BETA 한-중/한-일 특허 및 기술과학 분야 병렬 말뭉치 데이터
- 분야지식재산
- 유형 텍스트
-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.0 2024-06-28 데이터 개방 Beta Version 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2024-10-07 산출물 수정 데이터 문의처 수정 2024-06-28 산출물 공개 Beta Version 소개
- 특허 및 기술과학 분야의 인공지능 기계번역 AI모델 기계학습용으로 한국, 중국, 일본 특허공보를 대상으로 구축된 250만 개 병렬 말뭉치 데이터
구축목적
- 특허 및 기술과학 분야의 인공지능 기계번역 모델의 성능 향상을 위한 한국어와 중국어·일본어 간의 AI번역 모델 학습을 위한 양방향 데이터 구축
-
메타데이터 구조표 데이터 영역 지식재산 데이터 유형 텍스트 데이터 형식 csv 데이터 출처 한국특허청(한국특허, 중국특허, 일본특허) 라벨링 유형 번역(자연어) 라벨링 형식 json 데이터 활용 서비스 특허분야 기계번역 서비스, 특허검색 서비스, 특허분석 서비스 데이터 구축년도/
데이터 구축량2023년/원천데이터 7,500,000건, 라벨링 데이터 2,500,000건 -
- 데이터 구축 규모
데이터 구축 규모 데이터 종류 데이터 형태 원문 규모 어노테이션
규모결과물 규모 한-중 특허 및
기술과학 데이터텍스트 100만 건 187.5만 건 62.5만 건 한-일 특허 및
기술과학 데이터텍스트 187.5만 건 62.5만 건 중-한 특허 및
기술과학 데이터텍스트 100만 건 187.5만 건 62.5만 건 일-한 특허 및
기술과학 데이터텍스트 100만 건 187.5만 건 62.5만 건 총계 300만 건 750만 건 250만 건 - 데이터 분포
데이터 분포 구분-1차 구분-2차 구분-3차 구분-4차 원문 건수 비율 한국특허 특허 B kozh (한중) 56,250 9.00% C kozh (한중) 55,000 8.80% F kozh (한중) 20,000 3.20% G kozh (한중) 90,625 14.50% H kozh (한중) 90,625 14.50% 과학기술 EA.기계 kozh (한중) 84,375 13.50% ED.전기전자 kozh (한중) 43,750 7.00% EE.정보통신 kozh (한중) 81,250 13.00% EF.에너지자원 kozh (한중) 21,875 3.50% EG.원자력 kozh (한중) 15,625 2.50% LA.생명과학 kozh (한중) 34,375 5.50% NA.수학 kozh (한중) 15,625 2.50% NB.물리학 kozh (한중) 15,625 2.50% 계 625,000 100% 특허 B koja (한일) 56,250 9.00% C koja (한일) 55,000 8.80% F koja (한일) 20,000 3.20% G koja (한일) 90,625 14.50% H koja (한일) 90,625 14.50% 과학기술 EA.기계 koja (한일) 84,375 13.50% ED.전기전자 koja (한일) 43,750 7.00% EE.정보통신 koja (한일) 81,250 13.00% EF.에너지자원 koja (한일) 21,875 3.50% EG.원자력 koja (한일) 15,625 2.50% LA.생명과학 koja (한일) 34,375 5.50% NA.수학 koja (한일) 15,625 2.50% NB.물리학 koja (한일) 15,625 2.50% 계 625,000 100% 중국특허 특허 B zhko (중한) 56,250 9.00% C zhko (중한) 55,000 8.80% F zhko (중한) 20,000 3.20% G zhko (중한) 90,625 14.50% H zhko (중한) 90,625 14.50% 과학기술 EA.