측하고자 하는 시점의 당뇨병 발병 여부 예측
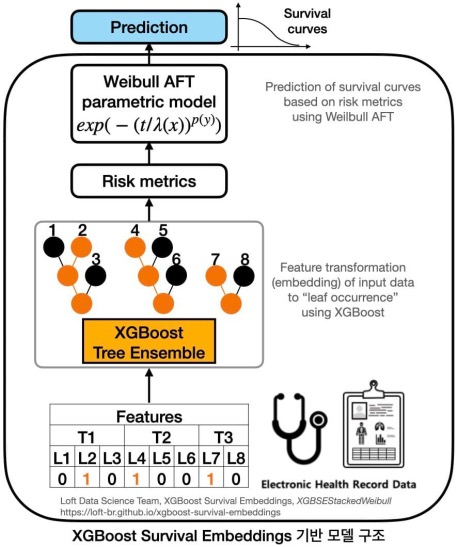
- 권장 학습 분배량: 학습 : 검증 : 평가 = 8 : 1: 1
- 데이터 분배 및 학습 적용 방법:
- 학습/검증/평가 데이터셋 내 미발병/발병 비율을 일정하게 유지할 수 있도록 발병 여부를 기준으로 stratified random split을 적용
- 결과 재현이 가능하도록 코드 내 random seed를 설정
- 이 외, split된 데이터셋에 대한 환자 ID(=CDMID) 리스트를 코드 내 제공
- 모델 학습 환경:
- CPU: Intel Xeon CPU E5-2630 v4(2.20GHz) x 2개 (총 20 core)
- Memory: 256GB RAM
- GPU: NVIDIA Tesla P40 x 8개
- 개발 언어: Python 3.7.11
- 사용 프레임워크: CUDA 11.1
- 라이브러리 상세 정보: 코드 내 ‘environment.yaml’ 파일 참고
- 모델 학습 파라미터:
- AFT loss distribution: Normal
- AFT loss distribution scale: 1.5
- Learning rate: 5e-2
- Max depth: 8
- 모델 성능 목표 및 결과:
- 목표: AUROC 0.8 이상
- 결과: AUROC 0.954
4. 당뇨 합병증 발병 예측 모델
- 모델 개요: Baseline 시점에서 합병증이 발병하지 않은 당뇨 환자의 EHR 시계열 데이터를 활용하여 향후 미세혈관 또는 대혈관 당뇨 합병증 발병 여부를 예측하는 모델이며 미세혈관과 대혈관 합병증 예측 모델은 전반적 구조는 동일하나 별도의 모델로 구성됨
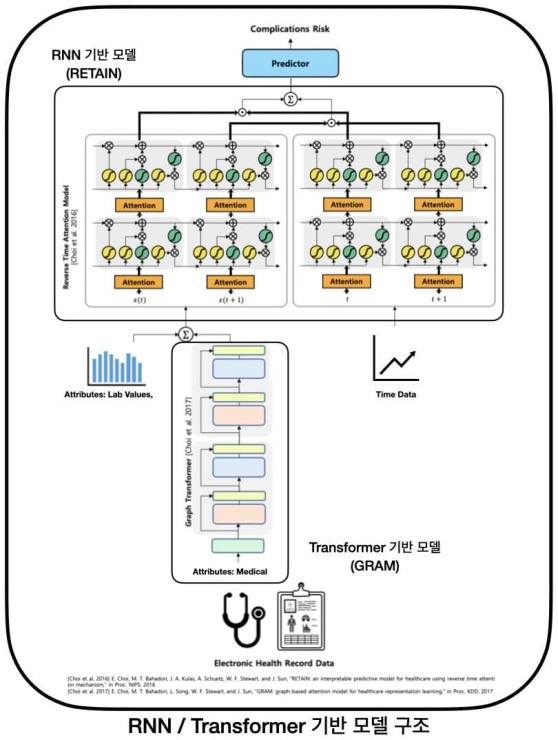
- 모델 알고리즘 및 구조: RETAIN 모델에 GRAM 모델을 결합한 모델로서 다음과 같은 구조로 구성
- GRAM 부분: 전처리된 건강검진 EHR 데이터를 입력으로 하고, XGBoost 모델을 통해 당뇨병 발병 예측에 유용한 정보를 추출하여, 당뇨병 발병에 대한 위험 지표 출력
- RETAIN 부분: EHR 데이터의 feature 정보뿐만 아니라 시간 정보를 함께 활용하는 모델임. 본 모델의 경우, 전처리된 당뇨 환자의 검진 EHR 데이터를 입력으로 하고, RETAIN 모델을 적용하여 얻은 가중치와 “GRAM 부분”에서 얻은 가중치를 함께 활용하여 미세혈관 또는 대혈관 당뇨 합병증 발병 여부와 관련된 예측치를 출력
