BETA 미디어 콘텐츠 비식별처리 데이터
- 분야영상이미지·멀티모달
- 유형 비디오 , 이미지
- 생성 방식LLM
※ 26년 신규 개방되는 데이터로, 데이터 활용성 검토, 이용자 관점의 개선의견 수렴 등을 통해 수정/보완될 수 있으며 최종데이터, 샘플데이터, 산출물 등은 변경될 수 있습니다
-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.0 2026-06-05 데이터 개방 Beta Version 소개
드라마, 예능, 뉴스 등 방송 콘텐츠에서 얼굴, 번호판, 로고 등 개인식별 및 상업적 요소가 포함된 장면을 선별하여 객체 단위로 Segmentation 마스크, 다국어(한글/영어) 설명 캡션, 객체 메타정보를 포함한 비식별처리 학습용 데이터셋 구축
구축목적
방송 콘텐츠 내 얼굴, 로고 등 민감 요소를 비식별 처리하여 다양한 산업 환경에서 재활용 가능한 학습용 데이터 제공 콘텐츠 편집, 검열, 저작권 보호 등 산업 수요 대응
-
메타데이터 구조표 데이터 영역 영상이미지·멀티모달 데이터 유형 비디오 , 이미지 데이터 형식 jpg, mp4 데이터 출처 미디어영상 라벨링 유형 세그멘테이션, 메타데이터(속성) 라벨링 형식 방송영상메타데이터.csv 데이터 활용 서비스 비식별화 서비스 데이터 구축년도/
데이터 구축량2025년/25,810건 -
데이터 통계 분류 파일
포맷원시데이터 원천데이터 (1단계) (2단계) (3단계) 시:분:초 단위 수량 단위 방송 영상
데이터개인 식별 요소 얼굴 .mp4 99:16:29 시간 643 건(5분 이상) 자동차번호판 .mp4 59:42:34 시간 400 건(5분 이상) 텍스트정보 .mp4 144:27:26 시간 962 건(5분 이상) 문신 .mp4 4:45:00 시간 28 건(5분 이상) 상업적 요소 로고 .mp4 182:25:39 시간 1,196 건(5분 이상) 간판 .mp4 96:08:15 시간 649 건(5분 이상) 현수막 .mp4 148:22:43 시간 1,016 건(5분 이상) 광고판 .mp4 137:12:43 시간 916 건(5분 이상) 합계 872:20:49 5,810 합계
(500시간 이상)객체 이미지
데이터개인 식별 요소 얼굴 .jpg 7,812 건(장) 자동차번호판 .jpg 827 건(장) 텍스트정보 .jpg 2,421 건(장) 문신 .jpg 506 건(장) 상업적 요소 로고 .jpg 3,222 건(장) 간판 .jpg 1,071 건(장) 현수막 .jpg 2,375 건(장) 광고판 .jpg 1,766 건(장) 합계 20,000 -
(1) 비식별화 객체 세그멘테이션 모델 : Mask2Former
• Mask2Former : Masked-attention Mask Transformer for Universal Image Segmentation
• 예측된 세그먼트를 중심으로 localize된 feature에 attention을 제한하는 Transformer 디코더에서 masked attention을 사용. 그룹화 위한 특정 semantic에 따라 객체 또는 영역됨. 이미지의 모든 위치에 attend하는 표준 Transformer 디코더에 사용되는 cross-attention과 비교할 때, masked attention은 더 빠른 수렴과 향상된 성능으로 이어짐.
• 모델이 작은 객체/영역을 분할하는 데 도움이 되는 멀티스케일 고해상도 feature를 사용함.
• Self-attention과 cross-attention 순서 전환, query feature 학습 가능화, dropout 제거 등의 최적화 개선을 제안한다. 이 모든 것이 추가 컴퓨팅 없이 성능을 향상시킴.