기계 zhko (중한) 84,375 13.50% ED.전기전자 zhko (중한) 43,750 7.00% EE.정보통신 zhko (중한) 81,250 13.00% EF.에너지자원 zhko (중한) 21,875 3.50% EG.원자력 zhko (중한) 15,625 2.50% LA.생명과학 zhko (중한) 34,375 5.50% NA.수학 zhko (중한) 15,625 2.50% NB.물리학 zhko (중한) 15,625 2.50% 계 625,000 100% 일본특허 특허 B jako (일한) 56,250 9.00% C jako (일한) 55,000 8.80% F jako (일한) 20,000 3.20% G jako (일한) 90,625 14.50% H jako (일한) 90,625 14.50% 과학기술 EA.기계 jako (일한) 84,375 13.50% ED.전기전자 jako (일한) 43,750 7.00% EE.정보통신 jako (일한) 81,250 13.00% EF.에너지자원 jako (일한) 21,875 3.50% EG.원자력 jako (일한) 15,625 2.50% LA.생명과학 jako (일한) 34,375 5.50% NA.수학 jako (일한) 15,625 2.50% NB.물리학 jako (일한) 15,625 2.50% 계 625,000 100% 합계 2,500,000 -
-
AI 모델 상세 설명서 다운로드
AI 모델 상세 설명서 다운로드 AI 모델 다운로드- 활용 모델
1. 모델학습 : AI모델 학습은 OpenNMT 프레임워크를 사용하였으며, AIHub의 공개 데이터(한국어-중국어, 한국어-일본어 번역 말뭉치)를 활용하여 기본 AI번역 모델을 생성한 후, ‘23년 구축데이터를 추가 학습하고 검증하는 프로세스로 진행
2. 본 사업을 통해 구축된 학습용 데이터를 학습, 검증, 시험용 데이터(8:1:1)로 구분하여 모델 트레이닝을 실시
활용 모델 구분 학습(Learning) 검증(Validation) 시험(Test) 개요 - OpenNMT 프레임워크 사용
- 내부 트레이닝 서버 사용- AI 모델 트레이닝
시 모델 평가 및
비교
- 모델 정확도 평가- AI모델 학습 종료
후 생성된 모델의
품질을 평가
- BLEU 점수 측정필요 문장 총 데이터의 80% 사용 10% 사용 10% 사용 - 모델학습
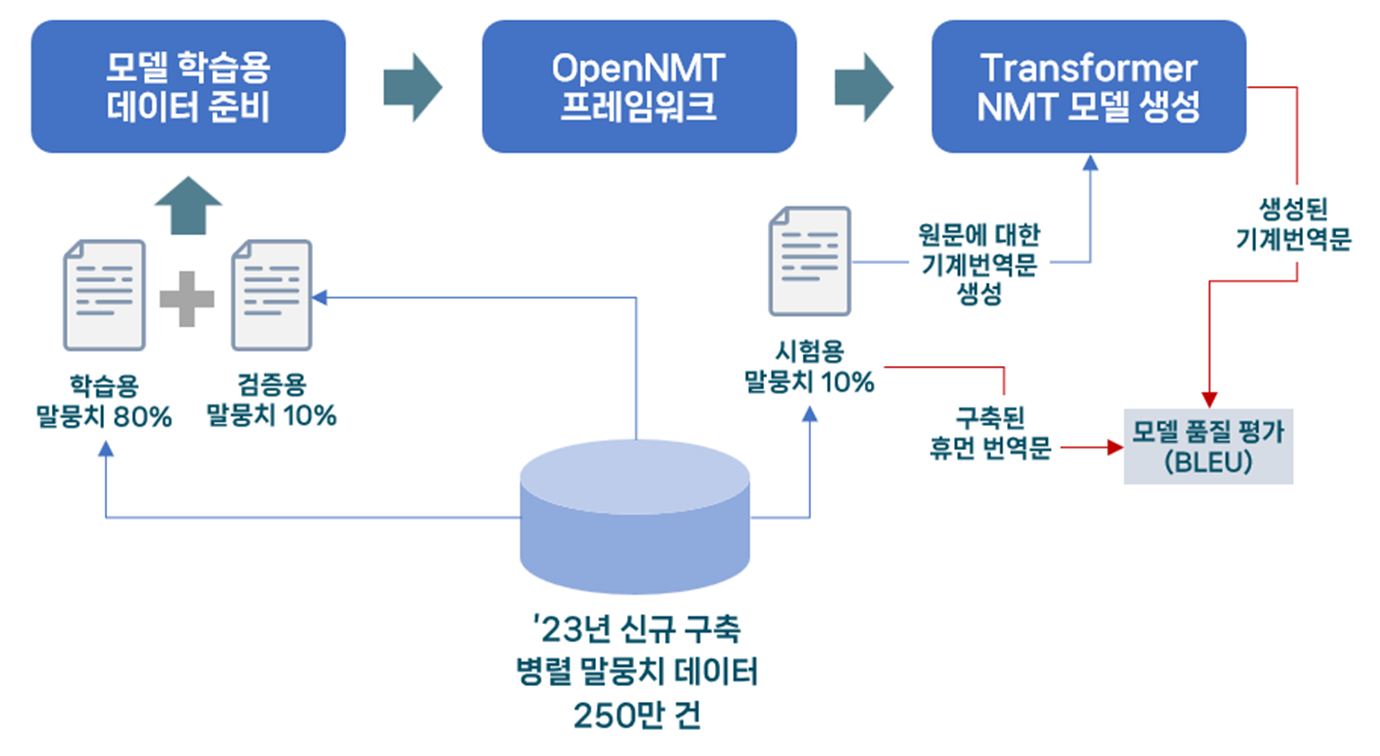
< NMT 학습에 사용되는 학습데이터와 평가방법 >
1. 서비스 활용 시나리오- 빠르게 변하는 글로벌 기술 트렌드에 대응하는 최신 지식 데이터를 학습한 AI번역 모델 구축 및 연구가 필요한 기계번역 전문 기업 및 연구소
*수혜 대상이 되는 기관 및 기업 : (기관) 한국특허청및 산하기관, 국가연구기관, 교육기관 등/ (기업) 특허검색 서비스 제공 기업, 특허 조사 및 분석 기업, AI기술 개발 전문기업, 기업 연구소, 휴먼번역 전문 기업 등- 특허 및 기술과학 분야 용어 및 학습용 번역데이터를 활용한 특화된 AI번역 모델 개발 및 GPT와 같은 초거대 모델의 번역능력 강화 학습에 활용
- 국내외 특허 검색 및 기술 조사 분석 서비스 기업들이 활용하는 특허 및 비특허문서의 번역 품질 향상으로 원시데이터 활용성 증대
- 특허 및 기술과학 문서 휴먼번역 시 번역메모리(Translation Memory)로 활용
-
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드- 데이터 구성
