※ 26년 신규 개방되는 데이터로, 데이터 활용성 검토, 이용자 관점의 개선의견 수렴 등을 통해 수정/보완될 수 있으며 최종데이터, 샘플데이터, 산출물 등은 변경될 수 있습니다
-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.0 2026-05-19 데이터 개방 Beta Version 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2026-05-19 산출물 공개 Beta Version 소개
문서 내 수치 기반 설명문을 기반으로 차트를 자동 생성하고, 생성된 차트에 대한 질의응답 및 추론 수행을 위한 학습 데이터
구축목적
문서 내 수치 정보를 기반으로 시각요소 생성을 지원하는 알고리즘 개발 및 단계적 추론과 질의응답이 가능한 CoT(Chain of Thought) 데이터 확보를 통해 문서 자동 시각화 및 다중 추론 능력 향상에 기여
-
메타데이터 구조표 데이터 영역 영상이미지·멀티모달 데이터 유형 텍스트 , 이미지 데이터 형식 json 데이터 출처 자체 수집 (공공 데이터 포털, 정부 및 지자체, 제휴 MOU 기관 등 보유 데이터 확보) 라벨링 유형 시각화 이미지 생성, CoT(자연어) 라벨링 형식 json, jpg 데이터 활용 서비스 문서 기반 차트 자동 생성 및 차트 이해(CoT) 서비스 고도화 데이터 구축년도/
데이터 구축량2025년/원천데이터: 10,000건 라벨링데이터: 10,000건(json), 10,000건(jpg) -
○ 가공(라벨링)별 데이터 분포
가공(라벨링)별 데이터 분포표 차트 유형 대분류 차트 유형 중분류 구축 수량 구성비 비고 세로 막대형 기본형 4,320 43.51% 중첩률
84.27%누적형 31 가로 막대형 기본형 2,716 27.81% 누적형 65 선형 기본형 1,383 13.83% 원형 파이형 633 6.33% 혼합형 막대형+선형 852 8.52% 합계 10,000 100%
○ 도메인별 다양성 분포도메인별 다양성 분포표 문서 도메인 대분류 수량 비율 비고 공공·행정·안전 1,828 18.28% 중첩률
64.76%과학·기술·산업 3,582 35.82% 복지·보건·교육 2,413 24.13% 농수산·식품·문화관광 1,644 16.44% 교통·국토·환경 533 5.33% 합계 10,000 100%
○ 추론 유형별 다양성 분포추론 유형별 다양성 분포표 추론 유형 수량 비율 비고 연산 추론 9,309 31.03% 중첩률
97,97%논리 추론 20,691 68.97% 합계 10,000 100% * JSON 내 추론 쌍(pair) 기준(30,000개)
○ 추론 사고 과정(CoT) 단계 수 분포추론 사고 과정(CoT) 단계 수 분포표 추론 사고 과정 단계 수 수량 비율 3단계 30,000 100.00% 합계 30,000 100% * JSON 내 추론 쌍(pair) 기준(30,000개)
-
-
※ AI모델은 추후 공개될 예정입니다.
