BETA 공공 민원 상담 LLM 사전학습 및 Instruction Tuning 데이터
- 분야한국어
- 유형 텍스트
- 생성 방식LLM
※ 25년 신규 개방되는 데이터로, 데이터 활용성 검토, 이용자 관점의 개선의견 수렴 등을 통해 수정/보완될 수 있으며 최종데이터, 샘플데이터, 산출물 등은 변경될 수 있습니다
-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.0 2025-04-16 데이터 개방 Beta Version 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2025-04-16 산출물 전체 공개 소개
단답형 7천쌍, 서술형 3천 쌍으로 된 공공 분야 민원 상담 텍스트 데이터 10,182건 수집하여 분류, 요약, 질의 응답 등 3가지 유형의 Instruction Tuning Data 가공 구축
구축목적
공공 민원 상담 내용을 기반으로 LLM의 사전학습 및 Instruction Tuning을 위한 가공데이터를 구축하여 민원 상담 분야의 AI 서비스의 품질 제고 및 확산을 위함
-
메타데이터 구조표 데이터 영역 한국어 데이터 유형 텍스트 데이터 형식 json 데이터 출처 중앙행정기관(고용노동부, 국토교통부, 중소벤처기업부), 지방행정기관(경상남도, 경상북도, 부천시, 서울시, 성남시, 수원시, 안양시, 용인시, 울산광역시, 의정부시, 제주특별자치도, 천안시, 파주시, 화성시), 국립아시아문화전당 라벨링 유형 분류(자연어), 내용요약(자연어), 질의응답(자연어) 라벨링 형식 json 데이터 활용 서비스 챗봇 서비스, AI 상담 도우미 서비스 데이터 구축년도/
데이터 구축량2024년/원천데이터 10,182건, 라벨링 데이터 124,717건 -
총 상담 데이터 건수 총 10,182건 총 어절 수 총 2,575,512어절 수집 출처 분포 수집처 건수 비율 의정부시 74 0.06% 울산광역시 109 0.09% 경상남도 148 0.12% 파주시 194 0.16% 수원시 271 0.22% 용인시 327 0.26% 경상북도 1,012 0.81% 화성시 1,264 1.01% 부천시 1,533 1.23% 천안시 1,739 1.39% 제주특별자치도 5,420 4.35% 성남시 10,027 8.04% 안양시 10,264 8.23% 국립아시아문화전당 13,025 10.44% 고용노동부 16,334 13.10% 서울시 17,193 13.79% 중소벤처기업부 18,899 15.15% 국토교통부 26,884 21.56% 합계 124,717 100% 상담데이터 1건당 평균
Instruction tuning data 수평균 12.25건
(가공데이터 124,717건 / 원천데이터 10,182건)평균 어절 수 분포 어절 수 분포 건수 비율 124 어절 이하 649 6.37% 125~200 어절 3,636 35.71% 201~250 어절 1,642 16.13% 251~300 어절 1,152 11.31% 301 어절 이상 3,103 30.48% 합계 10,182 100% 분류 유형별 가공 수량 분포 분류 건수 비율 상담 주제 10,185 20.00% 상담 요건 10,182 20.00% 상담 내용 10,182 20.00% 상담 사유 10,182 20.00% 상담 결과 10,182 20.00% 합계 50,913 100% 분류 유형 분포 상담 주제 건수 비율 교통 1,244 12.21% 환경 702 6.89% 안전 1,337 13.13% 복지 992 9.74% 문화 1,347 13.23% 경제 2,026 19.89% 주택/건설 2,331 22.89% 기타