• 무작위로 샘플링된 소수의 포인트에 대한 마스크 loss를 계산하여 성능에 영향을 주지 않고 학습 메모리를 3배 절약함. 이러한 개선 사항은 모델 성능을 향상 및 학습을 훨씬 쉽게 만들어 컴퓨팅이 제한된 사용자가 범용 아키텍처에 더 쉽게 접근 가능하게 함.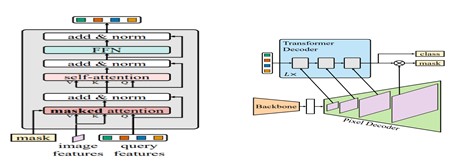
< Mask2Former 모델의 구조 >
(2) 비식별화 객체 인페인팅 모델 : BrushNet
• Diffusion 기반 Inpainting 모델로 Plug and play 방식의 Dual Branch 구조
• Diffusion 모델 전체를 재학습할 필요 없이 사전 학습된 모델에 모듈을 통합하여 유연하게 사용가능.
• 마스크된 이미지 특징 처리와 노이즈 제거 과정을 분리함으로써, 각 bruch가 자신의 과정에 집중할 수 있도록 지정함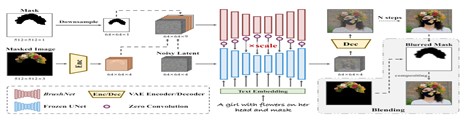
< BrushNet 모델의 구조 >
(3) 이미지 캡셔닝 모델 : LLaVA
• LLaVA : Large Language and Vision Assistant
• GPT-4로 생성한 Vision-Instruction 데이터로 학습한 멀티모달 모델임
• Clip ViT-L Image Encoder와 Vicuna-13B LLM을 연결하여 End to End로 학습되었으며 GPT-4에 가까운 수준의 대화형 Image Understanding 모델임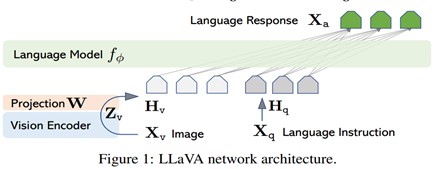
< LLaVA 모델의 구조 >
○ 모델 유효성 검증
• 데이터셋의 활용목적에 맞는 구체적인 학습 Task(모델의 탐지, 추론, 예측 등) 설정
• 학습 Task에 부합하는 AI모델 선정 및 개별 AI모델 구현
• AI모델에 따른 성능지표 설정 및 학습성능 측정 -
- 데이터 구성
- 데이터 구성 1 구분 세부 내용 영상 해상도 HD급 이상(1280×720이상) 프레임레이트 29.97 fps이상 화면비 16:09 색 심도 8-bit이상 노이즈율 2%이하 파일 포맷 MP4 (H.264) - 데이터 구성 2 단계 구분 세부 내용 1 Scene 단위 분할 AI를 사용해 원시 영상을 Scene 단위로 자동 분할 2 객체 포함
Scene 선별AI로 비식별 요소가 포함된 Scene만 1차 선별 3 영상 클립 구성 중복 제거 후 Scene을 병합하여5분 이상의 영상 클립 5,810건 생성 4 객체 이미지 추출 생성된 영상 클립에서 비식별 요소가 명확한 프레임을 20,000건 추출 5 최종 검수 영상과 이미지 모두를 대상으로 품질 및 유해성 검수 후 부적합 데이터 폐기 - 데이터 포맷
- 데이터 포맷 속성명 설명 여부 예시 program_title 방송 프로그램 제목 필수 자연스럽게 ep_id 방송 회차 고유ID 필수 EP1234 ep_date 해당 회차 방송일자 필수 2024-03-15 location 촬영 장소 선택 서울 종로구 data_type 원천 데이터 유형 필수 video license 제공기관(출처) 필수 MBN file_name 데이터 파일명 필수 PT_EN_P007_Ep029_C06.mp4 day_night 주간(낮) /야간(밤) /미분류 필수 주간(낮) season 봄·가을/여름/겨울/미분류 필수 여름 indoor_outdoor 실내(스튜디오) /실외(야외) 필수 실내(스튜디오) age_group 어린이/성인/노인/미분류 필수 성인 gender 남성/여성/미분류 필수 남성 - 어노테이션 포맷
- 어노테이션 포맷 구분 속성명 타입 필수 설명 범위 예시 1 info object y 원시데이터 정보 1-1 video_source string y 원본 영상 출처 자유 문자열 “SBS Drama Archive” 1-2 license string y 데이터·영상 라이선스 자유 문자열 “CC BY-NC 4.0” 1-3 provider_org string y 제공 기관 자유 문자열 "SBS" 1-4 copyright string y 저작권자 및 이용 제한 조건 자유 문자열 " 2 image object y 원천데이터 정보 2-1 file_name string y 원천데이터 파일명 자유 문자열 "FA_EN_P001_Ep001_C01_0001.jpg" 2-2 content_type string y 콘텐츠 유형(drama, variety, educational, news) ["drama","variety",
"educational","news"]"variety" 2-3 clip_name string y 클립 파일명 자유 문자열 "FA_EN_P001_Ep001_C01.mp4" 2-4 clip_frame_rate number y FPS > 0 29.97 2-5 clip_size string y 영상 클립의 해상도