○ 임무 정의
- 텍스트 데이터 기반 차트 시각화 코드 생성
○ 임무 선정 사유
- Code LLaMA Instruct는 Meta AI에서 공개한 코드 생성 특화 초거대 언어모델로, 특히 Python 기반의 데이터 시각화 및 과학적 계산 관련 태스크에서 높은 정확도와 낮은 실행 오류율을 보이는 것이 특징
- 본 모델은 Matplotlib, NumPy, Pandas 등 다양한 과학적 컴퓨팅 라이브러리를 포함한 복합적인 코드 구조를 이해하고 생성하는 데 최적화되어 있어, 차트 시각화 자동화와 같은 복합적 언어-코드 연계 작업에 적합함
- 특히 instruction tuning 기반 학습 구조를 채택함으로써 사용자의 자연어 명령을 기반으로 실용적임
○ 학습 모델 개발 환경
- 학습 환경: Linux, Python, Pytorch, CUDA, GPU
- 모델 리소스 및 자원 활용: 고성능 GPU 서버를 활용하여 학습 수행
- 모델 개발: 사전 정의된 학습·평가 절차(자가 점검 계획)에 따라 파인튜닝 및 실험 반복 수행
- 모델 선정: 성능 지표 결과를 기반으로 최우수 모델 최종 선정
○ 최종 선정 모델
- Llama-3-8B-Instruct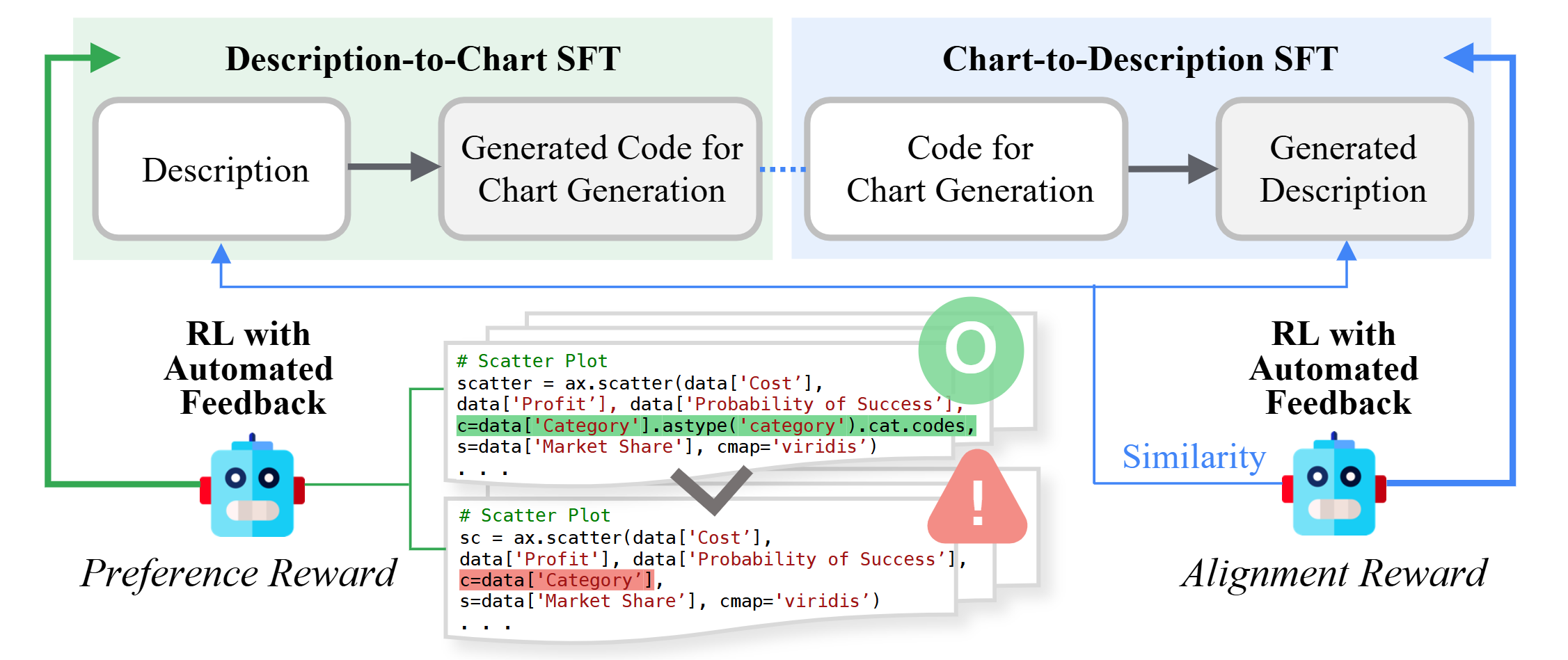
○ AI 모델 성능
AI 모델 성능표 모델명 성능 지표 목표치 Data I/O Llama-3-8B-Instruct CodeBLEU 0.4 이상 Input data: 텍스트
Output data: Matplotlib 코드
○ 임무 선정 사유
- Qwen2.5와 InternVL3는 2025년에 발표된 범용 LVLM으로 다양한 시각, 언어 태스크를 수행할 수 있음
- ChartInsturct는 ChartInstruct는 71k개의 차트와 191k개의 instruction으로 구성된 대규모 instruction tuning 데이터셋을 제안하며, 이중 chart question answering 성능을 높이기 위해 CoT 방법론 적용
- TinyChart는 CoT 방법론과 유사하게 자연어 풀이과정 대신 파이썬 코드를 생성하며 문제를 해결하는 Program-of-Thought 방법론을 통해 question answering 성능을 높임
○ 학습 모델 개발 환경
- 학습 환경: Linux, Python, Pytorch, CUDA, GPU
- 모델 리소스 및 자원 활용: 고성능 GPU 서버를 활용하여 학습 수행
- 모델 개발: 사전 정의된 학습/평가 절차(자가 점검 계획)에 따라 파인튜닝 및 실험 반복 수행
- 모델 선정: 성능 지표 결과를 기반으로 최우수 모델 최종 선정
○ 최종 선정 모델
- Qwen2.5-VL-7B-Instruct
○ AI 모델 성능
AI 모델 성능표 모델명 성능 지표 목표치 Data I/O Qwen2.5-VL-7B-Instruct LLM-as-a-Judge Accuracy 60% 이상 Input data: 차트 이미지, 질문
Output data: 답변 -
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드○ 데이터 구성
데이터 구성 항목 형태 포맷 규모 원시데이터 • 비정형 텍스트 파일 hwp, doc, pdf 1만건 원천데이터 • 설명문 텍스트 파일 json 1만건 가공데이터① • 설명문 테이블 텍스트
