BETA 군 경계 작전 환경 내 인식 데이터
- 분야영상이미지
- 유형 텍스트 , 이미지
- 생성 방식LMM
'군 경계 작전 환경 내 인식 데이터는' 일부 개방으로, 자체 수집 외 데이터는 군 보안성 검토를 거쳐 향후 별도의 개방 공지 예정입니다.
-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.0 2025-05-20 데이터 개방 Beta Version 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2025-05-20 산출물 전체 공개 소개
□ 인공지능(AI) 활용 경계 작전 혁신 체계 구축 목적, 군 작전 환경(기지, 작전구역)에서의 경계 및 감시 등 작전 수행을 위한 , 감시 이미지의 상황 설명 캡션 100,000건 이상 및 매칭되는 정형데이터(기상데이터, 작전데이터, R/D데이터)구축
구축목적
□ CCTV, 다목적 카메라 등에서 수집 가능한 객체 및 환경데이터의 클래스별 분류 이미지를 활용한 객체 탐지•분류 및 이미지 생성 모델
-
메타데이터 구조표 데이터 영역 영상이미지 데이터 유형 텍스트 , 이미지 데이터 형식 jpg, csv 데이터 출처 자체 수집 및 수요군 제공 라벨링 유형 바운딩박스(이미지), 이미지캡션 라벨링 형식 JSON 데이터 활용 서비스 수요군 해안 해안경계시스템에 활용되어 경계 및 감시 등의 작전 수행 경계시스템 성능 고도화에 활용 데이터 구축년도/
데이터 구축량2024년/105,789 건 -
□ 데이터 구축 규모
□ 데이터 구축 규모 구 분 산출 수량 단위 포맷 원천데이터 이미지 데이터 105,643 장 jpg 메타데이터 105,643 건 csv 가공데이터 라벨링데이터 105,643 건 json 이미지캡션 json 구축 105,643 건 json □ 클래스 분포
※ 이하 수량은 보완 전 클래스 수량 반영 분량임. 보완 이후 클래스 수량은 보안상의 이유로 반영이 제한 됨.□ 클래스 분포 항목 구축량 구성비 EO 선박 어선 78,491 60.83% 상선 12,183 9.44% 군함 15,283 11.84% 사람 사람 19,635 15.22% 동물 유조류 3,454 2.67% 합계 129,026 100% □ 시간대별 분포
※ 이하 수량은 보완 전 클래스 수량 반영 분량임. 보완 이후 클래스 수량은 보안상의 이유로 반영이 제한됨.□ 시간대별 분포 항목 구축량 구성비 낮 89,502 84.65% 밤 16,233 15.35% 합계 105,735 100% □ 장소별 분포
※ 이하 수량은 보완 전 클래스 수량 반영 분량임. 보완 이후 클래스 수량은 보안상의 이유로 반영이 제한 됨.□ 장소별 분포 항목 구축량 구성비 백령도 45,022 42.58% 연평도 60,713 57.42% 합계 105,735 100% -
-
AI 모델 상세 설명서 다운로드
AI 모델 상세 설명서 다운로드 AI 모델 다운로드□ 학습 모델
1) 객체 탐지Grounding DINO는 Transformer 기반 객체 탐지모델 DINO를 확장하여 개발된 오픈 셋 객체 탐지모델로, 인간이 입력한 텍스트(예: 카테고리 이름, 지시 표현)를 기반으로 임의의 객체를 탐지할 수 있도록 설계되었다. 기존의 폐쇄형 객체 탐지모델은 사전에 정의된 카테고리만 탐지할 수 있는 한계가 있었으나, Grounding DINO는 언어 정보를 활용해 새로운 객체를 탐지할 수 있는 일반화 능력을 제공한다. 이는 객체 탐지의 유연성을 크게 확장하며, 다양한 실세계 응용에서 더 높은 활용 가능성을 보여준다.
