-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.0 2024-06-28 데이터 개방 Beta Version 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2024-06-28 산출물 공개 Beta Version 소개
- 동화 구성 및 내용에 적절한 그림 삽화를 손쉽게 제공하기 위한 동화 이미지 (이미지 변환) 및 텍스트 데이터, 이미지 캡션 데이터
구축목적
- 동화를 기반으로, 인공지능 학습용 데이터 구축 개방을 통한 문화, 출판, 교육, 분야에 디지털대전 생태계 조성 및 일상화 실현
-
메타데이터 구조표 데이터 영역 문화관광 데이터 유형 텍스트 , 이미지 데이터 형식 JPG, JSON 데이터 출처 어린이 동화, 소설 라벨링 유형 텍스트-이미지쌍(이미지/자연어) 라벨링 형식 JPG, JSON 데이터 활용 서비스 대규모 동화 삽화 생성 데이터를 구축하여 대화형 챗봇 서비스, AI 오디오북, IPTV 등 유아콘텐츠 기반 대화형 서비스 제공 등 데이터 구축년도/
데이터 구축량2023년/50,001 -
- 데이터 구축 규모
데이터명 데이터 형태 원문 규모 어노테이션
규모결과물 규모 추출 요약 생성요약 009-014
동화 삽화 생성 데이터이미지, 텍스트 50,000건 50,001건 59,342건
(3문장 추출)50,001건
(1문장 생성)
- 데이터 분포
- 콘텐츠 분류(어린이용 동화, 소설 도서 누리과정 5개 영역)
- 교육부 2022년 누리과정 5개 분류 및 수업 시간 비율로 분포 산정분류 체계 도서 분배율 계획 유아 초등(참고) 의사소통 국어 27% 영어 자연탐구 수학 37% 과학 사회관계 사회 18% 도덕 예술경험 음악 9% 미술 신체운동/건강 체육 9% - 출판사 도서 통계를 기준으로 유아의 경우 스토리당 평균 단락 수 20개, 초등 저학년의 경우 단락 수 평균 40개, 초등 고학년의 경우 단락 수 평균 70개를 기준으로 분류 비율 산정
구분 유아 초등저학년 초등고학년 단락 수 분포 50% 25% 25% - 줄거리 유형 (2가지)
1) 지시문: 핵심용어를 2개 이상 포함하여 이미지를 설명하는 문장으로 작성
2) 발화문: 핵심용어를 2개 이상 포함하여 이미지를 기준으로 사람이 말하는 문장으로 작성* 핵심용어: FairytaleQA Paris & Paris(2003)의 7가지 프로토콜인 인물, 행동, 배경, 감정, 인과, 해결, 예측을 기준으로 선정
-
-
AI 모델 상세 설명서 다운로드
AI 모델 상세 설명서 다운로드 AI 모델 다운로드- 모델 선정 및 개발 관련
- Latent Diffusion Model(LDM) 또는 Stable Diffusion(https://arxiv.org/abs/2112.10752)은 2022년 CVPR이라는 인공지능 및 컴퓨터비전 분야 최상위 학술대회에서 발표된 방법론으로 최근 확산(Diffusion) 모델 기반 영상 생성 기술에서 가장 널리 활용되고 있는 기술 중 하나임
