회의 음성
- 분야한국어
- 유형 오디오 , 텍스트
-
데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.1 2021-09-09 데이터 보완 데이터 품질 보완 1.0 2021-06-25 데이터 개방 데이터 최초 개방 데이터 히스토리
데이터 히스토리 일자 변경내용 비고 2022-10-17 샘플데이터 개방 신규 샘플데이터 개방 소개
한국어로 된 회의영상/음성을 인식하여 자동으로 자막을 생성해주고, 내용을 이해하는 한국어 회의 음성 데이터
- 데이터 영역 : 한국어
- 데이터 유형 : 오디오 , 텍스트
- 구축년도 : 2020년
- 구축량 : 432만
구축목적
한국인의 음성을 문자로 바꾸어 주고, 문맥을 이해하는 한국어 음성 언어처리 기술 개발을 위한 AI 학습용 한국어 음성 DB를 구축 한국어로 된 회의 영상/음성을 인식하여 자동으로 자막/회의록을 생성해주고, 내용을 이해하는 서비스를 위한 한국어 회의 음성 DB를 구축
-
구축 내용 및 제공 데이터량
구축 내용 및 제공 데이터량 구분 회의 음성 데이터 시간(hr) 3,000 데이터 선정 기준 교육, 문화예술, 가족 (400시간 X 3개분야 = 1,200시간)
교양, 시사 (550시간 X 2개분야 = 1,100시간)
토크 300시간
금융, IT (200시간 X 2개분야 = 400시간)수집항목 회의(토론/토크) 음성, 장르, 발화자 성별, 회의정보(방송날짜) 등 -
-
데이터 성능 점수
측정값 (%)기준값 (%)데이터 성능 지표
데이터 성능 지표 번호 측정항목 AI TASK 학습모델 지표명 기준값 점수 측정값 점수 1 한국어 강의 학습 성능 Speech Recognition Jasper CER 15 % 12.79 % 2 한국어 강의 학습 성능 Speech Recognition Jasper WER 38 % 31.51 %
※ 데이터 성능 지표가 여러 개일 경우 각 항목을 클릭하면 해당 지표의 값이 그래프에 표기됩니다.
※ AI모델 평가 지표에 따라 측정값의 범위, 판단 기준이 달라질 수 있습니다. (ex. 오류율의 경우, 낮을수록 좋은 성능을 내는 것으로 평가됩니다)
-
설명서 및 활용가이드 다운로드
데이터 설명서 다운로드 구축활용가이드 다운로드데이터 변경이력
데이터 변경이력 버전 일자 변경내용 비고 1.1 2021.09.09 데이터 품질 보완 1.0 2021.06.25 데이터 최초 개방 구축 목적
- 한국인의 음성을 문자로 바꾸어 주고, 문맥을 이해하는 한국어 음성 언어처리 기술 개발을 위한 AI 학습용 한국어 음성 DB를 구축
- 한국어로 된 회의 영상/음성을 인식하여 자동으로 자막/회의록을 생성해주고, 내용을 이해하는 서비스를 위한 한국어 회의 음성 DB를 구축
활용 분야
- 연구분야: 음성인식, 음성언어처리, 자연어처리, 한국어 음성언어연구, 신호처리 등
- 산업분야: 온/오프라인 기반의 음성인식, 회의 대화록 자동생성
소개
