※ 25년 신규 개방되는 데이터로, 데이터 활용성 검토, 이용자 관점의 개선의견 수렴 등을 통해 수정/보완될 수 있으며 최종데이터, 샘플데이터, 산출물 등은 변경될 수 있습니다.
-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.0 2025-04-16 데이터 개방 Beta Version 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2025-04-16 산출물 전체 공개 소개
농산어촌 기술 및 전문용어를 전파하고 언어장벽 해소를 위해 농산어촌 관련 전문도서, 논문, 웹/저널과 작업 상황 시나리오를 기반으로 구축한 한국어 말뭉치(문어체, 구어체, 대화체) 400만 문장을 외국어 4종(베트남어, 인도네시아어, 캄보디아어(크메르어), 태국어)으로 각 400만 문장 씩 번역한 병렬 말뭉치
구축목적
농산어촌에 근로하는 외국인 노동자에게 농산어촌 기술 및 전문용어를 전파하고, 언어장벽을 허물기 위한 한국어-외국어 병렬 말뭉치 구축
-
메타데이터 구조표 데이터 영역 농축수산 데이터 유형 텍스트 데이터 형식 txt 데이터 출처 도서, 논문, 웹사이트/저널 라벨링 유형 번역(자연어) // 라벨링유형 기재 라벨링 형식 JSON 데이터 활용 서비스 - 농산어촌 전문 번역 서비스 플랫폼 - 농산어촌 기술 및 전문용어 검색 엔진 - 농산어촌 관련 기술 및 전문지식 제공 AI 챗봇 서비스 데이터 구축년도/
데이터 구축량2024년/원천데이터 : 4,240,231 문장 | 라벨링 데이터 : JSON 4,240,231 건 (24,474,572 문장) -
1. 데이터 구축 규모
1. 데이터 구축 규모 1차경로 2차경로 3차 경로 구축량(문장) 파일포맷 도서 농림축산 작물생산 905,845 csv / json 원예생산 1,254,860 csv / json 가축업 421,915 csv / json 어업 수산생산업 1,722,765 csv / json 수산가공업 1,743,485 csv / json 논문 농림축산 작물생산 816,275 csv / json 원예생산 552,815 csv / json 가축업 845,765 csv / json 어업 수산생산업 529,755 csv / json 수산가공업 346,055 csv / json 웹/저널 농림축산 작물생산 102,740 csv / json 원예생산 344,205 csv / json 가축업 269,865 csv / json 어업 수산생산업 430,090 csv / json 수산가공업 270,325 csv / json 구어체 농림축산 작물생산 1,173,325 csv / json 원예생산 2,669,625 csv / json 가축업 2,123,405 csv / json 어업 수산생산업 1,222,300 csv / json 수산가공업 391,180 csv / json 대화체 농림축산 작물생산 1,672,940 csv / json 원예생산 1,142,170 csv / json 가축업 1,025,860 csv / json 어업 수산생산업 634,170 csv / json 수산가공업 1,653,980 csv / json 합계 24,265,715 - 2. 데이터 분포
- 언어 분포2. 데이터 분포 - 언어 분포 구분 구축수량(문장) 비율(%) 한국어 4,853,143 20% 베트남어 4,853,143 20% 인도네시아어 4,853,143 20% 태국어 4,853,143 20% 캄보디아어 4,853,143 20% 합계 24,265,715 100% - 문장 유형 분포
2. 데이터 분포 - 문장 유형 분포 구분 구축수량(문장) 비율(%) 문어체
(도서,논문,웹/저널)12,081,899 49.79% 구어체 8,674,993 35.75% 대화체 3,508,822 14.46% 합계 24,265,715 100% - 말뭉치 주제 소분류