- Classification 부분: “RETAIN 부분”에서 얻은 예측치를 이용하여 최종적으로 예측하고자 하는 시점의 미세혈관 또는 대혈관 당뇨 합병증 발병 여부를 예측
- 권장 학습 분배량: 학습 : 검증 : 평가 = 8 : 1: 1
- 데이터 분배 및 학습 적용 방법:
- Baseline 시점에서 특정 합병증이 이미 발병한 경우는 해당 합병증 예측에 활용하기 어려우므로, 미세혈관과 대혈관 합병증 각각에 활용 가능한 데이터셋을 별도로 구성함(즉, 미세혈관 합병증 예측의 경우 Baseline 시점에서 미세혈관 합병증이 발생하지 않은 데이터만 사용하고, 대혈관 합병증 예측의 경우 Baseline 시점에서 대혈관 합병증이 발생하지 않은 데이터만 사용하도록 구성함)
- 결과 재현이 가능하도록 코드 내 random seed를 설정
- 이 외, split된 데이터셋에 대한 환자 ID(=CDMID) 리스트를 코드 내 제공
- 모델 학습 환경:
- CPU: Intel Xeon CPU E5-2630 v4(2.20GHz) x 2개 (총 20 core)
- Memory: 256GB RAM
- GPU: NVIDIA Tesla P40 x 8개
- 개발 언어: Python 3.7.11
- 사용 프레임워크: CUDA 11.1 / PyTorch 1.10.0
- 라이브러리 상세 정보: 코드 내 ‘environment.yaml’ 파일 참고
- 모델 학습 파라미터:
- Epoch: 200
- Batch: 128
- Optimizer: AdamP
- Loss: Binary cross entropy
- 모델 성능 목표 및 결과:
- 목표: f1-score 0.7 이상
- 결과: f1-score 0.700
-
데이터 성능 점수
측정값 (%)기준값 (%)데이터 성능 지표
데이터 성능 지표 번호 측정항목 AI TASK 학습모델 지표명 기준값 점수 측정값 점수 1 당뇨병 발병 예측 모델 Prediction RNN, Transformer 기반 모델 AUC-ROC 0.8 단위없음 0.95 단위없음 2 경동맥이미지 Segmentation 모델 Segmentation grad-CAM, GAN F1-Score 0.8 점 0.82 점 3 당뇨병 합병증 발병 예측 모델 Prediction XGBoost F1-Score 0.7 점 0.7 점 4 IMT 측정 모델 Estimation CNN RMSE 0.15 mm 0.14 mm
※ 데이터 성능 지표가 여러 개일 경우 각 항목을 클릭하면 해당 지표의 값이 그래프에 표기됩니다.