- 기본적으로 확산(Diffusion) 모델은 생성 재현 퀄리티(Fidelity)가 아주 우수하고 생성된 이미지의 다양성(Diversity)이 아주 뛰어난 모델로 알려져 있고, 이는 기존 Generative Adver sarial Networks(GANs)에 비해 그 성능과 확장성이 매우 뛰어나다고 알려져 있음
- 하지만 이러한 확산 기반 생성 모델은 학습 속도와 생성 속도가 매우 느림
- 이를 극복하기 위하여 LDM 기술은 영상을 Latent Space로 Embedding 시키고 이 Space에서 Diffusion 모델을 학습함으로써 학습 속도와 생성 속도를 모두 개선하였음
- 또한 LDM은 기 학습된(Pre-trained) 모델을 공개한 거의 유일한 모델이기 때문에 전이학습(Transfer Learning) 등으로 파인 튜닝하여 활용 가능함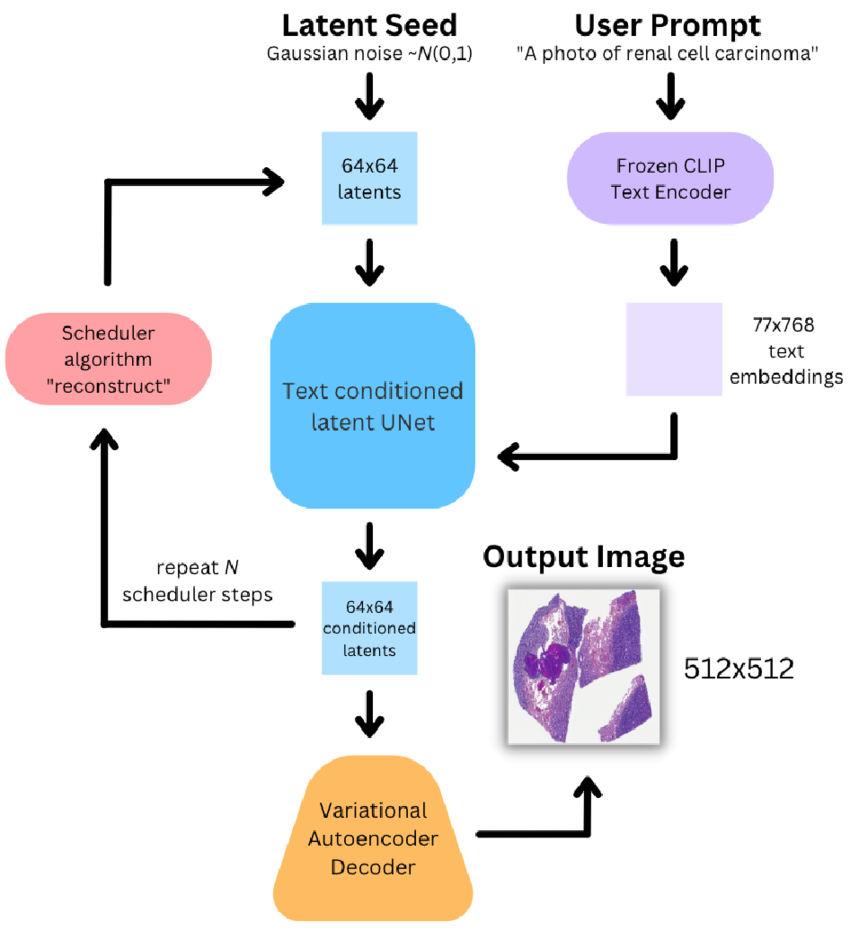
[LDM 모델의 논리적인 작업 흐름도]
- LDM의 경우 CLIP 모델에서 영어 텍스트를 기본으로 하여 영어 텍스트와 이미지의 Latent Vector를 정합하였기 때문에, 추가적으로 한국어 텍스트를 이용하여 텍스트와 이미지의 Latent Vector 정합을 위한 파인 튜닝 과정이 필요함
(1) 베이스 모델로 현재 공개된 LDM pretrained 모델(https://stablediffusionweb.com/) 사용
(2) 텍스트 인코더 Korean CLIP으로 수정(https://huggingface.co/Bingsu/my-korean-stable-diffusion-v1-5)
(3) 구축된 데이터를 LORA(https://huggingface.co/blog/lora)를 통해서 파인 튜닝을 진행- 유효성 검증 방법
- 유효성 검증의 경우 FID score와 IS(Inception Score)를 활용하여 정량적으로 평가함
- FID Score는 실제 이미지와 생성된 이미지 간의 특징 거리 측정에 가장 널리 사용되는 매트릭 중 하나로, 프레쳇 거리(Frechet Distance)는 곡선을 따라는 점들(points)의 위치와 순서를 고려한 곡선 간의 유사성을 측정하는 방법임. 이는 두 분포 사이의 거리를 측정하는 데에도 사용됨
- IS(Inception Score) 메트릭은 Google의 "Inception" 이미지 분류 네트워크를 기반으로 다음의 2가지 분포를 이용해 생성된 이미지에 대해 0(최악)에서 무한대(최상)까지의 범위로 점수를 측정함
1. 확률 분포(probability distribution) : 생성된 이미지에 하나의 잘 정의된 항목이 포함되어 있는지, 또는 이미지 분류 모델이 식별하기 어려운 일련의 항목이 포함되어 있는지 확인하여 이미지 품질을 측정함
2. 주변 분포(marginal distribution) : 생성된 모든 이미지에 대한 확률 분표를 비교하여 하나의 객체가 얼마나 다양하게 표현되는가를 측정함. 즉, 하나의 객체의 집중 분포(focused distribution. 하나의 객체로 구분 가능한 이미지의 수)와 모든 객체의 균등 분포(uniform distributuon. 모든 객체의 각각의 이미지 수)를 표시하여, 하나의 객체가 얼마나 다양하게 표시될 수 있는지에 대한 분포를 도출함으로써 이미지의 다양성을 측정함