• 차트 시각화 코드
• QA Reasoning 텍스트json 1만건 가공데이터② • 차트 이미지 파일 jpg 1만건
○ 어노테이션 포맷어노테이션 포맷표 구분 항목명 타입 필수구분 항목 설명 1 text Object 1-1 text_id number Y 설명문 식별자 1-2 filename string Y 원천데이터 파일명 1-3 format string Y 원천데이터 포맷 1-4 description string Y 설명문 2 metadata Object 2-1 doc_id number Y 문서 고유 ID 2-2 collect_date string Y 발행연도 2-3 doc_source string Y 문서 출처 기관 2-4 doc_category string Y 문서 도메인 대분류 2-5 doc_subcategory string Y 문서 도메인 중분류 2-6 collection_method string Y 수집방식 2-7 license_type string Y 라이선스 구분 3 annotations Arr[Obj] 3-1 chart_type string Y 차트유형 대분류 3-2 chart_subtype string Y 차트유형 중분류 3-3 title string Y 제목 3-4 base string N 베이스 3-5 category Arr[str] Y 항목 3-6 legend Arr[str] N 범례 3-7 unit string Y 단위 3-8 data_label Arr[num/str] Y 데이터 레이블 4 imgs Object 4-1 img_id number Y 이미지 식별자 4-2 img_filename string Y 이미지 파일명 4-3 img_format string Y 이미지 포맷 4-4 img_width number Y 이미지 너비 4-5 img_height number Y 이미지 높이 5 visualize_code String 5-1 visualize_code string Y 차트 시각화 코드 6 qa_reasoning arr[Obj] 6-1 qa_id number Y QA 질문 식별자 6-2 question string Y QA 질문 6-3 reasoning_type string Y QA reasoning 유형 6-4 reasoning Arr[str] Y QA reasoning steps 6-5 answer string Y QA 답변
○ 예시예시표 분류 예시 원천데이터
(json){
"text": {
"text_id": 1,
"filename": "Source_00001_vertical_bar_standard.json",
"format": "json",
"description": "8일 중앙고용정보원의 산업직업별 고용구조조사에 따르면 지난해 50대 근로자의 주당 평균 근로시간은 57시간 2분으로, 전체 평균 근로시간(54시간54분) 보다 2시간 이상 긴 것으로 조사됐다.
연령대별로는 10대 42시간20분, 20대 51시간15분, 30대 54시간37분, 40대 56시간27분 등 고령층으로 갈수록 근로시간이 늘다가 60대 이상이 52시간47분으로 다소 줄었다."