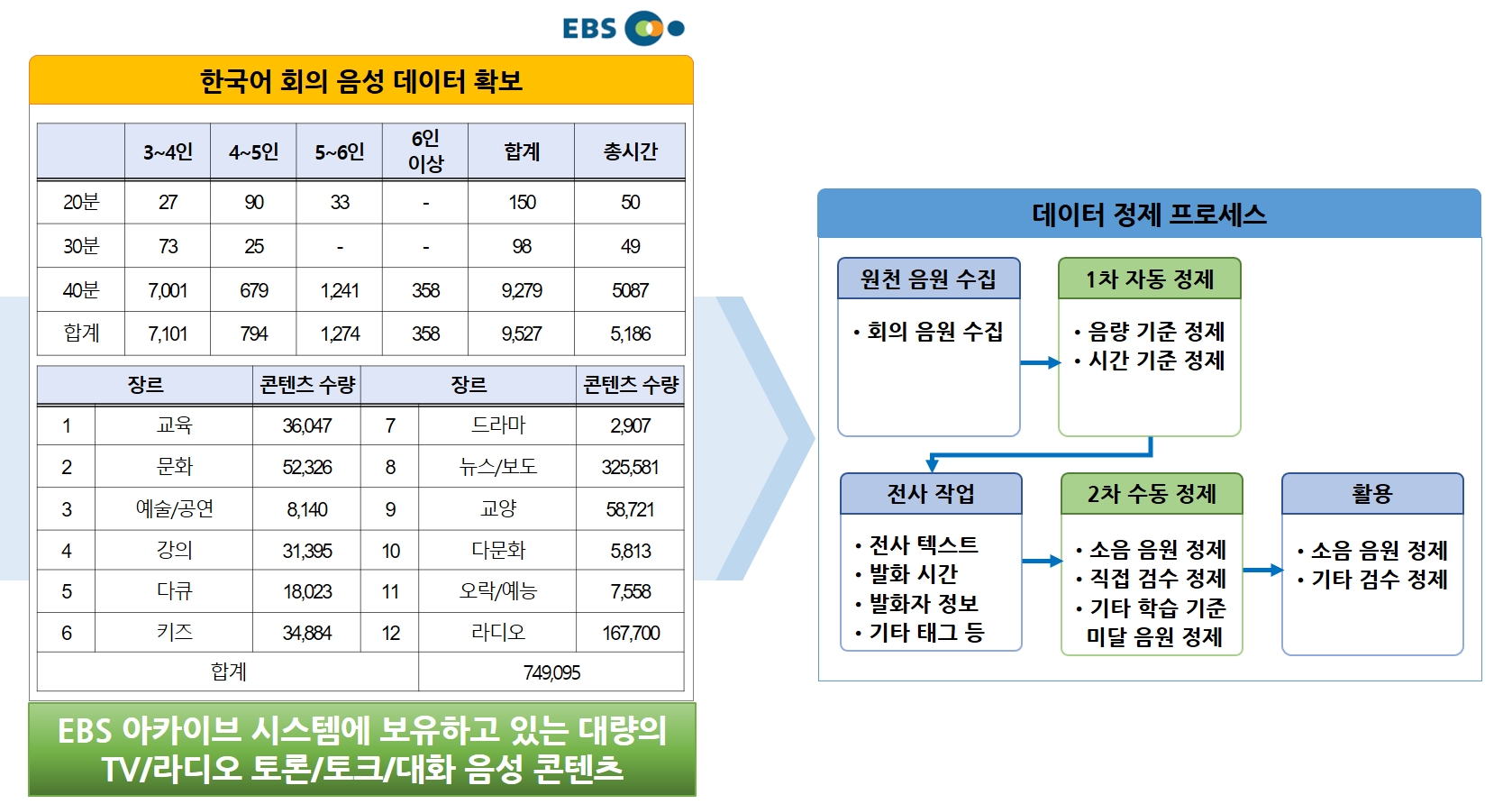
- 8가지 주제별 다양한 한국어 회의 음성으로부터 음성의 내용을 전사하고 검증한 한국어 회의 음성 AI 데이터셋으로, 다양한 음성의 재사용에 제한이 없도록 저작권 문제를 완전히 해결한 원천 데이터를 확보
구축 내용 및 제공 데이터량
구축 내용 및 제공 데이터량 구분 회의 음성 데이터 시간(hr) 3,000 데이터 선정 기준 교육, 문화예술, 가족 (400시간 X 3개분야 = 1,200시간)
교양, 시사 (550시간 X 2개분야 = 1,100시간)
토크 300시간
금융, IT (200시간 X 2개분야 = 400시간)수집항목 회의(토론/토크) 음성, 장르, 발화자 성별, 회의정보(방송날짜) 등 대표도면
필요성
- 최근 AI를 활용한 음성인식 기술이 인공지능 비서를 포함한 다양한 서비스에 적용되고 있음
- 하지만 AI 음성인식 모델이 회의 음성 데이터로 학습이 이루어지지 않을 경우, 회의에서 발생하는 다양한 노이즈 및 화자 간 목소리가 겹치는 등의 문제로 음성인식 성능이 떨어지는 경향을 보임
- 회의 데이터는 회의 참여자 간의 민감한 정보를 다루는 경우가 많아 외부 유출이 가능한 경우가 드물어 데이터셋 구축에 어려움이 있음
데이터 구조
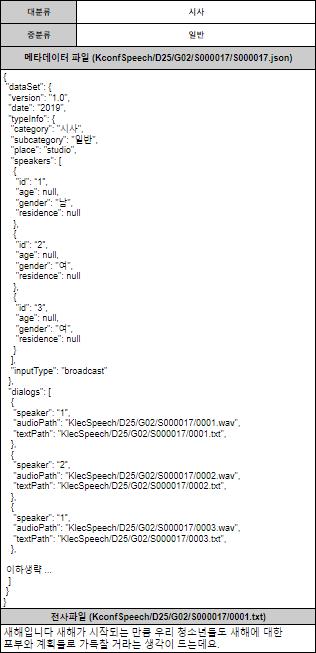
데이터 구조 ID 항목 타입 키 명 키 설명 dataSet 데이터셋 Dict 1 version 데이터셋 버전 String 3 date 녹취된 날짜 String 4 typeInfo 음원 데이터 상세 정보 Dict 4-1 category 음원 카테고리 정보 String 4-2 subcategory 음원 서브카테고리 String 4-3 place 음원 녹취 장소 String 4-4 speakers 화자 목록 List 4-3-1 id 화자 아이디 String 4-3-1 age 나이대: 20대, 30대, 50대(추정), null(알수없음) 등 4-3-2 gender 화자 성별: 남, 여 String 4-3-2 residence 거주지역: 서울, 대전, 부산, 광주, null(알수없음) 등 4-5 inputType 입력형식:
방송, 유선, 모바일, 인터넷 등List 5 dialogs 전사 데이터 목록:
묵음 기준으로 나누어진 발화 단위로 생성List 5-1 speaker 화자 아이디: speakers에 등록된 id String 5-2 audioPath 발화 단위 RAW 데이터 경로 String 5-3 textPath 발화 단위 TEXT 데이터 경로 String -
데이터셋 구축 담당자
수행기관(주관) : 티맥스소프트
수행기관(주관) 책임자명 전화번호 대표이메일 담당업무 김윤성 031-8018-9325 kimys130907@gmail.com · 데이터구축 총괄 · 데이터 수집 · 데이터 정제 · 데이터 가공 · AI모델개발 · 응용서비스 개발 수행기관(참여)
수행기관(참여) 기관명 담당업무 ㈜아이스크림에듀 · 데이터 수집