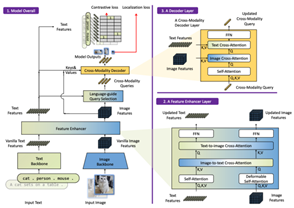
Grounding DINO 모델 구조 개요도
이 모델의 가장 큰 특징 중 하나는 언어와 비전 데이터를 긴밀히 융합하는 설계이다. 이를 위해 Grounding DINO는 세 가지 주요 융합 단계를 도입했다. 첫째, 특징 강화(feature enhancer) 단계에서는 이미지와 텍스트 간의 상호작용을 강화하기 위해 자가 주의(self-attention), 텍스트-이미지 교차 주의(text-to-image cross-attention), 이미지-텍스트 교차 주의(image-to-text cross-attention)를 활용한다. 둘째, 언어 기반 쿼리 선택(language-guided query selection) 단계에서는 입력 텍스트를 기반으로 탐지 대상이 될 가능성이 높은 이미지 영역을 선택한다. 마지막으로, 교차 모달 디코더(cross-modality decoder) 단계에서는 이미지와 텍스트 데이터를 결합하여 객체의 위치와 관련 텍스트를 예측한다. 이러한 단계별 융합 구조는 언어와 비전 데이터 간의 의미적 정렬을 효과적으로 강화하며, 탐지 성능을 크게 향상시킨다.2) 이미지 캡션 생성
ExpansionNet v2는 이미지 캡션 생성을 위한 새로운 모델로, 입력 시퀀스의 고정된 길이 제한을 극복하기 위해 개발되었다. 이 모델은 기존 어텐션 기반 시스템과 달리 입력 데이터를 확장하여 다양한 시퀀스 길이를 처리할 수 있는 메커니즘을 도입하였다. 이를 통해 고정된 길이 제한을 초월하고, 더 유연하고 효율적인 데이터 처리를 가능하게 하였다.
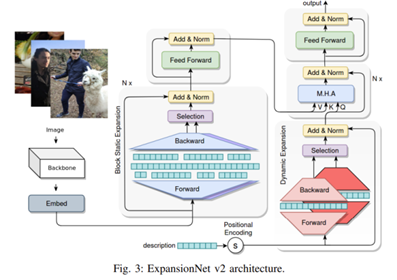
ExpansionNet v2 모델 구조
ExpansionNet v2의 핵심 기술은 Static Expansion과 Dynamic Expansion이다. Static Expansion은 고정된 길이로 확장하여 양방향 처리를 지원하고, Dynamic Expansion은 가변적 길이 확장을 통해 자동 회귀와 양방향 처리를 모두 지원한다. 이 확장 메커니즘은 시퀀스 처리에서 성능 병목 현상을 완화하며, 다양한 길이의 데이터를 효율적으로 다룰 수 있도록 설계되었다.또한, 기존 접근 방식보다 최대 2.8배 빠른 엔드투엔드 학습 전략을 통해 학습 성능과 비용 효율성을 크게 향상시켰다.
모델 구조는 Swin-Transformer 기반의 인코더-디코더 구조로 구성되어 있다. 인코더는 Static Expansion 블록을 사용해 이미지 특징을 추출하고 변환하며, 디코더는 Dynamic Expansion 블록과 교차 어텐션을 활용하여 입력 시퀀스를 처리하고 캡션을 생성한다. 최종 출력은 선형 투영층과 분류 층을 통해 도출된다. 이 과정에서 교차 엔트로피 손실과 CIDEr-D 최적화 손실을 함께 사용하여 높은 품질의 캡션을 생성한다.
성능 평가 결과, ExpansionNet v2는 MS COCO 2014 데이터 세트을 기준으로 오프라인 CIDEr-D 143.7점, 온라인 CIDEr-D 140.8점을 기록하며, 기존 모델보다 빠른 학습 속도와 우수한 성능을 입증하였다. 특히 BLEU, METEOR, ROUGE, CIDEr-D 등 다양한 평가 지표에서 높은 점수를 기록하며 최신 모델들과 비교해 경쟁력을 입증하였다. 또한, 훈련 시간은 기존 모델 대비 최대 2.8배 빠르며, 대규모 데이터 세트을 활용한 생성 모델과 비교해도 훨씬 적은 데이터와 자원으로 높은 성능을 달성하였다.