※ AI모델 평가 지표에 따라 측정값의 범위, 판단 기준이 달라질 수 있습니다. (ex. 오류율의 경우, 낮을수록 좋은 성능을 내는 것으로 평가됩니다)
-
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드1. 소개
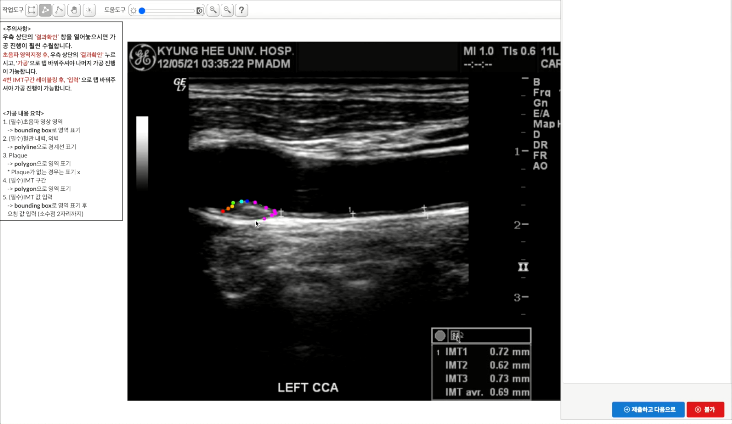
2. 대표도면
3. 라벨링데이터 구성
- 3-1 경동맥 초음파 영상 라벨 데이터
1. 소개 구분 항목명 타입 필수여부 설명 범위 비고 1 info Object M 데이터셋정보 1-1 description String M 데이터셋명 "Follow-up Data of Diabetes Mellitus and Complications AI Dataset" 1-2 year Number M 데이터 생성년도 2021 1-3 version String M 데이터 버전 1 1-4 contributor String M 데이터 제공기관 경희대학교
산학협력단2 images Object M 이미지정보 2-1 file_name String M 이미지파일명 2-2 file_format String M 이미지포맷 2-3 width Number M 이미지너비 [0~1920] 2-4 height Number M 이미지높이 [0~1080] 2-5 pt_id String M 환자식별자 2-6 date_created String M 촬영일자 yyyy.mm.dd 2-7 cca_dr String M 경동맥위치 2-8 gender String M 성별 M=Male, F=Female
U=Unknown2-9 age Number M 연령 [20~200] 2-10 data_cd Number M 데이터 분류 [1,0]
1:당뇨외래
0:건강검진2-11 is_plaque Number M Plaque 여부 [1,0] 2-12 is_stenosis Number M stenosis 여부 [1,0] 3 annotation Array of Object M 라벨링정보 [1,0] 3-1 id Number M 라벨링식별자 3-2 category_cd Number M 클래스코드 [1,2,3,4,5] 3-3 category_name String M 클래스명 [초음파 영상 영역, 혈관 외벽,혈관 내벽,Plaque,IMT 구간] 3-4 Type String M 라벨링텍스트 bbox, polyline,
segmentation3-5 coordinate Array C 좌표정보 Type이 segmentation과 Polyline일 경우 존재
[[[x1,y1],[x2,y2],...,[xn,yn]]]3-6 bbox Object C 바운딩박스 Type이 bbox일 경우 존재 3-6-1 x Number C(상위종속) 좌표정보 3-6-2 y Number C(상위종속) 좌표정보 3-6-3 width Number C상위종속) 좌표정보 3-6-4 height Number C(상위종속) 좌표정보 4 imt Object O imt 측정값 4-1 imt_max_value String O imt 최대값 4-2 imt_avg_value String O imt 평균값 5 category Array M 카테고리 코드표 Object 5-1 name String M 클래스명 5-2 value String M 클래스영문명 5-3 cd Number M 클래스코드 - 3-2 건강검진대상자 임상정보 데이터
구분 항목명 타입 필수여부 설명 범위 비고 1 info Object M 데이터셋정보 1-1 description String M 데이터셋명 "Follow-up Data of Diabetes Mellitus and Complications AI Dataset" 1-2 year String M 데이터 생성년도 2021 1-3 version String M 데이터 버전 1 1-4 contributor String M 데이터 제공기관 경희대학교