· 데이터 정제
· 데이터 가공나무기술(주) · 품질검증 (사)한국에듀테크산업협회 · 데이터 수집
· 데이터 정제
· 데이터 가공데이터 관련 문의처
데이터 관련 문의처 담당자명 전화번호 이메일 박윤수(티맥스소프트) 031-8081-9398 yoonsu_park@tmax.co.kr
-
인터넷과 물리적으로 분리된 온라인·오프라인 공간으로 의료 데이터를 포함하여 보안 조치가 요구되는 데이터를 다운로드 없이 접근하고 분석 가능
* 온라인 안심존 : 보안이 보장된 온라인 네트워크를 통해 집, 연구실, 사무실 등 어디서나 접속하여 데이터에 접근하고 분석
* 오프라인 안심존 : 추가적인 보안이 필요한 데이터를 대상으로 지정된 물리적 공간에서만 접속하여 데이터에 접근하고 분석 -
- AI 허브 접속
신청자 - 안심존
사용신청신청자신청서류 제출* - 심사구축기관
- 승인구축기관
- 데이터 분석 활용신청자
- 분석모델반출신청자
- AI 허브 접속
-
1. 기관생명윤리위원회(IRB) 심의 결과 통지서 [IRB 알아보기] [공용IRB 심의신청 가이드라인]
2. 기관생명윤리위원회(IRB) 승인된 연구계획서
3. 신청자 소속 증빙 서류 (재직증명서, 재학증명서, 근로계약서 등 택1)
4. 안심존 이용 신청서 [다운로드]
5. 보안서약서 [다운로드]
※ 상기 신청서 및 첨부 서류를 완비한 후 신청을 진행하셔야 정상적으로 절차가 이루어집니다. -
신청 및 이용관련 문의는 safezone1@aihub.kr 또는 02-525-7708, 7709로 문의
데이터셋 다운로드 승인이 완료 된 후 API 다운로드 서비스를 이용하실 수 있습니다.
API 다운로드 파일은 분할 압축되어 다운로드 됩니다. 분할 압축 해제를 위해서는 분할 압축 파일들의 병합이 필요하며 리눅스 명령어 사용이 필요합니다.
리눅스 OS 계열에서 다운로드 받으시길 권장하며 윈도우에서 파일 다운로드 시 wsl(리눅스용 윈도우 하위 시스템) 설치가 필요합니다.
※ 파일 병합 리눅스 명령어
find "폴더경로" -name "파일명.zip.part*" -print0 | sort -zt'.' -k2V | xargs -0 cat > "파일명.zip"
- 해당 명령어 실행 시, 실행 경로 위치에 병합 압축 파일이 생성됩니다.
- 병합된 파일 용량이 0일 경우, 제대로 병합이 되지 않은 상태이니 "폴더경로"가 제대로 입력되었는지 확인 부탁드립니다.
※ 데이터셋 소개 페이지에서 다운로드 버튼 클릭하여 승인이 필요합니다.
오프라인 데이터 이용 안내
본 데이터는 K-ICT 빅데이터센터에서도 이용하실 수 있습니다.
다양한 데이터(미개방 데이터 포함)를 분석할 수 있는 오프라인 분석공간을 제공하고 있습니다.
데이터 안심구역 이용절차 및 신청은 K-ICT빅데이터센터 홈페이지를 참고하시기 바랍니다.

국방데이터 개방 안내
본 데이터는 국방데이터로 군사 보안에 따라 AI허브에서 데이터를 제공하지 않으며,
군 담당자를 통한 별도의 사용 신청이 필요합니다.