2. 데이터 분포 - 말뭉치 주제 소분류 구분 구축수량(문장) 비율(%) 농림축산 작물생산 4,389,668 18.09% 원예생산 6,173,198 25.44% 가축업 4,765,786 19.64% 어업 수산생산업 4,831,304 19.91% 수간가공업 4,108,186 16.93% 합계 24,265,715 100% -
-
AI 모델 상세 설명서 다운로드
AI 모델 상세 설명서 다운로드 AI 모델 다운로드학습 모델 : Llama 3.1 8B instruct
• Transformer Decoder 구조
• 80억 개의 파라미터
• Instruction-tuning 을 통한 학습
• 1500억 개의 다국어 토큰을 통한 학습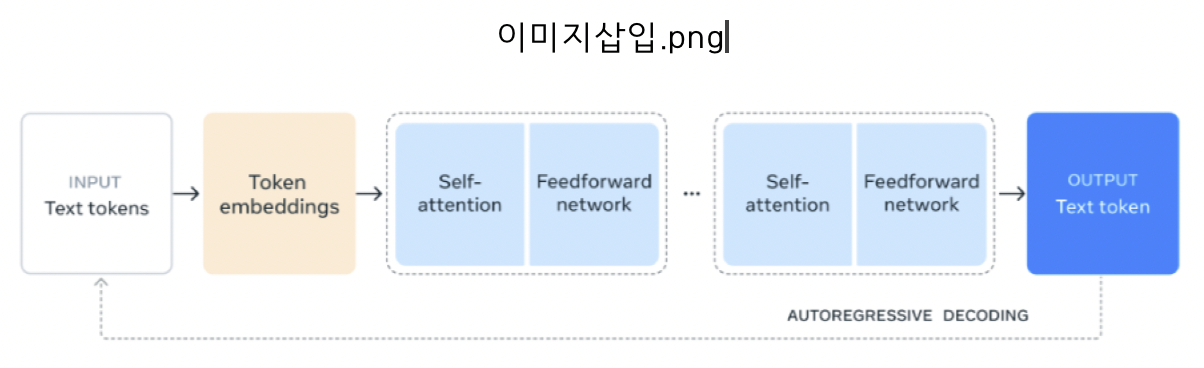
• Instruction tuning을 위한 데이터 처리
- System message: You are a useful translation AI.
Please translate the sentence given in Korean into {target_language}
- Input: {korean_text}
- Label: {target_text}
여기에서 {target_language}는 ‘Vietnamese’, ‘Indonesian’, ‘Thai’, ‘Cambodian’ 중 하나이고, {korean_text}는 번역 대상이 되는 한국어 텍스트• 학습 알고리즘 : Causal Language Modeling (CLM)
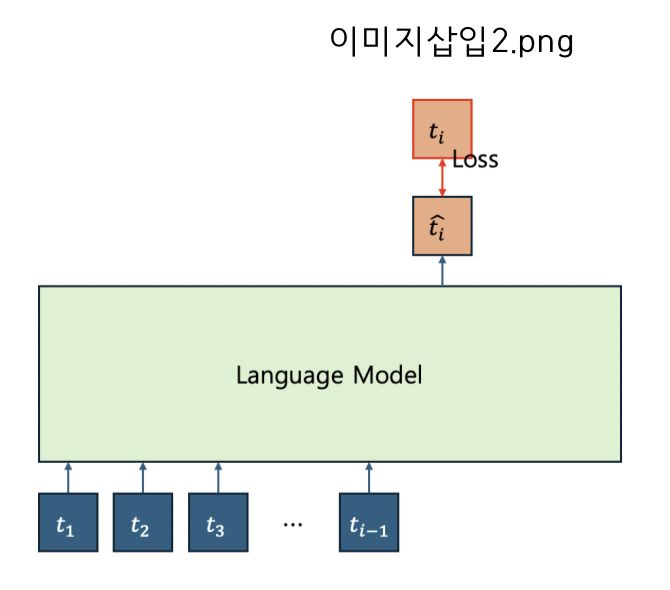
• 학습 진행 과정
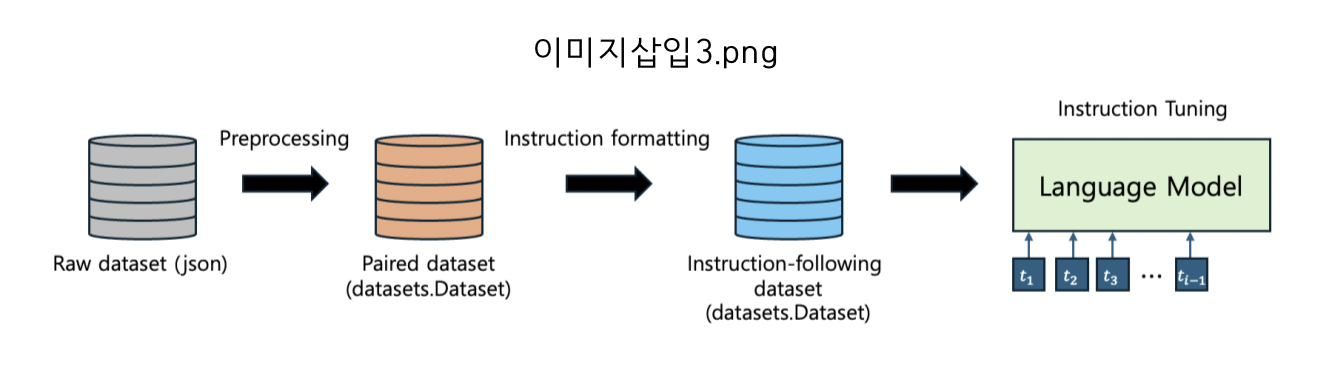
-
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드1. 데이터 구성
1. 데이터 구성 Key Description Type Child Type metadata 메타데이터 obj filename 파일명 str type 원시데이터 유형 str title 문서 제목 str url 문서 URL str category 중분류 str sub_category 소분류 str terminology 전문용어 str terminology_count 전문용어 개수 num corpus 말뭉치 및 번역문 정보 arr ko_info 한국어 말뭉치 정보 arr ko_txt 한국어 원문 str word_segment 어절 수 num speaker_id 화자 아이디 num vi_info 베트남어 번역 정보 arr vi_txt 베트남어 번역문 arr word_segment 어절 수 num speaker_id 화자 아이디 num in_info 인도네시아어 번역 정보 arr in_txt 인도네시아어 번역문 arr word_segment 어절 수 num speaker_id 화자 아이디 num th_info 태국어 번역 정보 arr th_txt 태국어 번역문 arr word_segment 어절 수 num speaker_id 화자 아이디 num ca_info 캄보디아어 번역 정보 arr ca_txt 캄보디아어 번역문 arr word_segment 어절 수 num speaker_id 화자 아이디 num 2. 어노테이션 포맷
2. 어노테이션 포맷 구분 속성명 타입 필수
여부설명 비고 1 metadata obj Y 메타데이터 1-1 filename str Y 파일명 1_1_A_A_0000001 1-2 type str Y 원시데이터 유형 1-3 title str N 문서 제목 2023 농작업 안전재해 주요통계 1-4 url str N 문서 URL https://lib.rda.go.kr/search/mediaView.do?mets_no=000000318408 1-5 category str Y 중분류 1-6 sub_category str Y 소분류 1-7 terminology str Y 전문용어 수발아 1-8 terminology_count num Y 전문용어 개수 2 2 corpus arr Y 말뭉치 및 번역문 정보 2-1 ko_info arr Y 한국어 말뭉치 정보 2-1-1 ko_txt str Y 한국어 원문 쌀 전분구조가 성글어 수분흡수 속도가 빠르므로 수발아 위험이 큼 2-1-2 word_segment num Y 어절 수 1, 2, 3... 