(국방/세무/방송통신/경찰 등)
206 2.02% 합계 10,185 100% 상담 요건 건수 비율 단일 요건 민원 8,649 84.94% 다수 요건 민원 1,533 15.06% 합계 10,182 100% 상담 내용 건수 비율 일반 민원 상담 8,468 83.17% 고충 민원 상담 994 9.76% 다수기관 복합 민원 상담 720 7.07% 합계 10,182 100% 상담 사유 건수 비율 기관 1,051 10.32% 민원인 9,131 89.68% 합계 10,182 100% 상담 결과 건수 비율 만족 4,496 44.16% 미흡 2,899 28.47% 해결 불가 2,266 22.25% 추가 상담 필요 521 5.12% 합계 10,182 100% 요약 유형 분포 요약 유형 건수 비율 기본 요약 10,200 24.48% 길이 제한 요약 10,459 25.10% 주제 중점 요약 10,522 25.25% 핵심 정보 추출 요약 10,488 25.17% 합계 41,669 100% 요약문 길이 분포 요약문 어절 수 분포 건수 비율 5~20 어절 3,958 9.50% 21~40 어절 25,862 62.07% 41~60 어절 7,738 18.57% 61 어절 이상 4,111 9.87% 합계 41,669 100.01% 질의 유형 분포 질의 유형 건수 비율 의문사형 20,217 62.91% 예/아니요형 11,918 37.09% 합계 32,135 100% 질의 답변 길이 분포 지시(질의)문 건수 비율 1~3 어절 207 0.64% 4~6 어절 6,592 20.51% 7~13 어절 22,368 69.61% 14 어절 이상 2,968 9.24% 합계 32,135 100% 답변문 건수 비율 1~3 어절 15,698 48.85% 4~6 어절 6,811 21.19% 7~13 어절 8,678 27.00% 14 어절 이상 948 2.96% 합계 32,135 100% 가공 유형 분포 가공 유형 건수 비율 분류 50,913 40.82% 요약 41,669 33.41% 질의응답 32,135 25.77% 합계 124,717 100% -
-
AI 모델 상세 설명서 다운로드
AI 모델 상세 설명서 다운로드 AI 모델 다운로드● 분류 모델 : Meta-Llama-3-8B-Instruct
* LLAMA3 모델은 메타의 AI 그룹이 개발한 차세대 사전 훈련된 대규모 언어 모델(LLM)
* 128K 토큰의 vocabulary 적용
* 사전학습과 강화 학습 과정의 개선을 통해 추론, 코드 생성 및 지시 수행 등의 능력이 기존 모델 대비 대폭 향상
* Groouped Query Attention(GQA)을 통해 추론 효율성 개선
* 파라미터 개수에 따라 다양한 모델 크기를 제공
● 요약 및 질의응답 모델 : openchat-3.5-0106(mistral)
* OpenChat 모델은 C-RLFT 방법론을 사용해 파인튜닝한 오픈 소스 언어 모델