다만, 새로운 객체나 개념에 대한 일반화 성능은 최신 대규모 사전 학습 기반 모델에 비해 다소 떨어질 수 있다. 그럼에도 불구하고, ExpansionNet v2는 제한된 리소스로도 높은 성능을 요구하는 비전-언어 통합 작업에 적합하며, 학습 효율성과 확장성을 고려한 설계를 통해 이미지 캡션 생성 분야에서 새로운 가능성을 제시한다.3) 객체 분류
알리바바 DAMO 아케데미 MIIL 팀은 “ImageNet-21K Pretraining for the Masses” 논문에서 ImageNet-21K 데이터 세트를 활용하여 다양한 모델을 사전 학습하고, 특히 Vision Transformer(ViT) 모델의 성능 향상을 보고하였따고 한다. 해당 연구에서는 ImageNet-21K 데이터 세트의 대규모 라벨 구조를 활용하여 모델의 성능을 극대화하기 위해 새로운 학습 방법론을 도입하였다고 한다.
논문에서는 WordNet 계층 구조를 기반으로 데이터 전처리를 수행하고. ‘sementic softmax’라는 새로운 손실 함수를 도입하여 ViT 모델이 더 효율적으로 학습하도록 구성했다고 한다. 이 방식은 데이터 세트의 계층적 의미 구조를 반영하여 학습 과정에서 더 나은 일반화 성능을 달성할 수 있도록 도와준다고 한다. 이러한 방법론 덕분에 모델은 다양한 클래스 간 관계를 보다 명확하게 인식하고, 분류 성능을 향상 시킬 수 있었다고 한다.특히, ViT-B-16 모델은 ImageNet-21K-P 데이터 세트에서 77,6%의 sementic top-1 정확도를 기록했으며, ImageNet-1K 데이터 세트에서는 84.4%의 top-1 정확도를 달성했다고 한다. 이러한 성과는 Vision Transformer 모델이 대큐모 사전 학습을 통해 기존 모델보다 우수한 성능을 낼 수 있음을 보여주는 사례라고 할 수 있다.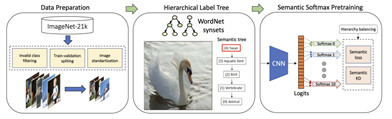
Vision Transformer 모델 학습 파이프라인 구조
또한, 사전 학습된 모델은 다양한 다운스트림 작업에 쉽게 적용할 수 있도록 timm 라이브러리를 통해 배포되었다고 한다. 해당 모델은 ‘vit_base_patch16_224_miil_in21k’라는 이름으로 사용할 수 있으며, 연구자들은 이를 활용하여 이미지 분류, 객체 탐지, 세분화 등의 다양한 비전 작업에 적용할 수 있다고 한다.
알리바바 MIIL 팀의 연구는 대규모 데이터 세트를 활용한 사전 학습의 가능성을 넓히고, ViT 모델의 확장성 및 성능을 더욱 향상시키는데 중요한 기여를 했다고 평가할 수 있다.
□ 유효성 결과
□ 유효성 결과 데이터 구분 Task명 모델명 지표 목표치 결과값 EO 객체 탐지 Grounding DINO mAP 65 67.4 객체 분류 Vision Transformer ACC(정확도) 80 88.44 이미지 캡션 생성 ExpansionNet v2 METEOR 30 32.6 IR 객체 탐지 Grounding DINO mAP 65 90.5 객체 분류 Vision Transformer ACC(정확도) 80 92.73 이미지 캡션 생성 ExpansionNet v2 METEOR 30 31.19 □ 유효성 검사 환경
[바운딩 박스 객체 검출 성능]□ 유효성 검사 환경 [바운딩 박스 객체 검출 성능] 유효성 검증 항목 항목명 바운딩 박스 객체 검출 성능 검증 방법 이미지와 캡션 데이터 2D Object Detection 학습 및 검증 수행 목적 2D 객체 검출을 통한 객체 라벨링 유효성 검증 지표 mAP(Mean Average Precision) 측정 산식 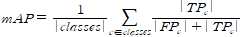