산학협력단2 pt_info Object M 환자기본정보 2-1 CDMID Number M 환자코드 8자리정수 2-2 gender String M 성별 M=Male, F=Female
U=Unknown2-3 age Number M 연령 [20~200] 3 date String M 검진기준일 yyyy.mm.dd 4 baseline_ci Object O baseline 기저임상정보 4-1 Ht Number O 신장 소수첫째자리까지
[100 ~ 250]4-2 Wt Number O 체중 소수첫째자리까지
[20 ~ 200]4-3 BMI Number O 체질량지수 소수첫째자리까지 4-4 SBP Number O 수축기혈압 정수
[30 ~ 300]4-5 DBP Number O 이완기혈압 정수
[30 ~ 300]4-6 PR Number O 맥박 정수
[10 ~ 300]4-7 HbA1c Number O 당화혈색소 소수첫째자리까지
[2 ~ 30]4-8 FBG Number O (공복)혈당 정수
[10 ~ 999]4-9 TC Number O 총콜레스테롤 정수
[10 ~ 999]4-10 TG Number O 중성지방 정수
[10 ~ 999]4-11 LDL Number O LDL 콜레스테롤 정수
[10 ~ 999]4-12 HDL Number O HDL 콜레스테롤 정수
[10 ~ 199]4-13 Alb Number O 알부민 소수첫째자리까지 4-14 BUN Number O 혈중요소질소 소수첫째자리까지
[0 ~ 200]4-15 Cr Number O 크레아티닌 소수둘째자리까지
[0 ~ 99.99]4-16 CrCl Number O 크레아티닌 청소율 소수둘째자리까지 4-17 AST Number O AST 정수
[0 ~ 999]4-18 ALT Number O ALT 정수
[0 ~ 999]4-19 GGT Number O GGT 정수
[0 ~ 999]4-20 ALP Number O ALP 정수
[0 ~ 999]5 date_E String M 검진기준일(End) yyyy.mm.dd 6 end_ci Object O End 기저임상정보 6-1 Ht_E Number O 신장 소수첫째자리까지
[100 ~ 250]6-2 Wt_E Number O 체중 소수첫째자리까지
[20 ~ 200]6-3 BMI_E Number O 체질량지수 소수첫째자리까지 6-4 SBP_E Number O 수축기혈압 정수
[30 ~ 300]6-5 DBP_E Number O 이완기혈압 정수
[30 ~ 300]6-6 PR_E Number O 맥박 정수
[10 ~ 300]6-7 HbA1c_E Number O 당화혈색소 소수첫째자리까지
[2 ~ 30]6-8 FBG_E Number O (공복)혈당 정수
[10 ~ 999]6-9 TC_E Number O 총콜레스테롤 정수
[10 ~ 999]6-10 TG_E Number O 중성지방 정수
[10 ~ 999]6-11 LDL_E Number O LDL 콜레스테롤 정수
[10 ~ 999]6-12 HDL_E Number O HDL 콜레스테롤 정수
[10 ~ 199]6-13 Alb_E Number O 알부민 소수첫째자리까지 6-14 BUN_E Number O 혈중요소질소 소수첫째자리까지
[0 ~ 200 ]6-15 Cr_E Number O 크레아티닌 소수둘째자리까지
[0 ~ 99.99]6-16 CrCl_E Number O 크레아티닌 청소율 소수둘째자리까지 6-17 AST_E Number O AST 정수
[0 ~ 999]6-18 ALT_E Number O ALT 정수
[0 ~ 999]6-19 GGT_E Number O GGT 정수
[0 ~ 999]6-20 ALP_E Number O ALP 정수