}라벨데이터
(json){
"text": {
"text_id": 1,
"filename": "Source_00001_vertical_bar_standard.json",
"format": "json",
"description": "8일 중앙고용정보원의 산업직업별 고용구조조사에 따르면 지난해 50대 근로자의 주당 평균 근로시간은 57시간 2분으로, 전체 평균 근로시간(54시간54분) 보다 2시간 이상 긴 것으로 조사됐다.
연령대별로는 10대 42시간20분, 20대 51시간15분, 30대 54시간37분, 40대 56시간27분 등 고령층으로 갈수록 근로시간이 늘다가 60대 이상이 52시간47분으로 다소 줄었다."
},
"metadata": {
"doc_id": 1,
"collect_date": "2024",
"doc_source": "기사",
"doc_category": "공공·행정·안전",
"doc_subcategory": "공공행정",
"collection_method": "직접수집",
"license_type": "제1유형"
},
"annotations": {
"table_data": {
"chart_type": "세로막대형",
"chart_subtype": "기본형",
"title": "연령대별 주당 평균 근로시간",
“base”: “”,
"category": [
"10대",
"20대",
"30대",
"40대",
"50대",
"60대 이상",
"전체",
],
"legend": [
“”
],
"unit": "시간",
"data_label": [
[
"42.3",
"51.3",
"54.6",
"56.5",
"57.0",
"52.8",
"54.9"
]
]
},
"imgs": {
"label_img_filename": "Label_00001_vertical_bar_standard.jpg",
"img_format": "jpg",
"img_width": 1487,
"img_height": 1139
},
"visualize_code": "# 라이브러리 설정\\nimport numpy as np\\nimport matplotlib.pyplot as plt\\nimport matplotlib.font_manager as fm\\nimport matplotlib.ticker as ticker\\nfrom matplotlib.ticker import ScalarFormatter, FuncFormatter\\nimport uuid, os, math\\n\\n# 한글 폰트 설정\\nfont_path = '/app/font/nanum-gothic/NanumGothicBold.ttf'\\nfm.fontManager.addfont(font_path)\\nplt.rcParams['font.family'] = fm.FontProperties(fname=font_path).get_name()\\nplt.rcParams['axes.unicode_minus'] = False\\n\\n# INPUT 데이터 설정 \\nbase = \"\"\\ntitle = \"연령대별 주당 평균 근로시간\"\\nunit = \"시간\"\\ncategories = [\"10대\", \"20대\", \"30대\", \"40대\", \"50대\", \"60대\\n이상\", \"전체\"]\\nlegend = [\"\"]\\ndata_labels = [[\"42.3\", \"51.3\", \"54.6\", \"56.5\", \"57.0\", \"52.8\", \"54.9\"]]\\n\\n# 색상 설정\\ncolors = [\"#D2B48C\"]\\n\\n# 수치 변환 설정\\nvalues = []\\nfor lbl in data_labels[0]:\\n s = lbl.strip().replace(\",\", \"\")\\n try: \\n values.append(float(s))\\n except ValueError: \\n values.append(0.0)\\n\\n# 항목 별 그래프 크기 및 사이즈 설정\\nnum_categories = len(categories)\\nif num_categories <= 3:\\n fig_width, label_fontsize, bottom_margin = 8, 15, 0.12\\nelif num_categories <= 5:\\n fig_width, label_fontsize, bottom_margin = 10, 15, 0.18\\nelse:\\n fig_width, label_fontsize, bottom_margin = max(13, num_categories*1.6), 20, 0.20\\n\\n# 그래프 크기 및 막대 두께 설정\\nx_spacing = 0.25 \\nx = np.arange(num_categories) * x_spacing\\n\\nfig, ax = plt.subplots(figsize=(fig_width, 12))\\nplt.subplots_adjust(left=0.08, right=0.985, bottom=bottom_margin, top=0.84)\\nbar_width = 0.09\\nbars = ax.bar(x, values, color=colors, width=bar_width, label=legend[0] if legend else None)\\nax.set_xticks(x)\\nax.set_xticklabels(categories, fontsize=label_fontsize, rotation=0)\\nax.margins(x=0.09)\\n\\n# 개선된 Y축 범위 설정\\nymax = max(values) if values else 1.0\\nymin = min(values) if values else 0.0\\n\\n# 데이터 범위에 따른 스마트한 Y축 상한 설정\\nif ymax >= 1000:\\n # 큰 값 : 100 단위 설정\\n upper = math.ceil((ymax * 1.08) / 100) * 100\\nelif ymax >= 100:\\n # 중간 값: 10 단위 설정\\n upper = math.ceil((ymax * 1.08) / 10) * 10\\nelif ymax >= 10:\\n # 작은 값: 1 단위 설정\\n upper = math.ceil(ymax * 1.08)\\nelse:\\n # 매우 작은 값 : 소수점 설정\\n if ymax < 1:\\n upper = math.ceil(ymax * 1.08 * 10) / 10 \\n else:\\n \\n multiplier = 1.15 \\n if ymax <= 5:\\n upper = math.ceil(ymax * multiplier * 2) / 2 \\n else:\\n upper = math.ceil(ymax * multiplier) \\n\\ny_bottom = -upper * 0.02 \\nax.set_ylim(y_bottom, upper)\\nax.set_axisbelow(True)\\n\\n# 스파인 제거 설정\\nfor s in ['top','right','left','bottom']:\\n ax.spines[s].set_visible(False)\\n\\n# y축 offset 표기 제거 설정\\ny_formatter = ScalarFormatter(useOffset=False)\\nax.yaxis.set_major_formatter(y_formatter)\\n\\ndef format_func(x, pos):\\n if x >= 1000:\\n return f'{int(x):,}'\\n elif x >= 1:\\n return f'{x:.0f}' if x == int(x) else f'{x:.1f}'\\n else:\\n return f'{x:.1f}'\\n\\nax.yaxis.set_major_formatter(FuncFormatter(format_func))\\nplt.rcParams[\"axes.formatter.useoffset\"] = False\\n\\n# 눈금 수 및 그리드 설정\\nax.yaxis.set_major_locator(ticker.MaxNLocator(nbins=6, integer=False)) \\nax.grid(axis='y', which='major', color='#BDBDBD', linewidth=1, alpha=0.45)\\nax.tick_params(axis='y', length=0, labelsize=18, colors='#6E6E6E')\\nax.tick_params(axis='x', length=0, labelsize=label_fontsize, pad=6)\\n\\n# 제목, 단위 base 설정\\nplt.subplots_adjust(left=0.08, right=0.985, bottom=bottom_margin, top=0.80) \\ntitle_y = 0.92\\nunit_y = title_y - 0.06\\nfig.text(0.52, title_y, title, ha='center', va='top', fontsize=30, weight='bold')\\nfig.text(0.98, unit_y, f'(단위: {unit}{\" / base: \" + base if base else \"\"})', \\n ha='right', va='top', fontsize=18)\\n\\n# 데이터 레이블 설정\\nfor bar, lbl in zip(bars, data_labels[0]):\\n ax.text(bar.get_x()+bar.get_width()/2, bar.get_height()+0.01*ymax,\\n lbl, ha='center', va='bottom', color='black', fontsize=21, weight='bold')\\n\\n# 범례 설정\\nhas_legend = bool(legend and any(l.strip() for l in legend))\\nif has_legend:\\n ax.legend(loc='upper center', bbox_to_anchor=(0.5, -0.11), ncol=len(legend), frameon=False, fontsize=13)\\n plt.subplots_adjust(bottom=bottom_margin + 0.05)\\n\\n# 파일 저장 설정\\nsave_dir = './images'; os.makedirs(save_dir, exist_ok=True)\\nfilename = f\"{uuid.uuid4()}.jpg\"; filepath = os.path.join(save_dir, filename)\\nplt.savefig(filepath, format='jpg', dpi=120, bbox_inches='tight')\\nprint(f\"Saved chart as {filepath}\")"
"qa_reasoning": [
{
"qa_id": 1,
"question": "청년층과 중·고령층으로 구분할 때, 집단별 주당 근로시간 평균은 얼마인가?",
"reasoning_type": "연산추론",
"reasoning": [
"연령대를 청년층(10대, 20대)과 중·고령층(30대, 40대, 50대, 60대 이상)으로 구분한다.",
"청년층의 주당 평균 근로시간은 10대 42.3시간, 20대 51.3시간으로 집계되고, 중·고령층은 30대 54.6시간, 40대 56.5시간, 50대 57.0시간, 60대 이상 52.8시간으로 나타난다.",
"청년층의 근로시간 평균은 (42.3+51.3) / 2 = 46.8(시간)이고 중·고령층의 근로시간 평균은 (54.6+56.5+57+52.8) / 4 ≈ 55.2(시간)이다."