도커 이미지 Detection_Docker.tar.gz (9.8 GB) 실행 파일명 학습 : train.py, 검증 : test.py 유효성 검증 환경 CPU Intel(R) Xeon(R) Silver 4210 CPU @ 2.20GHz * 2ea Memory 378G GPU NVIDIA Quadro RTX A6000 * 8ea Storage 1.8TB OS Ubuntu 20.04.6 LTS 유효성 검증 모델 학습 및 검증 조건 개발 언어 Python 3.8.12 프레임워크 프레임워크 및 라이브러리 버전 torch 1.11.0 학습 알고리즘 Grounding DINO 학습 조건 no 파라미터 파라미터 값 1 epoch 30 2 learning rate 0.0004 3 weight decay 0.0001 4 optimizer AdamW 사용 5 box_noise_scale 1 6 batch size 12 7 image size random choice scale[(480, 1333), (512, 1333), (544, 1333), (576, 1333), (608, 1333), (640, 1333), (672, 1333), (704, 1333), (736, 1333), (768, 1333), (800, 1333)] 파일 형식 학습 : EO-Image(.png) / Label-file(.json) /
IR-Image(.png) / Label-file(.json)검증 : EO-Image(.png) / Label-file(.json) /
IR-Image(.png) / Label-file(.json)전체 구축 데이터 대비
모델에 적용되는 비율AI 모델 사용 이미지 비율 - 구축된 전체 데이터 100% ※ 유효성 검증은 구축된 데이터 전체를 적용하며, 변경이 필요한 경우 TTA 담당자와 협의한다. 모델 학습 과정별
데이터 분류 및 비율 정보Train : Val : Test = 80 : 10 : 10 ※ 분류 기준(EO) - Training Set 비율 80% (73,795개) - Validation Set 비율 10% (9,225개) - Test Set 비율 10% (9,224개) no 클래스 Total Train Val Test 1 어선 78,543 62,722 7,941 7,880 2 상선 12,183 9,722 1,200 1,261 3 군함 15,291 12,318 1,482 1,491 4 사람 19,658 15,707 1,965 1,986 5 유조류 3,454 2,725 347 382 전체 수량 129,129 103,194 12,935 13,000 ※ 분류 기준(IR) - Training Set 비율 80% (10,483개) - Validation Set 비율 10% (1,311개) - Test Set 비율 10% (1,313개) no 클래스 Total Train Val Test 1 선박 15,214 12,590 1,311 1,313 전체 수량 15,214 12,590 1,311 1,313 제한사항 • [이미지 캡션 생성 성능]
□ 유효성 검사 환경 [이미지 캡션 생성 성능] 유효성 검증 항목 항목명 이미지 캡션 생성 성능 검증 방법 이미지와 캡션 데이터 Image Captioning 학습 및 검증 수행 목적 이미지 캡션 생성을 통한 라벨링 유효성 검증 지표 METEOR(Metric for Evaluation of Translation with Explicit ORdering) 측정 산식 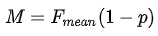
도커 이미지 Captioning_Docker.tar.gz (7.92 GB) 실행 파일명 학습 : train.py, 검증 : test.py 유효성 검증 환경 CPU Intel(R) Xeon(R) Silver 4210 CPU @ 2.20GHz * 2ea Memory 378G GPU NVIDIA Quadro RTX A6000 * 8ea Storage 1.8TB OS Ubuntu 20.04.6 LTS 유효성 검증 모델 학습 및 검증 조건 개발 언어 Python 3.8.8 프레임워크 프레임워크 및 라이브러리 버전 torch 1.8.1 학습 알고리즘 ExpansionNet v2 학습 조건 no 파라미터 파라미터 값 1 epoch 12 2 learning rate 2.00E-04 3 weight decay 없음 4 optimizer RAdam 5 batch size 512 6 image size 384 파일 형식 학습 : EO-Image(.png) / Label-file(.json) / IR-Image(.png) / Label-file(.json) 검증 : EO-Image(.png) / Label-file(.json) / IR-Image(.png) / Label-file(.json) 전체 구축 데이터 대비