[0 ~ 999]7 Diabetes_N_E String M 당뇨병 신규발생 Y=Yes, N=No - 3-3 당뇨병 환자 임상 정보 데이터
구분 항목명 타입 필수여부 설명 범위 비고 1 dataset_info Object M 데이터셋정보 1-1 description String M 데이터셋명 "Follow-up Data of Diabetes Mellitus and Complications AI Dataset" 1-2 year Number M 데이터 생성년도 2021 1-3 version String M 데이터 버전 1 1-4 contributor String M 데이터 제공기관 경희대학교 산학협력단 2 patient_info Object M 환자기본정보 2-1 CDMID String M 환자코드 8자리정수 2-2 gender String M 성별 M=Male, F=Female
U=Unknown2-3 age Number M 연령(방문회차 Baseline 기준) [20 ~ 200] 3 clinical_info_array Array of M 임상정보 배열 Object 3-1 date String M 기준일 yyyy.mm.dd 3-2 visit String M 방문회차 B: Baseline
F/U : Follow up
E : End3-3 basic_info Object O 기본임상정보 3-3-1 Ht Float O 신장 소수첫째자리까지
[100 ~ 250]3-3-2 Wt Float O 체중 소수첫째자리까지
[20 ~ 200]3-3-3 BMI Float O 체질량지수 소수첫째자리까지 3-3-4 SBP Integer O 수축기혈압 정수
[30 ~ 300]3-3-5 DBP Integer O 이완기혈압 정수
[30 ~ 300]3-3-6 PR Integer O 맥박 정수
[10 ~ 300]3-3-7 HbA1c Float O 당화혈색소 소수첫째자리까지
[2 ~ 30]3-3-8 FBG Integer O (공복)혈당 정수
[10 ~ 999]3-3-9 TC Integer O 총콜레스테롤 정수
[10 ~ 999]3-3-10 TG Integer O 중성지방 정수
[10 ~ 999]3-3-11 LDL Integer O LDL 콜레스테롤 정수
[10 ~ 999]3-3-12 HDL Integer O HDL 콜레스테롤 정수
[10 ~ 999]3-3-13 BUN Float O 혈중요소질소 소수첫째자리까지
[0 ~ 200 ]3-3-14 Cr Float O 크레아티닌 소수둘째자리까지
[0 ~ 99.99]3-3-15 CrCl Float O 크레아티닌 청소율 소수둘째자리까지 3-3-16 AST Integer O AST 정수
[0 ~ 999]3-3-17 ALT Integer O ALT 정수
[0 ~ 999]3-3-18 GGT Integer O GGT 정수
[0 ~ 999]3-3-19 ALP Integer O ALP 정수
[0 ~ 999]3-3-20 m_alb Float O 미세알부민(뇨) 소수첫째자리까지
[0 ~ 999.9]3-4 disease Object M 질환보유정보 3-4-1 chronic Object M 만성질환 3-4-1-1 DM Boolean M 당뇨병 3-4-1-2 HTN Boolean M 고혈압 3-4-1-3 DL Boolean M 이상지질혈증
(고지혈증)3-4-2 macrovascular_
complications_1Object M 대혈관합병증(1)
심혈관질환3-4-2-1 MI Boolean M 심근경색 3-4-2-2 IHD Boolean M 허혈성 심장질환 3-4-2-3 HF Boolean M 심부전 3-4-2-4 AF Boolean M 심방세동 3-4-3 macrovascular_
complications_2Object M 대혈관합병증(2)
뇌혈관질환3-4-3-1 STR Boolean M 뇌졸중 3-4-4 macrovascular_