2-1-3 speaker_id num N 화자 아이디 1, 2, 3... 2-2 vi_info arr Y 베트남어 번역 정보 2-2-1 vi_txt arr Y 베트남어 번역문 Cấu trúc tinh bột gạo nhanh chóng hấp thụnước nên có nguy cơủng hại quá mức 2-2-2 word_segment num Y 어절 수 1, 2, 3... 2-2-3 speaker_id num N 화자 아이디 1, 2, 3... 2-3 in_info arr Y 인도네시아어 번역 정보 2-3-1 in_txt arr Y 인도네시아어 번역문 Struktur pati beras cepat menyerap air sehingga berisiko besar untuk fermentasi berlebihan 2-3-2 word_segment num Y 어절 수 1, 2, 3... 2-3-3 speaker_id num N 화자 아이디 1, 2, 3... 2-4 th_info arr Y 태국어 번역 정보 2-4-1 th_txt arr Y 태국어 번역문 โครงสร้างของแป้งข้าวทำให้การดูดน้ำเข้าไปเร็วจึงมีความเสี่ยงต่อการหมักเกิน 2-4-2 word_segment num Y 어절 수 1, 2, 3... 2-4-3 speaker_id num N 화자 아이디 1, 2, 3... 2-5 ca_info arr Y 캄보디아어 번역 정보 2-5-1 ca_txt arr Y 캄보디아어 번역문 ការតម្លើងដំណើរការរបស់សត្វល្អិតដែលលឿនបង្កើនសម្រាប់សារសម្រាប់ប្រការដោយខ្លួន 2-5-2 word_segment num Y 어절 수 1, 2, 3... 2-5-3 speaker_id num N 화자 아이디 1, 2, 3... 3. 예시
JSON 예시
{
"metadata": {
"filename": "1_1_A_A_0000002",
"type": "도서",
"title": "사과_재배.pdf",
"url": "https://dl.nanet.go.kr/search,
"category": "농림축산",
"sub_category": "작물생산",
"terminology": "과수, 기관, 사과, 설립",
"terminology_count": 4
},
"corpus": {
"ko_info": [
{
"ko_txt": "그 후 1958년에 원예시 험장이 설립되어 괴수연구가 수행되었으며, 1991년 말 원예시험장에서 과수연구소가 분리되면서 산하기관으로 대구사과연구소가 설립되어 사과연구를 전담하게 되었다.",
"word_segment": 19,
"speaker_id": null
}
],
"vi_info": [
{
"vi_txt": "Sau đó, vào năm 1958, một phòng thí nghiệm làm vườn được thành lập và tiến hành nghiên cứu về quái vật. Cuối năm 1991, khi Viện nghiên cứu Orchard được tách ra khỏi phòng thí nghiệm làm vườn, Viện nghiên cứu táo Daegu được thành lập như một tổ chức trực thuộc và chịu trách nhiệm quản lý. nghiên cứu táo.",
"word_segment": 62,
"speaker_id": null
}
],
"in_info": [
{