모델에 적용되는 비율AI 모델 사용 이미지 비율 - 구축된 전체 데이터 100% ※ 유효성 검증은 구축된 데이터 전체를 적용하며, 변경이 필요한 경우 TTA 담당자와 협의한다. 모델 학습 과정별
데이터 분류 및 비율 정보Train : Val : Test = 80 : 10 : 10 ※ 분류 기준(EO) - Training Set 비율 80% (87,575개) - Validation Set 비율 10% (10,988개) - Test Set 비율 10% (11,030개) no 클래스 Total Train Val Test 1 어선 67,856 54,232 6,773 6,851 2 상선 12,014 9,588 1,234 1,192 3 군함 14,999 12,031 1,477 1,491 4 사람 14,750 11,703 1,502 1,495 5 유조류 24 21 2 1 전체 수량 109,643 87,575 10,988 11,030 ※ 분류 기준(IR) - Training Set 비율 80% (10,485개) - Validation Set 비율 10% (1,311개) - Test Set 비율 10% (1,311개) no 클래스 Total Train Val Test 1 선박 13,107 10,485 1,311 1,311 전체 수량 13,107 10,485 1,311 1,311 제한사항 • [객체 분류 성능]
□ 유효성 검사 환경 [객체 분류 성능] 유효성 검증 항목 항목명 바운딩 박스 객체 검출 성능 검증 방법 이미지와 캡션 데이터 2D Object Detection 학습 및 검증 수행 목적 객체 클래스 분류를 통한 라벨링 유효성 검증 지표 ACC (Accuracy) 측정 산식 
도커 이미지 Classification_Docker.tar.gz (8.9 GB) 실행 파일명 학습 : train.py, 검증 : test.py 유효성 검증 환경 CPU Intel(R) Xeon(R) Silver 4210 CPU @ 2.20GHz * 2ea Memory 378G GPU NVIDIA Quadro RTX A6000 * 8ea Storage 1.8TB OS Ubuntu 20.04.6 LTS 유효성 검증 모델 학습 및 검증 조건 개발 언어 Python 3.7.11 프레임워크 프레임워크 및 라이브러리 버전 torch 1.9.1 학습 알고리즘 Vision Transformer 학습 조건 no 파라미터 파라미터 값 1 epoch 80 2 learning rate 3.00E-04 3 weight decay 1.00E-04 4 optimizer adam 5 batch size 384 6 image size (224, 224) 파일 형식 학습 : EO-Image(.png) / Label-file(.json) / IR-Image(.png) / Label-file(.json) 검증 : EO-Image(.png) / Label-file(.json) / IR-Image(.png) / Label-file(.json) 전체 구축 데이터 대비
모델에 적용되는 비율AI 모델 사용 이미지 비율 - 구축된 전체 데이터 100% ※ 유효성 검증은 구축된 데이터 전체를 적용하며, 변경이 필요한 경우 TTA 담당자와 협의한다. 모델 학습 과정별