complications_3Object M 대혈관합병증(3)
말초혈관질환3-4-4-1 PVD Boolean M 말초혈관질환 3-4-5 microvascular_ complications Object M 미세혈관합병증 3-4-5-1 RTP Boolean M 망막병증 3-4-5-2 CKD Boolean M 만성콩팥병 3-4-5-3 ESRD Boolean M 말기신질환 3-4-6 etc Object M 기타 3-4-6-1 cancer Boolean M 암 3-5 medication Object O 약제별
사용유무 정보3-5-1 DM Object O 당뇨병 약제 3-5-1-1 MFM Boolean O Metformin 3-5-1-2 SU Boolean O Sulfonylurea 3-5-1-3 DPP4i Boolean O DPP-4 inhibitor 3-5-1-4 MGTN Boolean O Meglitinide 3-5-1-5 TZD Boolean O Thiazolidinedione 3-5-1-6 SGLT2i Boolean O SGLT2 inhibitor 3-5-1-7 AGI Boolean O a-glucosidase inhibitor 3-5-1-8 ISL Boolean O Insulin 3-5-1-9 GLP1a Boolean O GLP-1 agonist 3-5-2 HT Object O 고혈압 약제 3-5-2-1 ARB Boolean O ARB 3-5-2-2 ACEi Boolean O angiotensin converting enzyme inhibitor 3-5-2-3 CCB Boolean O calcium-channel blocker 3-5-2-4 DU Boolean O Diuretics 3-5-2-5 BB Boolean O Beta blocker 3-5-3 dyslipidemia Object O 고지혈증 약제 3-5-3-1 STT Boolean O Statin 3-5-3-2 FR Boolean O Fibrate 3-5-4 antiplatelet_agent Object O 항혈소판제 3-5-4-1 ASPR Boolean O Aspirin 3-5-4-2 CLP Boolean O Clopidogrel 3-5-4-3 CLSZ Boolean O Cilostazol 3-6 clinical_event Object O 주요 임상이벤트 3-6-1 admission Boolean O 최근 1년간 입원여부 3-6-2 operation Boolean O 최근 1년간 수술여부 3-6-3 er_visit Boolean O 최근 1년간
응급실 방문 여부 - 3-4 당뇨병 라이프로그 데이터
구분 항목명 타입 필수여부 설명 범위 비고 1 info Object M 데이터셋정보 1-1 description String M 데이터셋명 "Follow-up Data of Diabetes Mellitus and Complications AI Dataset" 1-2 year Integer M 데이터 생성년도 2021 1-3 version String M 데이터 버전 1 1-4 contributor String M 데이터 제공기관 닥터다이어리 2 user_info Object M 기본정보 2-1 ID String M 사용자고유ID 24자리 문자열 2-2 gender String M 성별 M=Male, F=Female, U=Unknown 2-3 birthyear Integer M 생년 4자리 정수 2-4 goal Array of Strings O 건강관리목표 체중조절, 체력향상, 건강한 식생활, 혈당 관리, 운동, 여행, 기타 2-5 job String O 직업 사무직, 서비스직, 학생, 주부, 무직, 공무원, 장치-기계 관리직, 기타 3 baseline Object