"in_txt": "Kemudian pada tahun 1958 didirikan laboratorium hortikultura dan dilakukan penelitian terhadap monster. Pada akhir tahun 1991, ketika Orchard Research Institute dipisahkan dari laboratorium hortikultura, Daegu Apple Research Institute didirikan sebagai organisasi afiliasi dan mengambil alih. penelitian apel.",
"word_segment": 37,
"speaker_id": null
}
],
"th_info": [
{
"th_txt": "หลังจากนั้นในปี พ.ศ. 2501 ได้มีการจัดตั้งห้องปฏิบัติการพืชสวนขึ้นและดำเนินการวิจัยเกี่ยวกับสัตว์ประหลาด ในปลายปี พ.ศ. 2534 เมื่อสถาบันวิจัยออร์ชาร์ดถูกแยกออกจากห้องปฏิบัติการพืชสวน สถาบันวิจัยแอปเปิ้ลแทกูได้ก่อตั้งขึ้นเป็นองค์กรในเครือและรับผิดชอบ การวิจัยแอปเปิ้ล",
"word_segment": 264,
"speaker_id": null
}
],
"ca_info": [
{
"ca_txt": "បន្ទាប់មកនៅឆ្នាំ 1958 មន្ទីរពិសោធន៍សាកវប្បកម្មមួយត្រូវបានបង្កើតឡើង ហើយការស្រាវជ្រាវលើសត្វចម្លែកត្រូវបានធ្វើឡើងនៅចុងបញ្ចប់នៃឆ្នាំ 1991 នៅពេលដែលវិទ្យាស្ថានស្រាវជ្រាវ Orchard ត្រូវបានបំបែកចេញពីមន្ទីរពិសោធន៍សាកវប្បកម្ម វិទ្យាស្ថានស្រាវជ្រាវ Apple Daegu ត្រូវបានបង្កើតឡើងជាអង្គការដែលពាក់ព័ន្ធ និងទទួលបន្ទុក។ ការស្រាវជ្រាវផ្លែប៉ោម។",
"word_segment": 14,
"speaker_id": null
}
]
}
} -
데이터셋 구축 담당자
수행기관(주관) : ㈜오픈유아이
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 방현태 02-857-3095 sospht@openui.co.kr 실무책임자 수행기관(참여)
수행기관(참여) 기관명 담당업무 ㈜미디어그룹사람과숲 AI 모델 개발 및 품질 검수 한알음정보㈜ 데이터 가공 및 검수 데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 방현태 02-857-3095 sospht@openui.co.kr 이경민 02-857-3095 kyungmin.lee@openui.co.kr AI모델 관련 문의처
AI모델 관련 문의처 담당자명 전화번호 이메일 정용운 02-830-8583 wjddyddns@humanf.co.kr 이수복 02-830-8583 lsb@humanf.co.kr
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기] [공용IRB 심의신청 가이드라인]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 safezone1@aihub.kr 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.
오프라인 데이터 이용 안내
본 데이터는 K-ICT 빅데이터센터에서도 이용하실 수 있습니다.
다양한 데이터(미개방 데이터 포함)를 분석할 수 있는 오프라인 분석공간을 제공하고 있습니다.
데이터 안심구역 이용절차 및 신청은 K-ICT빅데이터센터 홈페이지를 참고하시기 바랍니다.

국방데이터 개방 안내
본 데이터는 국방데이터로 군사 보안에 따라 AI허브에서 데이터를 제공하지 않으며,
군 담당자를 통한 별도의 사용 신청이 필요합니다.