데이터 구성 Key Descipthon Type Child Type { JsonObject corpus 데이터셋 배열 jsonAray [ JsonObject { jsonAray JsonObject source_origin 원문 (문장) Sting words 전문용어 배열 jsonAray [ JsonObject { jsonAray JsonObject src_words 원문용어 Sting tg_words 대역어 Sting } { src_words 원문용어 String tg_words 대역어 String } ] translation_final 최종 검수 번역문 String translation_mt 기계번역문 String translation_1st 1차 가공 번역문 String } ] source 출처 String classification 데이터 분류 String country_code 국가코드 String cpc_code 대표 CPC 코드 String license 라이선스 String filename 원시데이터 파일명 String src_lang_code 원문 언어 코드 String app_date 출원년도 String sc_code 과학기술분류 코드 String app_num 출원번호 String id 구분코드 String tg_lang_code 번역문 언어 코드 String ipc_code 대표 IPC 코드 String } - 어노테이션 포맷
어노테이션 포맷 No. 항목 길이 타입 필수
여부비고 한글명 영문명 1 데이터셋 정보 { JsonObject Y 1-1 데이터셋 배열 corpus jsonAray Y 2 [ JsonObject Y 2-1 { jsonAray Y 2-2 원문 (문장) source_origin Sting Y 2-3 전문용어 배열 words jsonAray Y 3-1 [ JsonObject Y 3-2 { jsonAray Y 3-3 원문용어 src_words Sting Y 3-4 대역어 tg_words Sting Y } Y { Y 3-5 원문용어 src_words String Y 3-6 대역어 tg_words String Y } Y ] Y 2-4 최종 검수 번역문 translation_final String Y 2-5 기계번역문 translation_mt String Y 2-6 1차 가공 번역문 translation_1st String N } Y ] Y 2-7 출처 source String Y 2-8 데이터 분류 classification String Y 2-9 국가코드 country_code String Y KR or CN
or JP2-10 대표 CPC 코드 cpc_code String Y 2-11 라이선스 license String Y 2-12 원시데이터 파일명 filename String Y 2-13 원문 언어 코드 src_lang_code String Y 2-14 출원년도 app_date String Y YYYY 2-15 과학기술분류 코드 sc_code String N 2-16 출원번호 app_num String Y 2-17 구분코드 id String Y 2-18 번역문 언어 코드 tg_lang_code String Y 2-19 대표 IPC 코드 ipc_code String Y } Y - 데이터 포맷 예시
데이터 포맷 예시 항목 내용 구분코드 jp_03_001_03_009918330 국가코드 JP 원시데이터 파일명 2021175661.xml 데이터 분류 특허 출원년도 2021 출원번호 2021075145 대표 IPC 코드 B64C 11/04 대표 CPC 코드 과학기술분류 코드 원문 언어 코드 ja 번역문 언어 코드 ko 원문 空中乗物は、その翼に搭載された回転翼及びプロペラの、異な
る形態を使用して、全ての飛行モードにおける抗力を減少させ
る。초벌 기계번역문 공중승물은, 그 날개에 탑재된 회전날개 및 프로펠러의, 다른
형태를 사용하여, 모든 비행 모드에 있어서의 항력을