- FID score 지표는 이미지 생성 모델의 성능을 평가하는 데 특히 유용함. 이미지 생성 모델은 텍스트의 정보를 기반으로 새로운 이미지를 생성하므로, 생성된 이미지의 내용이 텍스트의 내용과 완벽하게 일치하지 않을 수 있음. 이런 경우에도 FID score를 통해 이미지의 품질을 공정하게 평가할 수 있음
- 한편, FID score와는 다른 관점으로 이미지의 품질과 다양성을 판단하는 IS(Inception Score)를 활용함. FID score가 원본 이미지와 생성 이미지의 차이의 분포로 평가하는 반면, IS는 생성된 이미지 데이터로 품질과 다양성을 평가함 -
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드- 데이터 구성
데이터 항목 설명 도서명 ● 도서의 제목 글 저자 ● 글 작가 이름 이미지 작가 ● 그림 작가 이름 ISBN ● 도서 출간 정보, 납본 여부 확인 출간년도 ● 도서의 출판년도 출판사명 ● 출간 출판사 책내 삽화 개수 ● 도서에 있는 삽화 개수 책내 단락 개수 ● 도서에 있는 단락 개수 5개 주제 분류 ● 누리교육과정 5개 분류 사용
- 의사소통, 자연탐구, 사회관계, 예술경험, 신체운동/건강
- 누리(유치원)과정 행정규칙 교육부 고시
제2019-152호 2019 개정 누리과정 고시문독서연령 ● 아동 발달단계 기준 3개 분류(응답자군 레벨과 매칭)
- 유아 만 4~6세(1)
- 초등학교저학년 만 7~9세(2)
- 초등학교고학년 만 10~12세(3)
- 어노테이션 포맷구분 속성명 타입 필수 여부 설명 비고 1 title string Y 도서명 2 author string Y 저자 3 illustrator string Y 이미지 작가 4 isbn string Y ISBN 도서 식별 넘버 5 publishedYear number N 출간년도 6 publisher string N 출판사명 7 imageInfoCount number Y 책내 삽화 개수 8 paragraphInfoCount number N 책내 단락 개수 9 imageInfo array Y 이미지 정보 9-1 srcTextID string Y 단락 식별코드 9-2 srcText string Y 단락 텍스트 9-3 srcPage number Y 단락 페이지 정보 9-4 srcSententsEA number Y 단락 문장 수 9-5 srcWordEA number Y 단락 어절 수 9-6 character string N 핵심용어1(캐릭터) 9-7 setting string N 핵심용어2(셋팅) 9-8 action string N 핵심용어3(액션) 9-9 feeling string N 핵심용어4(감정) 9-10 causalRelationship string N 핵심용어5(인과) 9-11 outcomeResolution string N 핵심용어6(결과) 9-12 prediction string