데이터 분류 및 비율 정보Train : Val : Test = 80 : 10 : 10 ※ 분류 기준(EO) ※ 객체 분류는 원본 이미지에서 객체 영역을 오려서 이미지로 사용 - Training Set 비율 80% (100,544개) - Validation Set 비율 10% (12,558개) - Test Set 비율 10% (12,571개) no 클래스 Total Train Val Test 1 어선 78,558 62,846 7,855 7,857 2 상선 12,180 9,744 1,218 1,218 3 군함 15,280 12,230 1,520 1,530 4 사람 19,655 15,724 1,965 1,966 5 유조류 3,451 2,760 345 346 전체 수량 125,673 100,544 12,558 12,571 ※ 분류 기준(IR) ※ 객체 분류는 원본 이미지에서 객체 영역을 오려서 이미지로 사용 - Training Set 비율 80% (10,485개) - Validation Set 비율 10% (1,311개) - Test Set 비율 10% (1,311개) no 클래스 Total Train Val Test 1 선박 13,107 10,485 1,311 1,311 전체 수량 13,107 10,485 1,311 1,311 제한사항 • -
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드□ 데이터 구성 및 구축 규모
□ 데이터 구성 및 구축 규모 구분 산출 수량 단위 포맷 원시데이터 영상데이터(CCTV(EO/IR), 다기능 카메라 1,300 클립 mov/mp4 정형데이터(기상데이터 등) 1,300 건 txt 원천데이터 이미지 데이터 105,643 장 jpg 가공데이터 라벨링 데이터 105,643 건 json 이미지캡션 json 구축 105,643 건 json other 데이터 메타 데이터 105,643 건 csv □ 폴더명 구성 정보
□ 폴더명 구성 정보 경로 구분 정보 구분자 정보 1차 경로 원시데이터 수집장소 - I1(연평도) - I2(백령도) 2차 경로 수집지점별 ID - 직접 수집(S0) - 해병대 수집(S1) 3차 경로 수집장비별 ID - CCTV(EO) (C1) - CCTV(IR) (C2) - UAV (C3) - TOD (C4) - 일반 카메라 (C5) 4차 경로 클립 번호 0001001 ~ 9999999 □ 파일명 구성 정보
□ 파일명 구성 정보 예시 세부 구성 설명 I1_S1_C1_0001001.json 수집장소_수집지점_수집장비_클립번호.json □ 어노테이션 포맷
□ 어노테이션 포맷 No. 항목명 타입 필수 구분 항목 설명 예시 1 meta object 필수 기본정보 - 1-1 date string 필수 날짜 정보 2024-04-05 1-2 time number 필수 시간정보 0 낮 0 밤 1 1-3 location number 필수 위치정보 1 백령도 0 연평도 1 1-4 spot number 필수 거점정보 1 해병대 수집 0 구항 1 끝섬전망대 2 신항 3 사곶해변 4 오군포구 5 중화동포구 6 콩돌해안 7 용트림바위 8 평화끝섬전망대 9 당섬선착장 10 안목선착장 11 함상공원 12 책섬 13 가래칠기해변 14 구리동해수욕장 15 평화전망대 16 고봉포구 17 1-5 sensor number 필수 센서정보 1 가시광선 0 적외선 1 1-6 equipment number 필수 장비정보 1 일반 카메라 1 CCTV(EO) 2 CCTV(IR) 3 다기능 카메라 4 1-7 weather array 필수 기상데이터 [27.7, 204.5, 2.2, 0, 992.2, 1008.7, 77] [기온,풍향,풍속,강수량,현지기압,해면기압,습도] 1-8 senario number 필수 move 1 1 stop 2 1-9 radar array 선택 radar정보 1-10 dataset string 필수 데이터명 정보 군 경계 작전 환경 내 인식 데이터 1-11 license string 필수 출처 정보 ROKMC 2 annotations array 필수 가공 정보 - 2-1 filename string 필수 파일명 정보 I1_S0_C5_0001001 2-2 width number 필수 파일 너비 정보 1920 2-3 height number 필수 파일 높이 정보 1080 2-4 caption string 필수 캡션 정보 (예) 바다 위의 선박이 산과 해안 사이에서 배회하고 있다. 2-5 kind string 필수 클래스 정보 0 0 선박 1 사람 2 동물 2-6 class string 필수 서브 클래스 정보 1 0 어선 1 상선 2 군함 3 사람 4 유조류 5 선박 2-7 bbox array 필수 객체 정보 [1512,372,374,179] 2-8 area number 필수 영역 정보 66021 항목명 형태 meta date 