(가로 및 세로 크기)"[ "1920x1080" 2-6 frame_number integer y 추출 프레임 번호 ≥0 360 2-7 day_night string y 주·야간별 분류 [" " 2-8 season string y 계절별 분류 [" " 2-9 indoor_outdoor string y 촬영 환경별 분류 [" " 2-10 age_group string y 연령대별 분류 [" " 2-11 gender string y 성별 분류 [" " 3 objects object y 객체 정보 3-1 id string y 객체ID 자유 문자열 "obj_face_01" 3-2 object_count integer y 객체 목록 ≥1 2 3-3 category string y 객체 분류(얼굴:face,자동차 번호판:license_plate,텍스트정보:personal_text,문신:tattoo,로고:logo,간판:signboard,현수막:banner,광고판:billboard) “face” "face" 3-4 bbox array[4] y 경계 상자 [[x1, y1, x2, y2], [x1, y1, x2, y2]] [[320, 180, 470, 380], [100, 50, 150, 200]] 3-5 polygon array> y 분할 다각형 [[[x1,y1], [x2,y2],…],…] [[[320, 180], [470, 180], [470, 380], [320, 380]], [[100, 50], [150, 50], [150, 200], [100, 200]]] 4 caption_kor object y 이미지 캡션 한글 정보 4-1 visual_kor string y 시각적 특징 설명(한국어) visual_kor와context_kor합계 문장 수≥ 5,합계 토큰 수≥ 50 " 4-2 context_kor string y 맥락 정보 설명(한국어) 04-01항목의 범위와 동일 " 5 caption_eng object y 이미지 캡션 영문 정보 5-1 visual_eng string y 시각적 특징 설명(영어) visual_eng와context_eng합계 문장 수≥ 5,합계 토큰 수≥ 50 "A woman in her twenties wearing a black shirt 5-2 context_eng string y 맥락 정보 설명(영어) 05-01항목의 범위와 동일 "Shot in a bright cafeteria during dinner -
데이터셋 구축 담당자
수행기관(주관) : 오지큐 주식회사
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 정주영 02-6101-1230 young@ogqcorp.com 전체 총괄 수행기관(참여)
수행기관(참여) 기관명 담당업무 에이치씨아이플러스(주) 데이터 구축 주식회사 티사이언티픽 데이터 검수 데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 방승온 02-6101-1230 andy_bang@ogqcorp.com 정주영 02-6101-1230 young@ogqcorp.com AI모델 관련 문의처
AI모델 관련 문의처 담당자명 전화번호 이메일 방승온 02-6101-1230 andy_bang@ogqcorp.com 정주영 02-6101-1230 young@ogqcorp.com 저작도구 관련 문의처
저작도구 관련 문의처 담당자명 전화번호 이메일 방승온 02-6101-1230 andy_bang@ogqcorp.com 정주영 02-6101-1230 young@ogqcorp.com
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기] [공용IRB 심의신청 가이드라인]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 safezone1@aihub.kr 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.
오프라인 데이터 이용 안내
본 데이터는 K-ICT 빅데이터센터에서도 이용하실 수 있습니다.
다양한 데이터(미개방 데이터 포함)를 분석할 수 있는 오프라인 분석공간을 제공하고 있습니다.
데이터 안심구역 이용절차 및 신청은 K-ICT빅데이터센터 홈페이지를 참고하시기 바랍니다.

국방데이터 개방 안내
본 데이터는 국방데이터로 군사 보안에 따라 AI허브에서 데이터를 제공하지 않으며,
군 담당자를 통한 별도의 사용 신청이 필요합니다.
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기] [공용IRB 심의신청 가이드라인]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 safezone1@aihub.kr 또는 02-525-7708, 7709로 문의