감소시킨다.1차 가공문 공중승물은, 그 날개에 탑재된 회전 날개 및 프로펠러의
상이한 형태를 사용하여 모든 비행 모드에 있어서의 항력을
감소시킨다.최종 번역문 공중비행체는 그 날개에 탑재된 회전 날개 및 프로펠러의
상이한 형태를 사용하여 모든 비행 모드에서의 항력을
감소시킨다.전문용어1(원문) 空中乗物 전문용어1(번역문) 공중비행체 전문용어2(원문) プロペラ 전문용어2(번역문) 프로펠러 출처 JPO 라이선스 공개 라이선스 - 실제 예시
실제 예시 {
"corpus" : [ {
"source_origin" : "空中乗物は、その翼に搭載された回転翼及びプロペラの、異なる形態を使用して、全ての飛行モードにおける抗力を減少させる。",
"words" : [ {
"src_words" : "空中乗物",
"tg_words" : "공중비행체"
}, {
"src_words" : "プロペラ",
"tg_words" : "프로펠러"
} ],
"translation_final" : "공중비행체는 그 날개에 탑재된 회전 날개 및 프로펠러의 상이한 형태를 사용하여 모든 비행 모드에서의 항력을 감소시킨다.",
"translation_mt" : "공중승물은, 그 날개에 탑재된 회전날개 및 프로펠러의, 다른 형태를 사용하여, 모든 비행 모드에 있어서의 항력을 감소시킨다.",
"translation_1st" : "공중승물은, 그 날개에 탑재된 회전 날개 및 프로펠러의 상이한 형태를 사용하여 모든 비행 모드에 있어서의 항력을 감소시킨다."
} ],
"source" : "JPO",
"classification" : "특허",
"country_code" : "JP",
"cpc_code" : "",
"license" : "공개 라이선스",
"filename" : "2021175661.xml",
"src_lang_code" : "ja",
"app_date" : "2021",
"sc_code" : "",
"app_num" : "2021075145",
"id" : "jp_03_001_03_009918330",
"tg_lang_code" : "ko",
"ipc_code" : "B64C 11/04"
} -
데이터셋 구축 담당자
수행기관(주관) : ㈜ 시스트란
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 김호경 042-472-6840 Hoyoung.Kim@systrangroup.com 사업총괄, 원시데이터 수집, 원천데이터 정제, 데이터 가공 프로세스 관리(저작도구 지원), AI모델 개발, 품질관리 등 수행기관(참여)
수행기관(참여) 기관명 담당업무 ㈜렉스코드 데이터 가공 및 품질 ㈜솔트룩스이노베이션 데이터 가공 및 품질 ㈜트위그팜 데이터 가공 및 품질 ㈜플리토 데이터 가공 및 품질 데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 이동호 042-472-6840 dongho.lee@systrangroup.com AI모델 관련 문의처
AI모델 관련 문의처 담당자명 전화번호 이메일 지용훈 042-472-6840 yonghoon.ji@systrangroup.com 저작도구 관련 문의처
저작도구 관련 문의처 담당자명 전화번호 이메일 이동호 042-472-6840 dongho.lee@systrangroup.com
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기] [공용IRB 심의신청 가이드라인]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 safezone1@aihub.kr 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.