* C-RLFT 방법론은 이미 라벨링된 다양한 품질(고품질과 저품질)의 데이터를 활용하여 클래스 조건화 데이터셋을 구축하고 표준 RLHF 방법론과 유사하게 보상을 최대화하는 방식으로 학습
* OpenChat 최신 모델은 Mistral 과 Gemma을 기본 모델로 한 파인튜닝 모델을 제공
* 최근에 OpenChat-3.5 의 업그레이드 버전이 출시되었으며 다양한 벤치마크에서 뛰어난 성능을 보임. 한국어의 성능도 우수함
-
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드1. 데이터 구성
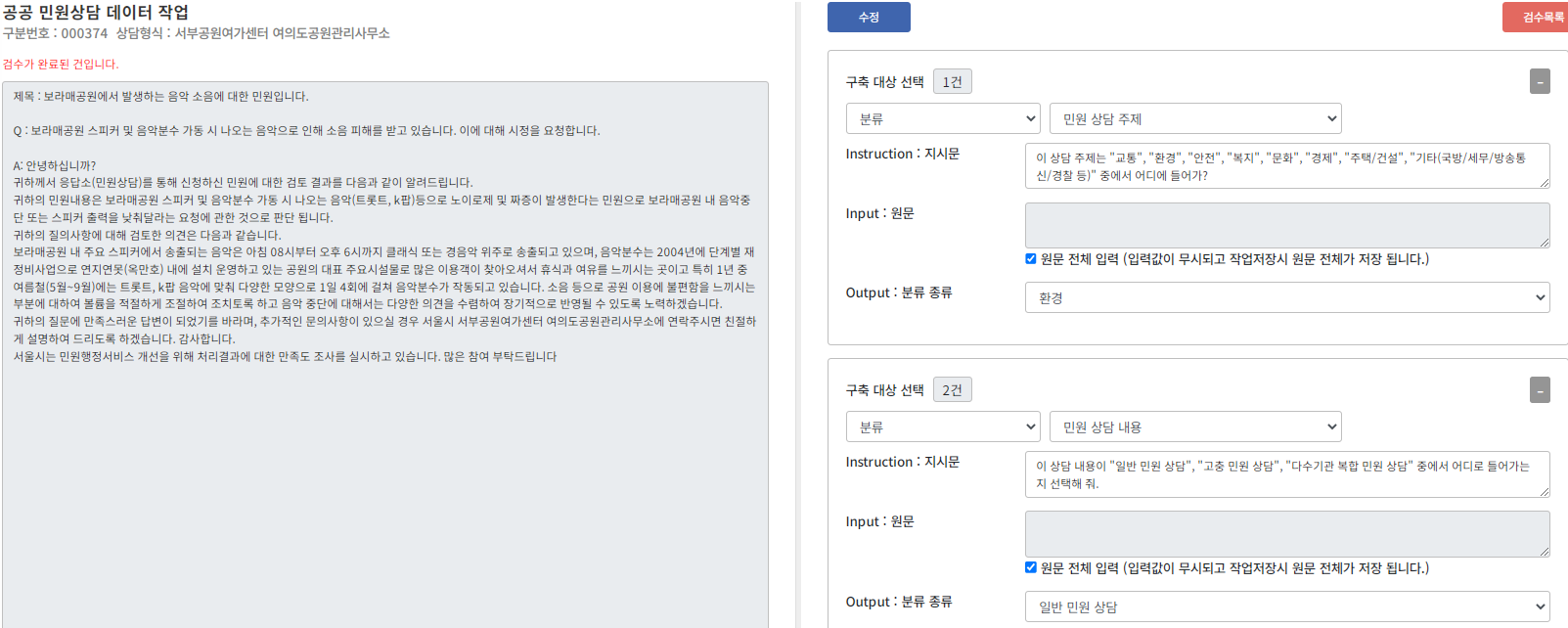
데이터 구성 Key Description Type Child Type source 원천대상 string 수집기관명 source_id 원천데이터 일련번호 string 1 consulting_date 상담일시 string 20231005 consulting_category 수집기관별 업무 유형 string 유형명 client_gender 상담자 유형 string 남, 여 client_age 상담자 연령대 string 30대 consulting_time 상담시간 string 초 consulting_content 상담내용 string consulting_turns 대화턴 수 string consulting_length 상담 내용 길이 string 어절 수 tuning_type 분류, 요약, 질의응답 string instructions.instruction_id 지시문 아이디 number 1, 2, 3... instructions.task 분류, 요약, 질의응답 string instructions.task_category 태스크 하위 카테고리 string 가공 유형명 instruction_length 지시문 길이(어절 수) string input_length input 데이터 길이(어절 수) string output_length output 데이터 길이(어절 수) string instructions.instruction 지시문, 질문 string instructions.input 원천데이터 상담 내용 전체 또는 일부 string instructions.output 분류명, 요약문, 답변 string 2. 어노테이션 포맷
어노테이션 포맷 No 항목명 타입 필수 구분 항목 설명 비고(예시) 1 1 source string 필수 원천대상 서울시 2 source_id string 필수 원천데이터 일련번호 361 3 consulting_date string 상담일시 20230619 4 consulting_category string 소관부서, 업무 유형 등 동부공원여가센터... 5 client_gender string 상담자 유형 6 client_age string 상담자 연령대 7 consulting_time string 상담시간 8 consulting_content string 필수 상담내용 9 consulting_turns string 대화턴 수 10 consulting_length string 필수 상담 내용 길이 단답형: 제한없음