N 핵심용어7(예측) 9-13 srcImageFile string Y 이미지 파일명 9-14 srcImagePath string Y 이미지 파일경로 9-15 srcImageS string Y 해상도 9-16 srcImageQ number Y 이미지 파일용량 9-17 entityCount number Y entity 개수 9-18 entity array Y 그림내의 객체배열 9-18-1 name string Y 객체의 일반명사 9-18-2 i_action string Y 객체의 행동, 상태 9-18-3 position string Y 객체의 위치 "왼쪽상단","왼쪽중앙","왼
쪽하단","가운데상단","정
중앙","가운데하단","우측
상단","우측중앙","우측하 단"9-19 imageCaptionInfo object Y 이미지 캡션 정보 9-19-1 classification string Y 주제 “의사소통”,“자연탐구 ”,“사회관계”,“예술경
험”,“신체운동_건강”9-19-2 readAge string Y 독서연령 “유아”,“초등_저학년”,
“초등_고학년”9-19-3 imageCaption string Y 이미지 캡션 9-19-4 utteranceOpt string Y 지시문 발화문 “RUBRIC”,“UTTERANC
E”9-19-5 captionWordEA number Y 캡션의 어절수 9-19-6 captionSyllableEA number Y 캡션의 음절수
- 데이터 포맷
- 원문데이터 포맷 화면 예시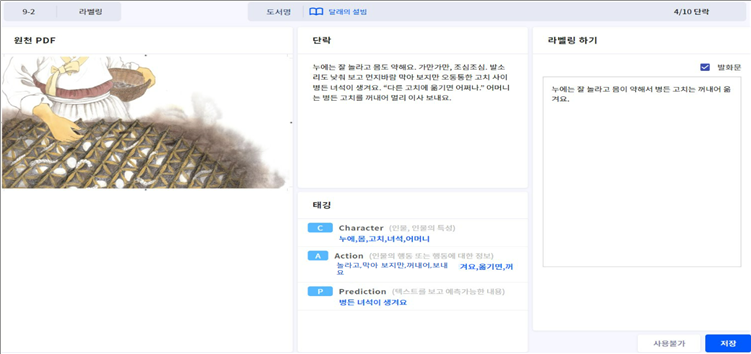
- 실제 예시
- 원천 및 라벨링 데이터(JPG)
- 원천 및 라벨링 데이터(JSON)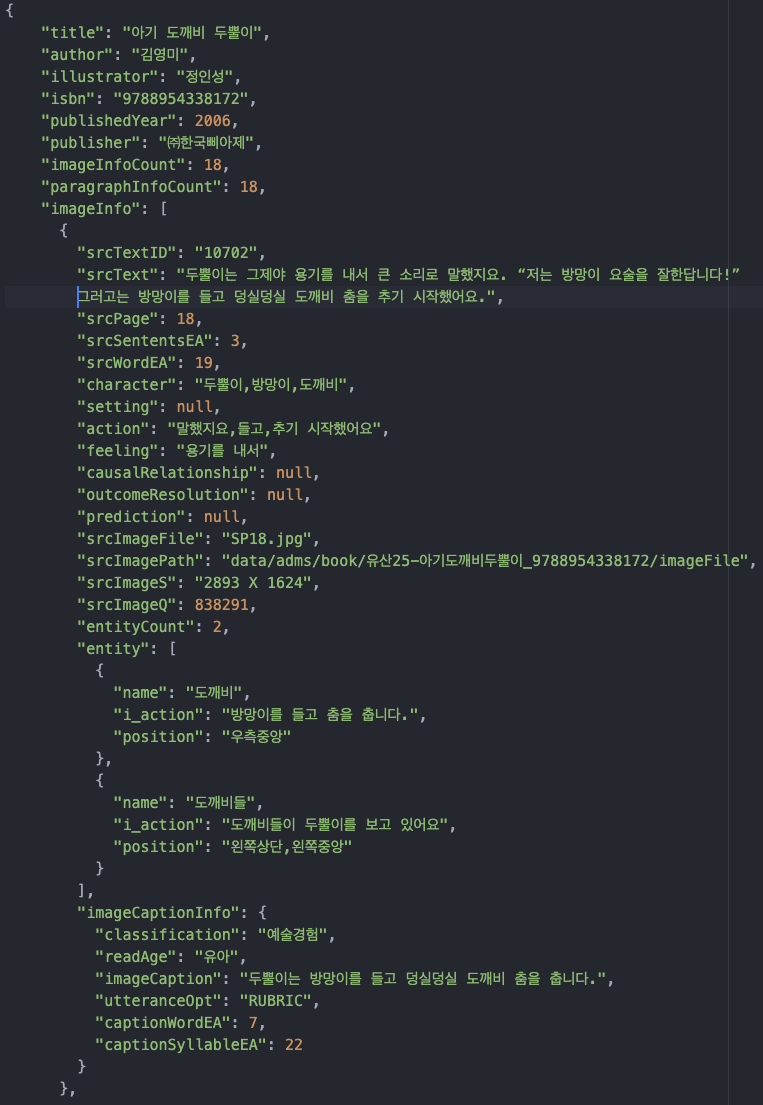
-
데이터셋 구축 담당자
수행기관(주관) : ㈜미니게이트
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 황지영 070-4088-0143 hwang@minigate.net 실무총괄 수행기관(참여)
수행기관(참여) 기관명 담당업무 ㈜아람키즈 데이터 획득/수집 ㈜아이피아 데이터 검수 및 AI학습 데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 황지영 070-4088-0143 hwang@minigate.net AI모델 관련 문의처
AI모델 관련 문의처 담당자명 전화번호 이메일 최재우 070-4088-0103 jw.choi@aipia.co.kr 저작도구 관련 문의처
저작도구 관련 문의처 담당자명 전화번호 이메일 박귀숙 070-9098-9155 gspark@minigate.net
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기] [공용IRB 심의신청 가이드라인]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 safezone1@aihub.kr 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.