M 기저임상정보 3-1 Ht Float O 키(cm) 0 이상의 수 3-2 Wt Float O 체중(kg) 0 이상의 수 3-3 BMI Float O 체질량지수 0 이상의 수 3-4 DM_T String M 당뇨병 유형 1형, 2형, 임신형, 내당능, 보호자, 기타 3-5 DM_OY Integer O 당뇨 발병연도 4자리 정수 ~ [1900, 2021] 4 diseases Object M 기저질환 4-1 GI Boolean M 소화기질환 {true, false} 4-2 RSP Boolean M 호흡기질환 {true, false} 4-3 KDN Boolean M 신장질환 {true, false} 4-4 ENDO Boolean M 내분비질환 {true, false} 4-5 IM Boolean M 면역질환 {true, false} 4-6 HEMO Boolean M 혈액질환 {true, false} 4-7 HRD Boolean M 유전병 {true, false} 5 feeds Array of Objects O 라이프로그 배열 5-1 feed_date String O 라이프로그 기록일 기록일 예시: 2017-01-04T04:50:00.000+0000 5-2 food_logs Array of Objects O 식사 정보 배열 5-2-1 food_N String O 음식 이름 5-2-2 food_A Float O 음식섭취량(인분) 0 이상의 수 5-2-3 kcal Float O 열량섭취량(kcal) 0 이상의 수 5-2-4 CHO Float O 탄수화물 섭취량(g) 0 이상의 수 5-2-5 PRO Float O 단백질 섭취량(g) 0 이상의 수 5-2-6 FAT Float O 지방 섭취량(g) 0 이상의 수 5-2-7 SS Float O 단순당 섭취량(g) 0 이상의 수 5-3 sports_logs Array of Objects O 운동 정보 배열 5-3-1 sports_N String O 운동 종류 5-3-2 sports_kcal_per_min Float O 분당운동소모열량 (kcal/분) 0 이상의 수 5-3-3 sports_A Integer O 운동 시간 (분) 0 이상의 수 5-4 medicines Array O 복약 정보 배열 5-4-1 medicine_N String O 약물 이름 5-4-2 medicine_T Arrya of Strings O 약물 종류 5-4-3 medicine_U String O 약물 정보 URL 5-5 glucose_T String O 혈당정보
(측정시점)공복, 아침 식전, 아침 식후, 점심 식전, 점심 식후, 저녁 식전, 저녁 식후, 자기 전, 기타 5-6 glucose_V Integer O 혈당정보
(측정값)0 이상의 수
4. 라벨링데이터 실제예시


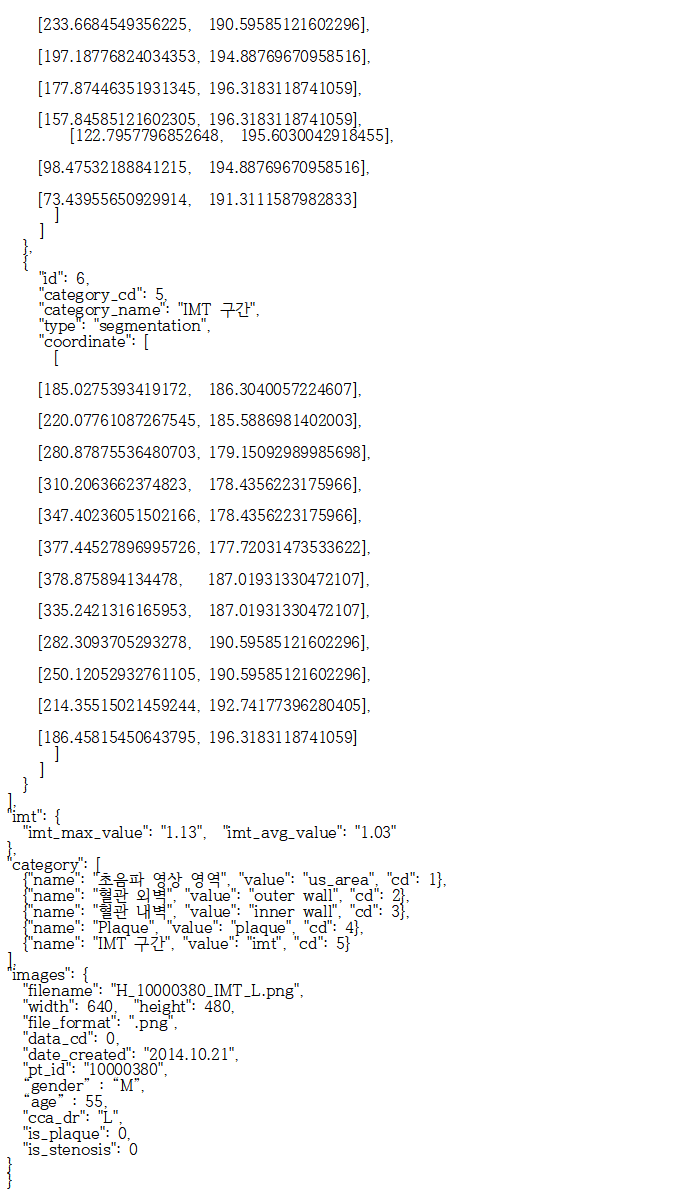
- 3-1 경동맥 초음파 영상 라벨 데이터
-
데이터셋 구축 담당자
수행기관(주관) : 경희대학교 산학협력단
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 이상열 02-958-8200 rheesy@khu.ac.kr · 사업총괄 수행기관(참여)
수행기관(참여) 기관명 담당업무 ㈜닥터다이어리 · 데이터수집 ㈜닥터웍스 · 데이터가공 ㈜데이터웨이 · 데이터 검수 네이버㈜ · AI 모델 개발 데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 이상열 02-958-8200 rheesy@khu.ac.kr
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 safezone1@aihub.kr 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.