time location spot sensor equipment weather senario radar dataset license annotations filename width height caption kind class bbox area □ 데이터 포맷
- 데이터 포맷 예시
> 2D 이미지 내 객체(class)에 Bounding box 가공 후, 이미지캡션 작성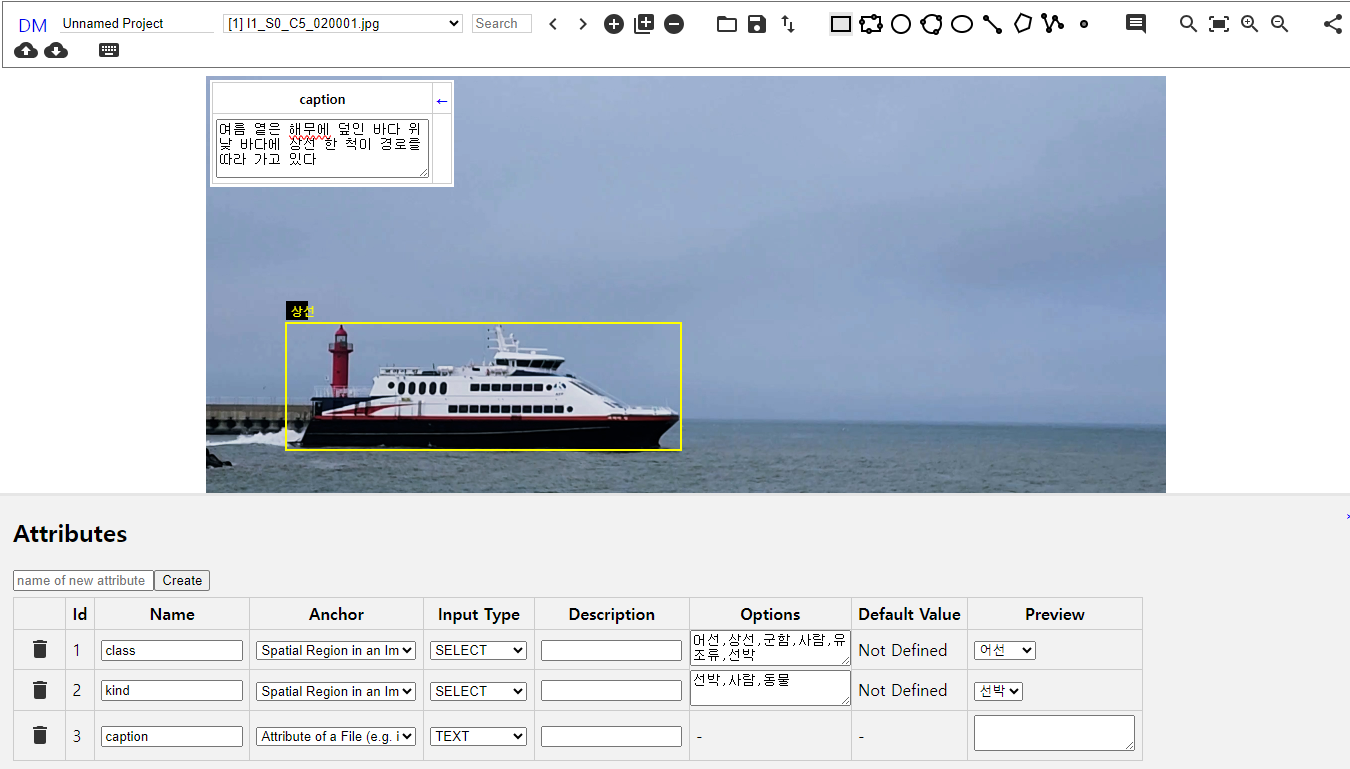
□ 데이터 실제 예시
1) 원천 데이터
2) 라벨데이터(JSON)
{
"meta": {
"date": "2024-08-20",
"time": 0,
"location": 1,
"spot": 14,
"sensor": 0,
"equipment": 1,
"weather": [
31.8,
182,
2.5,
0,
1008.7,
1009.6,
76
],
"scenario": 1,
"radar": [],
"dataset": "군 경계 작전 환경 내 인식 데이터",
"license": "자체수집"
},
"annotations": [
{
"filename": "I1_S0_C5_0001001.jpg",
"width": 1920,
"height": 1080,
"caption": "8월 맑은 날씨의 낮 바다에 어선 한 척이 지나가는 중이다.",
"kind": "0",
"class": "0",
"bbox": [
80,
739,
99,
22
],
"area": 2178
}
]
} -
데이터셋 구축 담당자
수행기관(주관) : 흥일기업(주)
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 박준영 02-6283-0156 jypark@hungil.co.kr 사업 관리 및 데이터 수집, 정제 수행기관(참여)
수행기관(참여) 기관명 담당업무 인피닉 데이터 가공, 검사 한밭대학교 산학협력단 데이터 학습 데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 박준영 02-6283-0156 jypark@hungil.co.kr 김보라 02-6283-0157 brkim@hungil.co.kr AI모델 관련 문의처
AI모델 관련 문의처 담당자명 전화번호 이메일 최동걸 042-821-1213 dgchoi@hanbat.ac.kr 유용현 042-821-1213 yonghyeon0316@gmail.com 저작도구 관련 문의처
저작도구 관련 문의처 담당자명 전화번호 이메일 정지현 02-555-9627 jh3jung@infiniq.co.kr 손미선 02-555-9627 jh3jung@infiniq.co.kr
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기] [공용IRB 심의신청 가이드라인]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 safezone1@aihub.kr 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.
오프라인 데이터 이용 안내
본 데이터는 K-ICT 빅데이터센터에서도 이용하실 수 있습니다.
다양한 데이터(미개방 데이터 포함)를 분석할 수 있는 오프라인 분석공간을 제공하고 있습니다.
데이터 안심구역 이용절차 및 신청은 K-ICT빅데이터센터 홈페이지를 참고하시기 바랍니다.

국방데이터 개방 안내
본 데이터는 국방데이터로 군사 보안에 따라 AI허브에서 데이터를 제공하지 않으며,
군 담당자를 통한 별도의 사용 신청이 필요합니다.
· 데이터 이용 신청 문의
해병대사령부 지능정보화발전과
| 담당자명 | 전화번호 | 이메일 |
|---|---|---|
| 김동현 주무관 | 031-8012-3825 | rokmc_kdh@mnd.go.kr |