],
"answer": "청년층은 46.8시간이고 중·고령층은 55.2시간이다."
},
{
"qa_id": 2,
"question": "주당 평균 근로시간이 특정 연령대에 집중되는 경향이 있는가?",
"reasoning_type": "논리추론",
"reasoning": [
"전체 연령대의 주당 평균 근로시간을 살펴보면, 10대 42.3시간, 20대 51.3시간, 30대 54.6시간, 40대 56.5시간, 50대 57.0시간, 60대 이상 52.8시간으로 분포한다.",
"50대가 57.0시간으로 가장 높으며, 전체 평균 54.9시간 대비 약 2.1시간 더 많다. 반면 10대는 전체 평균보다 12.6시간 적다.",
"근로시간이 40~50대에 집중되는 경향이 뚜렷하며, 이는 경제활동의 핵심 연령대에서 근로 강도가 가장 높게 나타나는 현상으로 해석된다."
],
"answer": "주당 평균 근로시간은 40~50대에 집중되는 경향이 뚜렷하며, 경제활동의 핵심 연령대에서 근로 강도가 가장 높게 나타난다."
},
{
"qa_id": 3,
"question": "연령대가 높아질수록 주당 평균 근로시간은 어떤 변화를 보이는가?",
"reasoning_type": "논리추론",
"reasoning": [
"연령대별로 주당 평균 근로시간의 변화를 보면, 10대 42.3시간에서 20대 51.3시간, 30대 54.6시간, 40대 56.5시간, 50대 57.0시간까지 꾸준히 증가하다가 60대 이상에서 52.8시간으로 소폭 감소한다.",
"특히 10대에서 50대까지는 연령이 높아질수록 근로시간이 14.7시간(42.3→57.0) 증가하는 반면, 60대 이상에서는 4.2시간(57.0→52.8) 감소한다.",
"이러한 경향은 경제활동의 중심 연령대에서 근로시간이 가장 길고, 고령층에서는 은퇴·건강 등 요인으로 근로시간이 다시 줄어드는 구조적 특성이 반영된 것으로 보인다."
],
"answer": "연령대가 높아질수록 50대까지 주당 평균 근로시간이 꾸준히 증가하다가, 60대 이상에서는 다시 감소하는 경향을 보인다."
}
]
}
}라벨데이터