서술형: 125어절 이상
(rfp 500자 이상-1어절 평균 4자 추정)2 1 instructions array 1 tuning_type string 필수 분류, 요약, 질의응답 2 data array 1 instructions.instruction_id number 필수 지시문 아이디 1, 2... 2 instructions.task string 필수 분류, 요약, 질의응답 3 instructions.task_category string 필수 태스크 하위 카테고리 분류 유형, 요약 유형, 질의응답 유형 4 instruction_length string 필수 지시문 길이(어절 수) 5 input_length string 필수 input 데이터 길이(어절 수) 6 output_length string 필수 output 데이터 길이(어절 수) 7 instructions.instruction string 필수 지시문, 질문 8 instructions.input string 필수 원천데이터 상담 내용
전체 또는 일부9 instructions.output string 필수 분류명, 요약문, 답변 3. 데이터 포맷
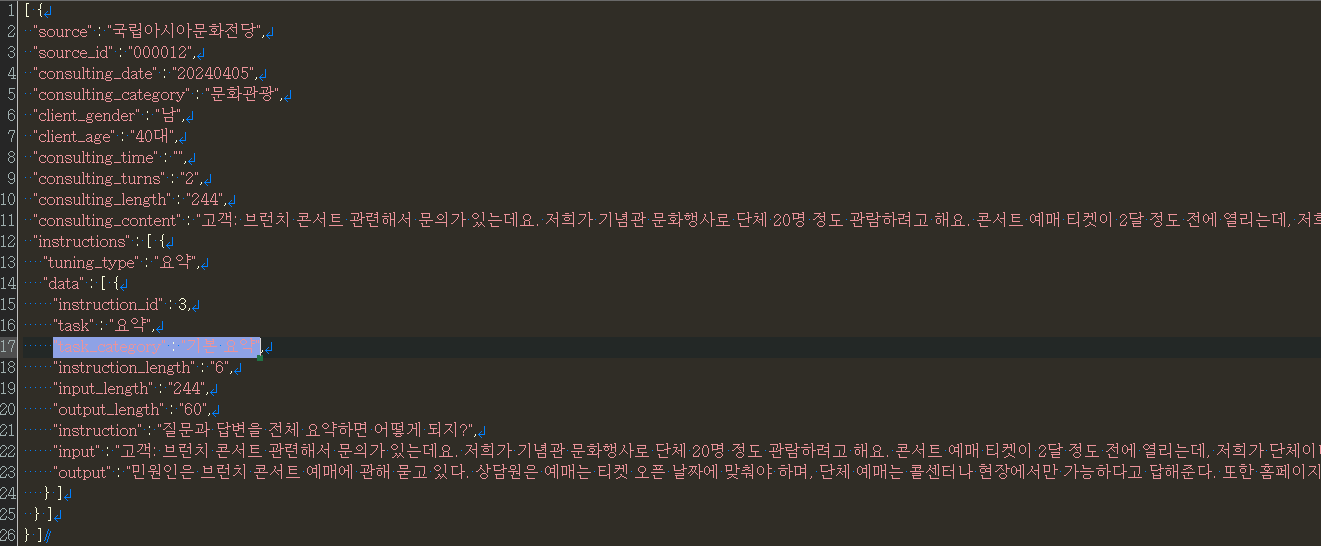
4. 실제 예시
-
데이터셋 구축 담당자
수행기관(주관) : 나라지식정보
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 정규상 02-3141-7644 ksjung@narainformation.com 총괄책임자 수행기관(참여)
수행기관(참여) 기관명 담당업무 디그랩 정제 리스트 수집, 모델링 데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 박분선 02-3141-7644 bspark27@hanmail.net 김희영 02-3141-7644 ahjilu@dgraib.co.kr AI모델 관련 문의처
AI모델 관련 문의처 담당자명 전화번호 이메일 강혁 02-2632-5133 sohohuk@li-st.com 최두 02-2632-5133 codelua@li-st.com 저작도구 관련 문의처
저작도구 관련 문의처 담당자명 전화번호 이메일 강혁 02-2632-5133 sohohuk@li-st.com 최두 02-2632-5133 codelua@li-st.com
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기] [공용IRB 심의신청 가이드라인]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 safezone1@aihub.kr 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.
오프라인 데이터 이용 안내
본 데이터는 K-ICT 빅데이터센터에서도 이용하실 수 있습니다.
다양한 데이터(미개방 데이터 포함)를 분석할 수 있는 오프라인 분석공간을 제공하고 있습니다.
데이터 안심구역 이용절차 및 신청은 K-ICT빅데이터센터 홈페이지를 참고하시기 바랍니다.

국방데이터 개방 안내
본 데이터는 국방데이터로 군사 보안에 따라 AI허브에서 데이터를 제공하지 않으며,
군 담당자를 통한 별도의 사용 신청이 필요합니다.