(jpg)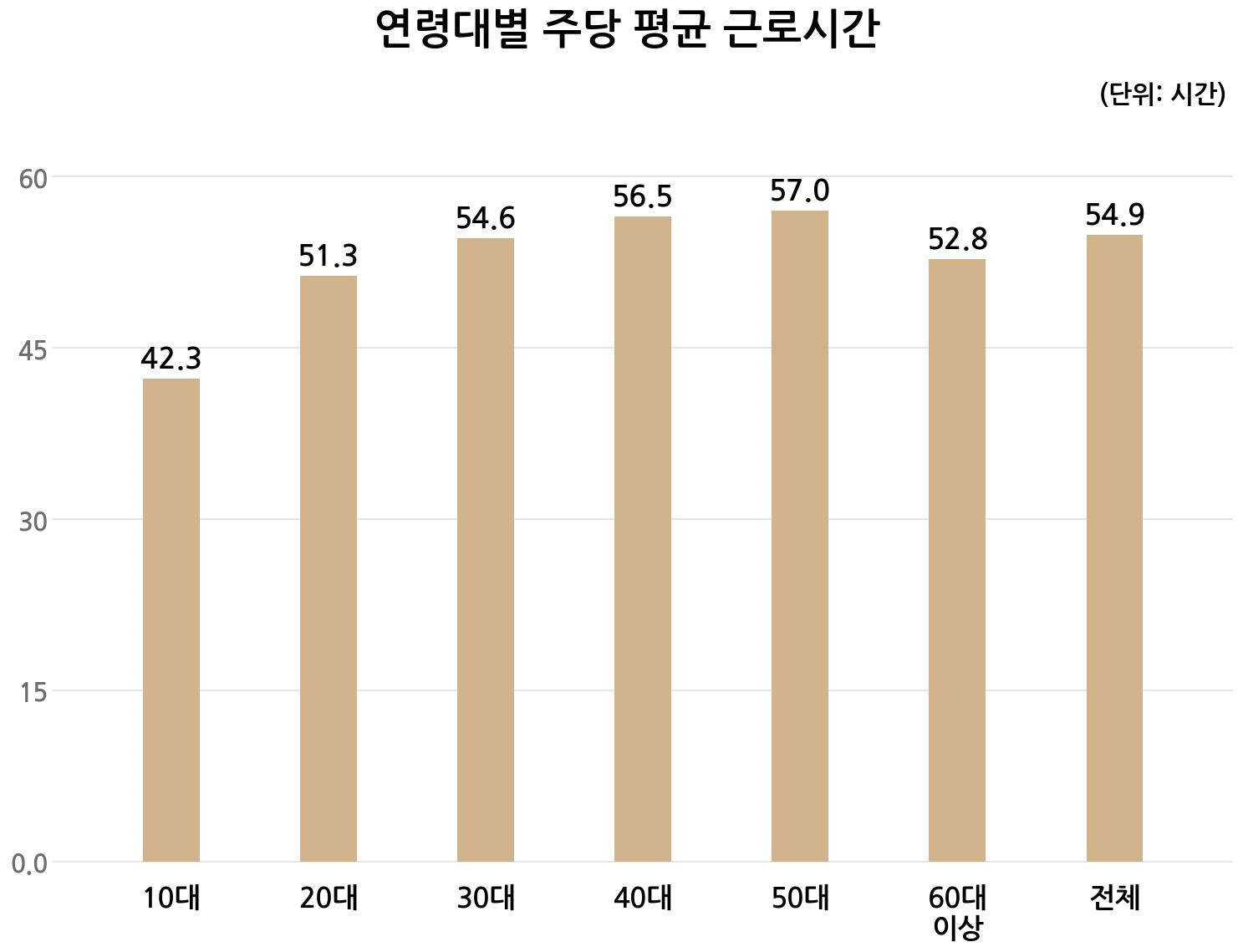
-
데이터셋 구축 담당자
수행기관(주관) : ㈜더바이럴
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 이미연 070-5129-0253 lee@the-viral.co.kr 총괄책임자 수행기관(참여)
수행기관(참여) 기관명 담당업무 ㈜메트릭스 데이터 수집 ㈜한샘가온 AI 모델 개발 및 품질 검수 데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 이미연 070-5129-0253 lee@the-viral.co.kr 임수연 02-515-7002 yim1004@the-viral.co.kr AI모델 관련 문의처
AI모델 관련 문의처 담당자명 전화번호 이메일 이미연 070-5129-0253 lee@the-viral.co.kr 임수연 02-515-7002 yim1004@the-viral.co.kr 저작도구 관련 문의처
저작도구 관련 문의처 담당자명 전화번호 이메일 이미연 070-5129-0253 lee@the-viral.co.kr 임수연 02-515-7002 yim1004@the-viral.co.kr
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기] [공용IRB 심의신청 가이드라인]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 safezone1@aihub.kr 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.
오프라인 데이터 이용 안내
본 데이터는 K-ICT 빅데이터센터에서도 이용하실 수 있습니다.
다양한 데이터(미개방 데이터 포함)를 분석할 수 있는 오프라인 분석공간을 제공하고 있습니다.
데이터 안심구역 이용절차 및 신청은 K-ICT빅데이터센터 홈페이지를 참고하시기 바랍니다.

국방데이터 개방 안내
본 데이터는 국방데이터로 군사 보안에 따라 AI허브에서 데이터를 제공하지 않으며,
군 담당자를 통한 별도의 사용 신청이 필요합니다.